
Anchor-free目标检测综述—细数10种Dense Prediction网络

极市导读
anchor-free目标检测算法分为两种:一种是DenseBox为代表的Dense Prediction类型,密集地预测的框的相对位置,另一种则是以CornerNet为代表的Keypoint-bsaed Detection类型,以检测目标关键点为主。本文主要列举10种Dense Prediction类型的网络。>>加入极市CV技术交流群,走在计算机视觉的最前沿
早期目标检测研究以anchor-based为主,设定初始anchor,预测anchor的修正值,分为two-stage目标检测与one-stage目标检测,分别以Faster R-CNN和SSD作为代表。后来,有研究者觉得初始anchor的设定对准确率的影响很大,而且很难找到完美的预设anchor,于是开始不断得研究anchor-free目标检测算法,意在去掉预设anchor的环节,让网络自行学习anchor的位置与形状,在速度和准确率上面都有很不错的表现。anchor-free目标检测算法分为两种,一种是DenseBox为代表的Dense Prediction类型,密集地预测的框的相对位置,另一种则是以CornerNet为代表的Keypoint-bsaed Detection类型,以检测目标关键点为主。
本文主要列举几种Dense Prediction类型的网络,主要涉及以下网络:
YOLO DenseBox Guided Anchoring FSAF FCOS FoveaBox SAPD ATSS FCOSv2 DDBNet
YOLO
YOLOv1是早期的anchor-free算法,后来的系列则转型成anchor-based算法。YOLO同时对多个物体进行分类和定位,没有proposal的概念,是one-stage实时检测网络的里程碑,标准版在TitanX达到45 fps,快速版达到150fps,但精度不及当时的SOTA网络。
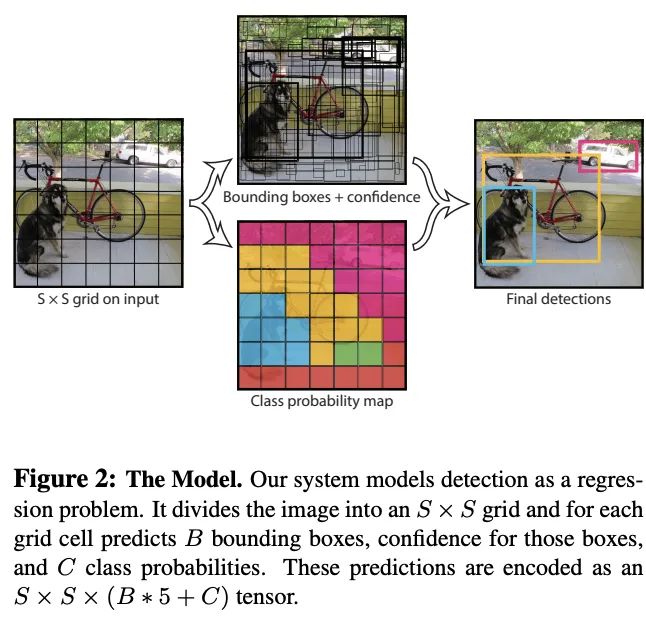
将输入分为的格子,如果GT的中心点在格子中,则格子负责该GT的预测:
每个格子预测个bbox,每个bbox预测5个值: 和置信度,分别为中心点坐标和bbox的宽高,中心点坐标是格子边的相对值,宽高则是整图的相对值。置信度可以反应格子是否包含物体以及包含物体的概率,定义为,无物体则为0,有则为IOU 每个格子预测个类的条件概率,注意这里按格子进行预测,没有按bbox进行预测
DenseBox
DenseBox是早期的Anchor-free目标检测算法,当时R-CNN系列在小物体的检测上有明显的瓶颈,所以作者提出DenseBox,在小物体的检测也有不错的表现。在DenseBox提出的早些时间,著名的Faster R-CNN出现了,其强大的性能主导了目标检测算法往anchor-based的方向发展。直到FPN的出现,Anchor-free算法的性能才有了很大的提升,更多的工作开始涉及Anchor-free领域。目前很多Anchor-free目标检测研究都有DenseBox的影子,所以DenseBox的设计思路还是很超前的。
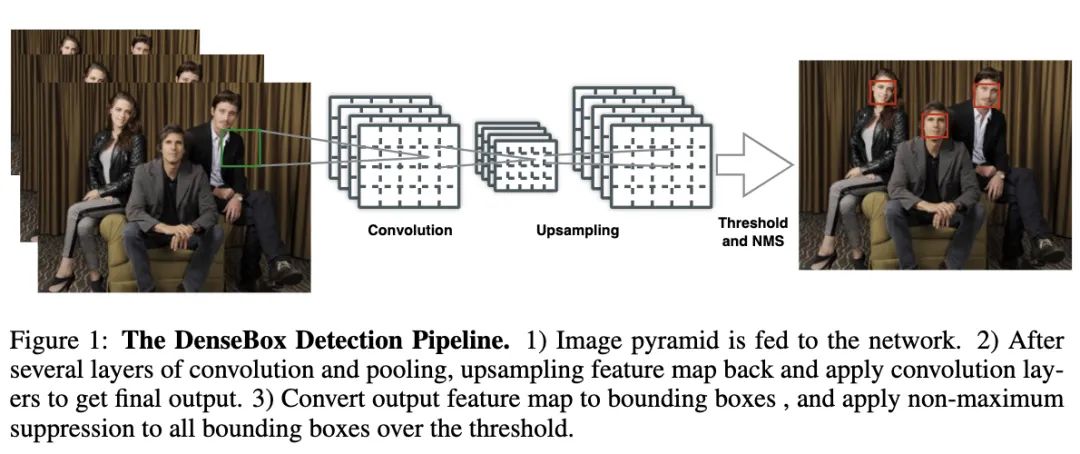
DenseBox的整体设计如图1所示,单个卷积网络同时输出多个预测框及其类别置信度,输出的特征图大小为。假设像素位于,其期望的5维向量为,第一个为分类置信度,后四个为像素位置到目标边界的距离,最后,将所有像素的输出转化为预测框,经过NMS处理后进行最后的输出。
Guided Anchoring
Guided Anchoring通过在线生成anchor的方式解决常规手工预设anchor存在的问题,能够根据生成的anchor自适应特征,在嵌入方面提供了两种实施方法,是一个很完整的解决方案。
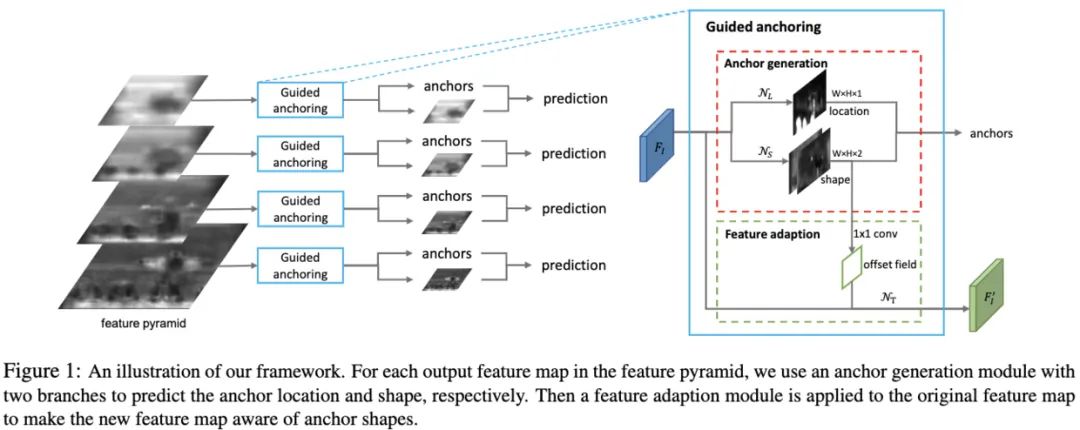
Guided Anchoring首先判断目标可能出现的位置,然后学习不同位置上的目标的形状,可根据图片特征在线学习稀疏的候选anchor。然而,在线生成的anchor形状各异,固定的感受域可能不匹配其形状,所以Guided Anchoring根据anchor的形状进行自适应特征提取,然后再进行预测框精调与分类。
FSAF
目标检测的首要问题就是尺寸变化,许多算法使用FPN以及anchor box来解决此问题。在正样本判断上面,一般先根据目标的尺寸决定预测用的FPN层,越大的目标则使用更高的FPN层,然后根据目标与anchor box的IoU进一步判断,但这样的设计会带来两个限制:拍脑袋式的特征选择以及基于IoU的anchor采样。

为了解决上述的问题,FSAF(feature selective anchor-free)在每轮迭代中选择最优的层进行训练优化。如图3所示,FSAF为FPN每层添加anchor-free分支,包含分类与回归,在训练时,根据anchor-free分支的预测结果选择最合适的FPN层用于训练,最终的网络输出可同时综合FSAF的anchor-free分支结果以及原网络的预测结果。
FCOS
论文提出anchor-free和proposal-free的one-stage的目标检测算法FCOS,不再需要anchor相关的的超参数,在目前流行的逐像素(per-pixel)预测方法上进行目标检测。从实验结果来看,FCOS能够与主流的检测算法相比较,达到SOTA,为后面的大热的anchor-free方法提供了很好的参考。

目标检测由于anchor的存在,不能进行纯逐像素地快速预测,于是FCOS抛弃anchor,提出逐像素全卷积目标检测网络网络,总结如下:
效仿前期的FCNs-based网络,如DenseBox,每个像素回归一个4D向量指代预测框相对于当前像素位置的偏移,如图1左 为了预测不同尺寸的目标,DenseBox会缩放或剪裁生成图像金字塔进行预测,而且当目标重叠时,会出现像素不知道负责预测哪个目标的问题,如图1右。在对问题进行研究后,论文发现使用FPN能解决以上问题 由于预测的结果会产生许多低质量的预测结果,论文采用center-ness分支来预测当前像素与对应目标中心点的偏离情况,用来去除低质量预测结果以及进行NMS
FoveaBox
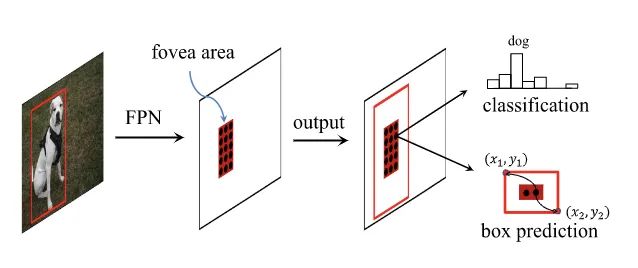
FoveaBox同时预测每个有效位置为目标中心的可能性及其对应目标的尺寸,输出类别置信度以及用以转化目标区域的尺寸信息。作为与FCOS和FSAF同期的Anchor-free论文,FoveaBox在整体结构上也是基于DenseBox加FPN的策略,主要差别在于FoveaBox只使用目标中心区域进行预测且回归预测的是归一化后的偏移值,还有根据目标尺寸选择FPN的多层进行训练。由于FoveaBox的整体实现方案太纯粹了,与其它Anchor-free方法很像,所以一直投稿到现在才中了,作者也是相当不容易。
SAPD
Anchor-free检测方法分为anchor-point类别和key-point类别两种,anchor-point类别虽然更快更灵活,但准确率一般比key-point类别要低,所以论文着力于研究阻碍anchor-point类别准确率的因素,提出了SAPD(Soft Anchor-Point Detecto)。
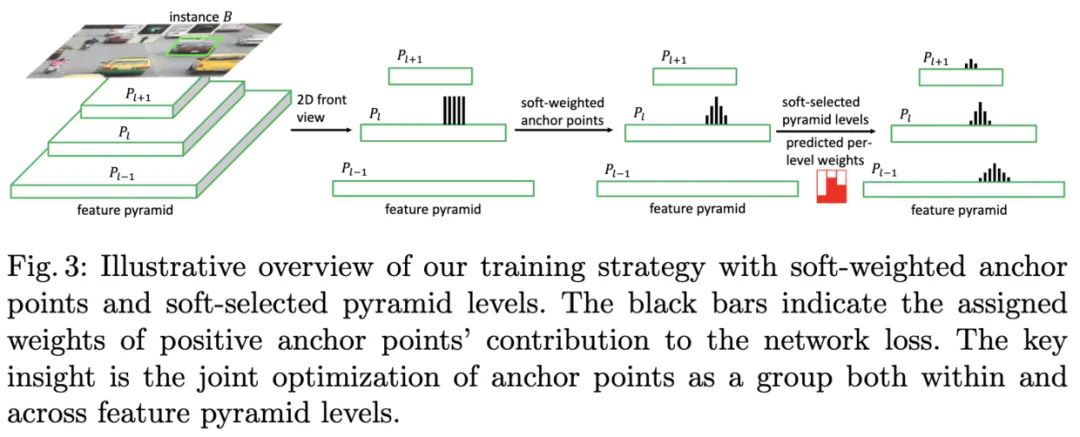
SAPD的核心如图3所示,分别为Soft-Weighted Anchor Points以及Soft-Selected Pyramid Levels:
Soft-weighted anchor points。anchor-point算法在训练时一般将满足几何关系的点设置为正样本点,其损失值权重均为1,这造成定位较不准确的点偶尔分类置信度更高。实际上,不同位置的点的回归难度是不一样的,越靠近目标边缘的点的损失值权重应该越低,让网络集中于优质anchor point的学习。 Soft-selectedpyramid levels。anchor-point算法每轮训练会选择特征金字塔的其中一层特征进行训练,其它层均忽略,这在一定程度上造成了浪费。因为其他层虽然响应不如被选择的层强,但其特征分布应该与被选择层是类似的,所以可以赋予多层不同权重同时训练。
ATSS
在仔细比对了anchor-based和anchor-free目标检测方法后,结合实验结果,论文认为两者的性能差异主要来源于正负样本的定义,假如训练过程中使用相同的正负样本,两者的最终性能将会相差无几,于是论文提出ATSS( Adaptive Training Sample Selection)方法。
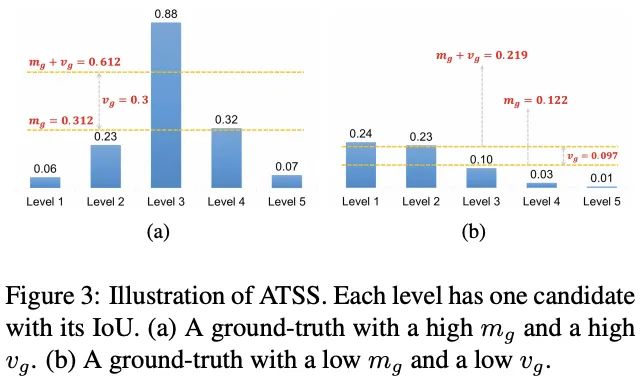
ATSS能够自动根据与GT的相关统计特征选择合适的anchor box作为正样本进行训练,在不带来额外计算量和参数的情况下,能够大幅提升模型的性能,十分有用。
FCOSv2
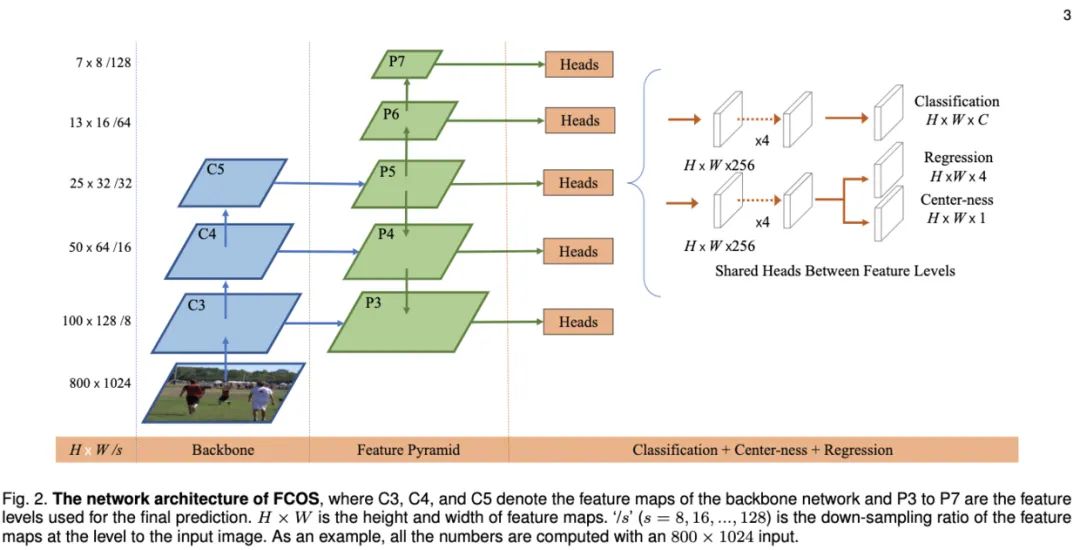
图2为FCOSv2中的主干网络结构,主干网络依然采用FPN,每层特征使用共同的head预测类别信息、尺寸信息以及Center-ness,整体思想基本与FCOS一致。对FCOS的小修小改,最终性能达到了50.4AP,可谓相当强劲了,在工程上可以参考其中的改进以及提升方法。
DDBNet
作者认为当前anchor-free方法存在两个问题,中心关键点与目标的语义不一致以及局部特征的回归有局限性。为了解决上述两个问题,作者提出了十分大胆的方法DDBNet。
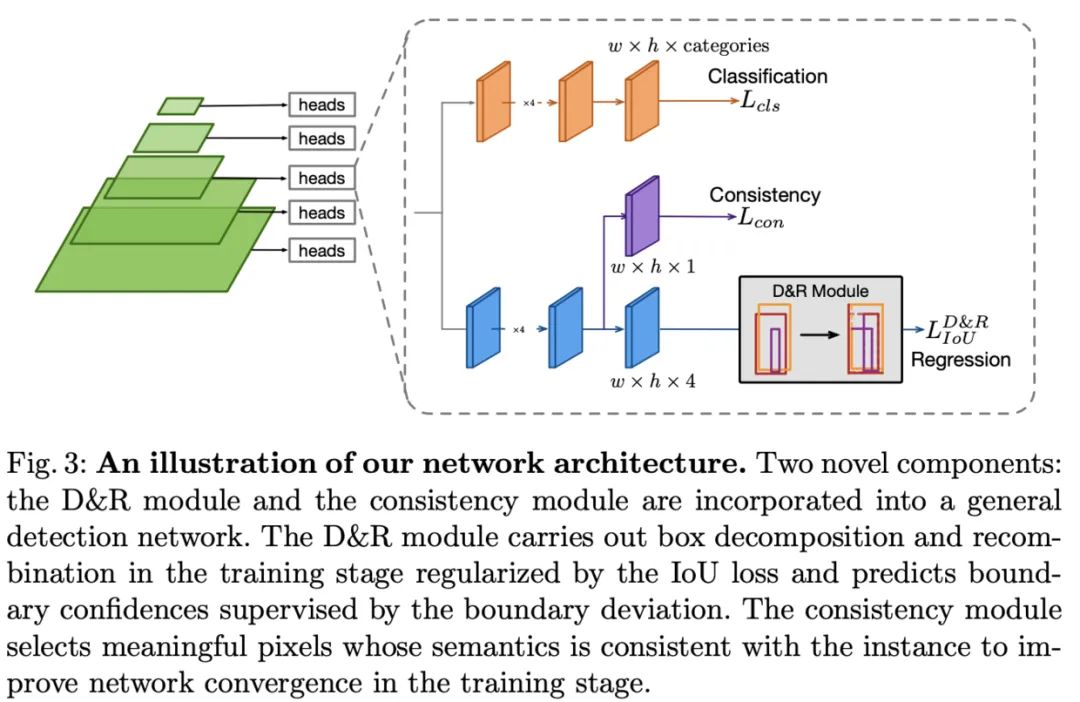
DDBNet包含box分解/组合模块以及语义一致模块,分别用于解决中心关键点的回归不准问题以及中心关键点与目标的语义不一致问题,结果如图2中的实线框。论文的主要贡献如下:
基于anchor-free架构提出新的目标检测算法DDBNet,能够很好地解决中心关键点的回归问题以及中心关键点的语义一致性。 验证了中心关键点和GT的语义一致性,能够帮助提升目标检测网络的收敛性。 DDBNet能够达到SOTA精度(45.5%),并且能够高效地拓展到其它anchor-free检测器中。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
