
Python 3.11比3.10 快60%:使用冒泡排序和递归函数对比测试

来源:DeepHub IMBA 本文共1300字,建议阅读5分钟 本文验证Python 3.11的性能优化。
安装Python 3.11 pre-release
sudo apt install Python3.11
$ virtualenv env10 --python=3.10$ virtualenv env11 --python=3.11# To activate v11 you can run,$ source env11/bin/activate
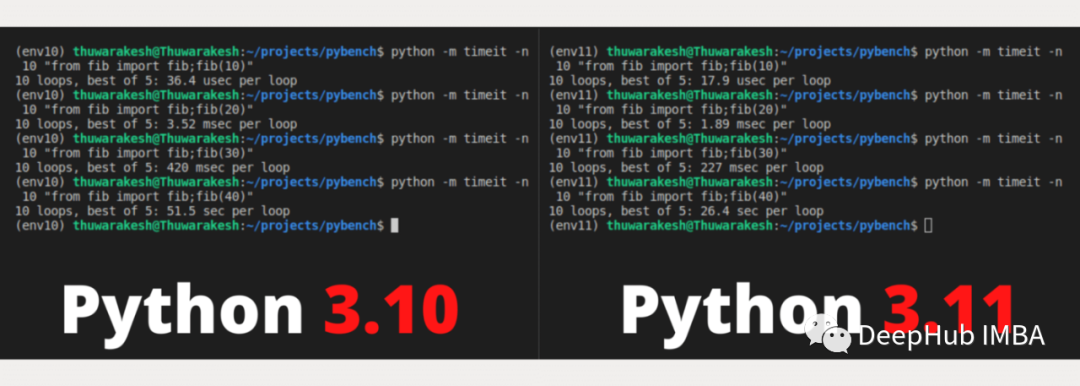
Python 3.11 与 Python 3.10 相比有多快?
def fib(n: int) -> int:return n if n < 2 else fib(n - 1) + fib(n - 2)
# To generate the (n)th Fibonacci numberpython -m timeit -n 10 "from fib import fib;fib(n)"
冒泡排序
import randomfrom timeit import timeitfrom typing import Listdef bubble_sort(items: List[int]) -> List[int]:n = len(items)for i in range(n - 1):for j in range(0, n - i - 1):if items[j] > items[j + 1]:items[j], items[j + 1] = items[j + 1], items[j]numbers = [random.randint(1, 10000) for i in range(1000000)]print(timeit(lambda:bubble_sort(numbers),number=5))

I/O 操作是否存在性能差异?
from timeit import timeitstatement = """for i in range(100000):with open(f"./data/a{i}.txt", "w") as f:f.write('a')"""print(timeit(statement, number=10))
from glob import globfrom timeit import timeitfile_paths = glob("./data/*.txt")statement = f"""for path in {file_paths}:with open(path, "r") as f:f.read()"""print(timeit(statement, number=10))

总结
评论