
【机器学习】Optuna vs Hyperopt 超参数优化哪家强?
选择多了,也是个烦恼!两者都很强,到底选用哪个呢?接下来在本文中,将和大家一起学习:(文章较长,建议点赞收藏!)
在实际问题上使用 Optuna 和 Hyperopt 的示例 在 API、文档、功能等方面比较 Optuna 与 Hyperopt 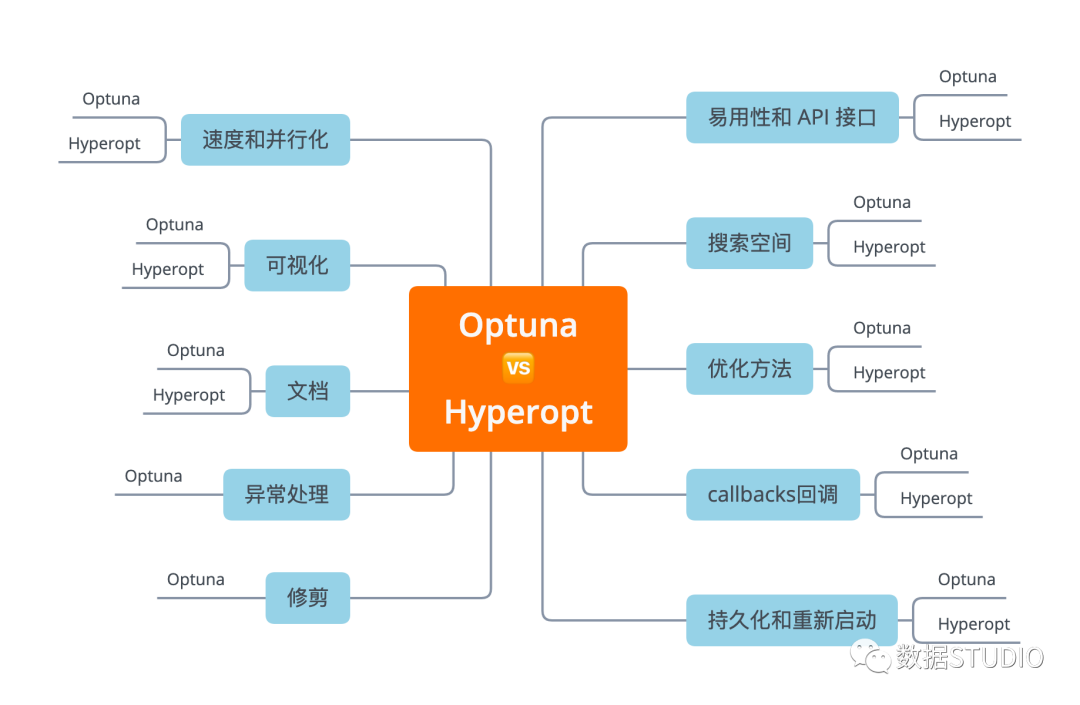
日前,已经对Optuna和Hyperopt等几个超参数优化神器有介绍:
易用性和 API 接口
在本节中,我想了解如何使用这两个库运行基本的超参数调整代码,了解它的易用性以和API。
Optuna
可以在一个函数中定义搜索空间和目标。
从 trail 对象中采样超参数。因此, 参数空间是在执行时定义的。
def objective(trial):
params = {'learning_rate': trial.suggest_loguniform('learning_rate', 0.01, 0.5),
'max_depth': trial.suggest_int('max_depth', 1, 30),
'num_leaves': trial.suggest_int('num_leaves', 2, 100),
'min_data_in_leaf': trial.suggest_int('min_data_in_leaf', 10, 1000),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.1, 1.0),
'subsample': trial.suggest_uniform('subsample', 0.1, 1.0)}
return train_evaluate(params)
然后,创建 study 对象并对其进行优化。可以选择是否要 最大化或最小化 你的目标。这在优化 AUC 等指标时很有用,因为不必在训练前更改目标的符号,然后在训练后再次转换,将最佳结果(如果为负数)转换为正数。
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
关于优化的一切都可以在 optuna 的 study 对象中得到。
我喜欢Optuna的一点是,它非常灵活,我可以即时定义如何对搜索空间进行采样。在AutoML的同时,还能够选择一个优化的方向也是相当不错的。
Hyperopt
首先定义参数搜索空间:
SPACE = {'learning_rate':
hp.loguniform('learning_rate',np.log(0.01),np.log(0.5)),
'max_depth':
hp.choice('max_depth', range(1, 30, 1)),
'num_leaves':
hp.choice('num_leaves', range(2, 100, 1)),
'subsample':
hp.uniform('subsample', 0.1, 1.0)}
然后,创建一个要最小化的目标函数。这意味着你必须将 目标符号转换为 像 AUC 等一样的数值越高越好的指标。
def objective(params):
return -1.0 * train_evaluate(params)
最后,实例化 Trials() 对象并最小化参数搜索空间 SPACE的目标。
trials = Trials()
_ = fmin(objective, SPACE, trials=trials,
algo=tpe.suggest, max_evals=100)
所有关于被测试的超参数的信息和相应的分数都保存在 trials 对象中。
即使在最简单的情况下,我也需要实例化 Trials(),这里如果让 fmin 返回 trials 并默认进行实例化,应该会便利不少。
这两个库在这里都做得很好,但我觉得Optuna稍微好一些,因为它具有灵活性、命令式的参数采样方法和较少的模板。
Optuna > Hyperopt
选项、方法与超参数
在现实生活场景中,运行超参数优化需要许多远离黄金路径的额外选项。在本节中,将从以下几个方面比较 Optuna 和 Hyperopt。
搜索空间 优化方法/算法 回调 持久化和重新启动参数扫描 修剪无效运行 处理异常
搜索空间
在本节中,比较搜索空间定义、定义复杂空间的灵活性以及每种参数类型(Float、Integer、Categorical)的采样选项。
Optuna
可以找到所有超参数类型的采样选项:
分类参数: trial.suggest_categorical整数参数: trial.suggest_int浮点数参数:* trial.suggest_uniform*、trial.suggest_loguniform甚至更奇特的是trial.suggest_discrete_uniform
特别是对于整数参数,可能希望有更多选项,但它处理大多数用例。这个库的一大特点是可以从参数空间中即时采样,且可以随心所欲地进行采样。可以使用 if 语句,可以更改搜索的间隔,可以使用来自 trail 对象的信息来指导搜索策略。
def objective(trial):
classifier_name = trial.suggest_categorical('classifier', ['SVC', 'RandomForest'])
if classifier_name == 'SVC':
svc_c = trial.suggest_loguniform('svc_c', 1e-10, 1e10)
classifier_obj = sklearn.svm.SVC(C=svc_c)
else:
rf_max_depth = int(trial.suggest_loguniform('rf_max_depth', 2, 32))
classifier_obj = sklearn.ensemble.RandomForestClassifier(max_depth=rf_max_depth)
...
这简直可以做任何事情~
Hyperopt
搜索空间是 Hyperopt 真正提供大量采样选项的地方:
分类参数: hp.choice整数参数: hp.randit、hp.quniform、hp.qloguniform、hp.qlognormal浮点数参数: hp.normal、hp.uniform、hplognormal、hp.loguniform
据我所知,这是目前最广泛的采样功能。
在运行优化之前定义搜索空间,还 可以创建非常复杂的参数空间:
复杂的参数空间:
上下滑动查看更多源码
SPACE = hp.choice('classifier_type', [
{
'type': 'naive_bayes',
},
{
'type': 'svm',
'C': hp.lognormal('svm_C', 0, 1),
'kernel': hp.choice('svm_kernel', [
{'ktype': 'linear'},
{'ktype': 'RBF', 'width': hp.lognormal('svm_rbf_width', 0, 1)},
]),
},
{
'type': 'dtree',
'criterion': hp.choice('dtree_criterion', ['gini', 'entropy']),
'max_depth': hp.choice('dtree_max_depth',
[None, hp.qlognormal('dtree_max_depth_int', 3, 1, 1)]),
'min_samples_split': hp.qlognormal('dtree_min_samples_split', 2, 1, 1),
},
])不得不说,二者在这点上都表现非常优秀!不仅可以轻松定义嵌套搜索空间,并且有很多针对所有不同参数类型的采样选项。Optuna 具有命令式参数定义,提供了更大的灵活性,而 Hyperopt 具有更多的参数采样选项。
Optuna = Hyperopt
优化方法
Optuna 和 Hyperopt 都在后台使用相同的优化方法 。他们有:
rand.suggest(Hyperopt) samplers.random.RandomSampler(Optuna)
对参数的标准随机搜索
tpe.suggest(Hyperopt) samplers.tpe.sampler.TPESampler(Optuna)
Parzen 估计器树 (TPE)。这种方法使用廉价的代理模型来估计昂贵的目标函数在一组参数上的性能。
Tree Parzen Estimator 不是对给定配置 的观测值 的概率 建模,而是对密度函数 和 建模。给定一个百分位数 (通常设置为 15%),观察结果分为好和坏,并且使用简单的 1-d Parzen 窗口对这两个分布进行建模。
通过使用 和 ,可以估计参数配置相对于先前最佳值的预期改进。
对于 Optuna 和 Hyperopt,都没有选项可以在优化器中指定 α 参数。
Optuna
integration.SkoptSampler
Optuna 接受使用来自 Scikit-Optimize (skopt) 的采样器。Skopt 提供了一堆基于树的方法作为代理模型的选择。
创建一个 SkoptSampler实例,在skopt_kwargs参数中指定代理模型和采集函数的参数将采样器 sampler实例传递给optuna.create_study方法
from optuna.integration import SkoptSampler
sampler = SkoptSampler(
skopt_kwargs={'base_estimator':'RF',
'n_random_starts':10,
'base_estimator':'ET',
'acq_func':'EI',
'acq_func_kwargs': {'xi':0.02})
study = optuna.create_study(sampler=sampler)
study.optimize(objective, n_trials=100)
还可以使用一种称为异步连续二分算法 (ASHA) 的多臂 bandid 方法[1]方法。如果对细节感兴趣,请阅读本文 大规模并行超参数调整系统[2] ,但总体思路是:
运行一堆参数配置一段时间 修剪(一半)最没有希望的运行 运行一堆参数配置一段时间 修剪(一半)最没有希望的运行 当只剩下一个配置时停止
通过这样做,搜索可以集中在更有希望的运行。然而,配置预算的静态分配在实践中是一个问题(一种新的称为HyperBand[3]的方法解决了这个问题)。
在Optuna中使用ASHA非常容易。只要传递一个SuccesiveHalvingPruner到.create_study() 即可实现。
from optuna.pruners import SuccessiveHalvingPruner
optuna.create_study(pruner=SuccessiveHalvingPruner())
study.optimize(objective, n_trials=100)
总体而言,目前在优化功能方面有很多选择。
Hyperopt
atpe.suggest
Hyperopt中优化方法自适应 TPE 是由 ElectricBrain 发明的,实际上是他们在 TPE 之上进行的一系列小的改进。详情请见对 TPE 的改进[4]
该方法使用非常方便。只需要将 atpe.suggest 传递给 fmin 函数,而不是 tpe.suggest 。
from hyperopt import fmin, atpe
best = fmin(objective, SPACE,
max_evals= 100 ,
algo=atpe.suggest)
atpe.suggest方法是新的优化算法,是原始方法的一种新的改进,而不仅仅是与现有算法的集成。
Optuna = Hyperopt
Callbacks回调
在本节中,看看在每次迭代后定义回调以monitor/snapshot/modify训练是多么容易。它很有用,尤其是当模型训练时间很长和/或分散时。
Optuna
.optimize() 方法中 的 callbacks 回调参数很好地支持用户回调 。只需传递一个以study和trail为输入的可调用对象列表。
import neptune
def neptune_monitor(study, trial):
neptune.log_metric('run_score', trial.value)
neptune.log_text('run_parameters', str(trial.params))
...
study.optimize(objective, n_trials=100, callbacks=[neptune_monitor])
可以同时访问 study和trail ,所以拥有可能想要检查点、提前停止或修改未来搜索的所有灵活性。
Hyperopt
本身没有回调,但可以将回调函数放在 Objective 中,并且每次调用目标时都会执行它。
def monitor_callback(params, score):
neptune.send_metric('run_score', score)
neptune.send_text('run_parameters', str(params))
def objective(params):
score = -1.0 * train_evaluate(params)
monitor_callback(params, score)
return score
在这一个点上,Hyperopt明显输了一截。
Optuna > Hyperopt
持久化和重启
持久化保存和重新加载超参数搜索可以节省时间和金钱,并有助于获得更好的结果。我们比较一下这两个框架。
Optuna
只需使用 joblib.dump pickle trail 对象。
study.optimize(objective, n_trials= 100 )
joblib.dump(study, 'artifacts/study.pkl')
可以稍后使用 joblib.load 加载它以重新开始搜索。
study = joblib.load('../artifacts/study.pkl')
study.optimize(objective, n_trials= 200)
对于 分布式设置 ,可以使用study_name,分发研究的数据库的 URL用于实例化新研究。例如
study = optuna.create_study(
study_name='example-study',
storage='sqlite:///example.db',
load_if_exists=True)
Hyperopt
与 Optuna 类似, joblib.dump pickle trail 对象。
trials = Trials()
_ = fmin(objective, SPACE, trials=trials,
algo=tpe.suggest, max_evals=100)
joblib.dump(trials, 'artifacts/hyperopt_trials.pkl')
使用 joblib.load 加载它以重新开始搜索。
trials = joblib.load('artifacts/hyperopt_trials.pkl')
_ = fmin(objective, SPACE, trials=trials,
algo=tpe.suggest, max_evals=200)
更多运行分布式超参数优化详情请见速度和并行化部分。
Optuna = Hyperopt
修剪
并非所有的超参数配置都是一样的。其实很容易地发现其中一些参数并不会对模型最终效果得分产生很大贡献。理想情况下,我们希望尽快停止这些运行,并留出更多的时间资源去尝试其他不同的更有效的参数。
Optuna 中使用 Pruning Callbacks 选项执行此操作。支持许多机器学习框架:
KerasPruningCallback, TFKerasPruningCallback TensorFlowPruningHook PyTorchIgnitePruningHandler, PyTorchLightningPruningCallback FastAIPruningCallback LightGBMPruningCallback XGBoostPruningCallback more[5]
例如,在训练 lightGBM模型的情况下,可以将此Callbacks传递给 lgb.train 函数。
上下滑动查看更多源码
def train_evaluate(X, y, params, pruning_callback=None):
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1234)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
callbacks = [pruning_callback] if pruning_callback is not None else None
model = lgb.train(params, train_data,
num_boost_round=NUM_BOOST_ROUND,
early_stopping_rounds=EARLY_STOPPING_ROUNDS,
valid_sets=[valid_data],
valid_names=['valid'],
callbacks=callbacks)
score = model.best_score['valid']['auc']
return score
def objective(trial):
params = {'learning_rate': trial.suggest_loguniform('learning_rate', 0.01, 0.5),
'max_depth': trial.suggest_int('max_depth', 1, 30),
'num_leaves': trial.suggest_int('num_leaves', 2, 100),
'min_data_in_leaf': trial.suggest_int('min_data_in_leaf', 10, 1000),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.1, 1.0),
'subsample': trial.suggest_uniform('subsample', 0.1, 1.0)}
pruning_callback = LightGBMPruningCallback(trial, 'auc', 'valid')
return train_evaluate(params, pruning_callback)Hyperopt 没有此功能
Optuna > Hyperopt
异常处理
如果在一次运行由于错误的参数组合、随机训练错误或其他问题而失败,可能会丢失 迄今为止在study中评估的所有 parameter_configuration:score 对。
其实可以在每次迭代后使用回调来保存此信息,或者使用数据库来存储它。
但是,即使发生异常,也可能希望继续进行这项study。Optuna 中将异常传递给 .optimize() 方法。
def objective(trial):
params = {'learning_rate': trial.suggest_loguniform('learning_rate', 0.01, 0.5),
'max_depth': trial.suggest_int('max_depth', 1, 30),
'num_leaves': trial.suggest_int('num_leaves', 2, 100)}
print(non_existent_variable)
return train_evaluate(params)
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100, catch=(NameError,))
Hyperopt 没有此功能
Optuna > Hyperopt
官方文档
每当我们学习一个新库或框架时,需要找到所需信息绝对至关重要,此时官方文档相当有用。下面看看 Optuna 和 Hyperopt 在这方面的比较。
Optuna
Optuna 官方文档[6] 解释了所有基本概念,并向您展示了在哪里可以找到更多信息。
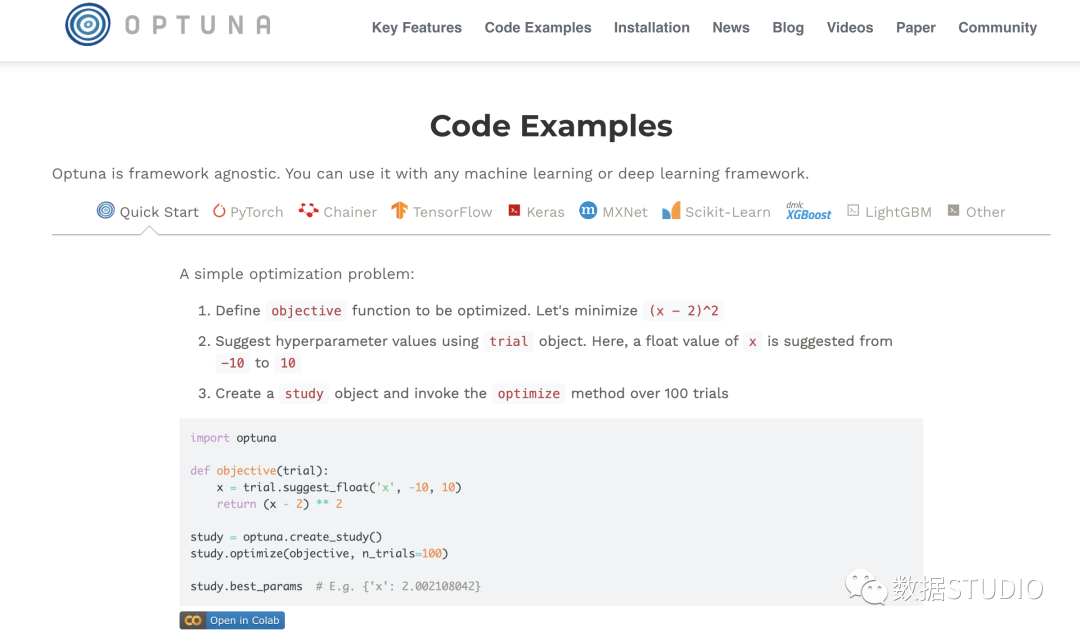
还有有一个完整且非常易于理解 read-the-docs文档[7]。它包含:
包含简单示例和高级示例的教程 包含文档字符串的所有函数的 API 参考。
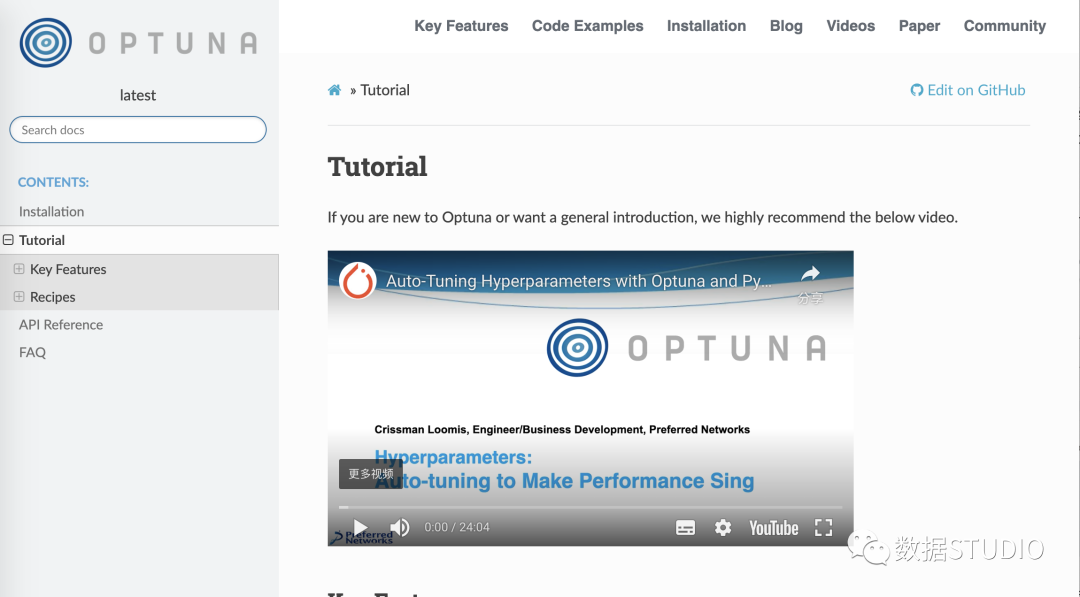
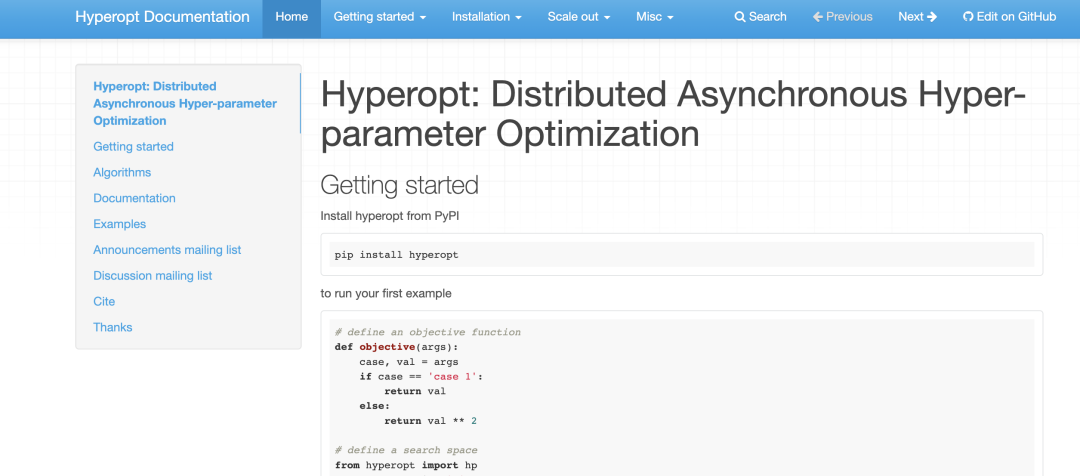
Hyperopt
你可以这里找到 Hyperopt官方文档[8]。它包含以下信息:
如何开始 如何定义简单搜索空间和高级搜索空间 如何运行安装 如何通过 MongoDB 或 Spark 并行运行 Hyperopt
虽然文档 不是Hyperopt最强大的一面 ,但因为它是经典,所以有很多资源可供学习。
Optuna > Hyperopt
可视化超参数搜索
可视化超参数搜索可能非常有用。可以获得有关参数之间交互的信息,并查看下一步应该搜索的位置。
Optuna
optuna.visualization 模块中提供了一些很棒的可视化 :
plot_contour: 在交互式图表上绘制参数交互。可以选择要探索的超参数。
plot_contour(study, params=['learning_rate',
'max_depth',
'num_leaves',
'min_data_in_leaf',
'feature_fraction',
'subsample'])
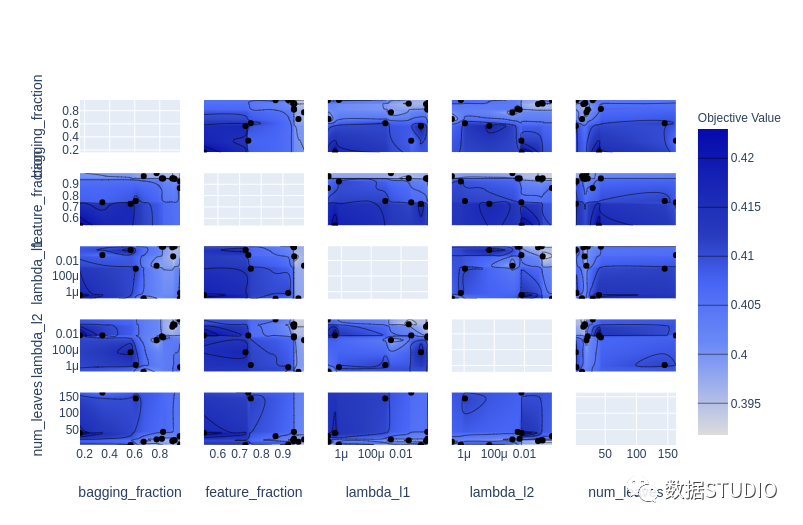
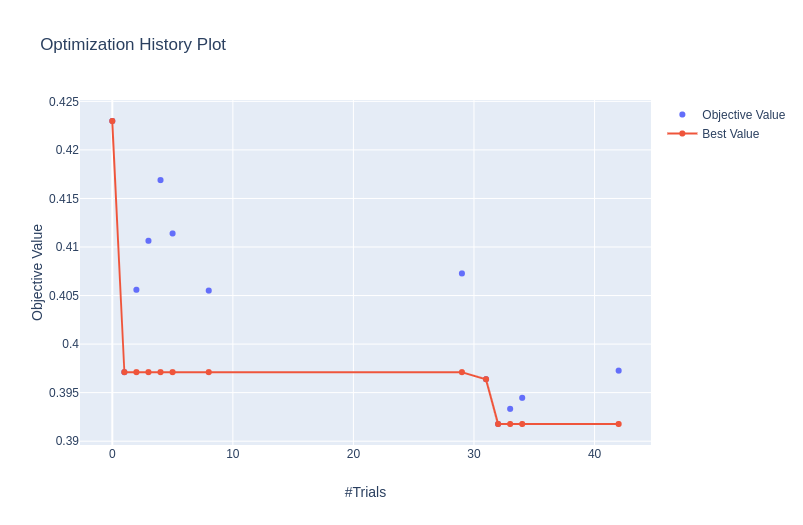
plot_optimization_histor: 显示所有试验的分数以及迄今为止每个点的最佳分数。
plot_optimization_history(study)
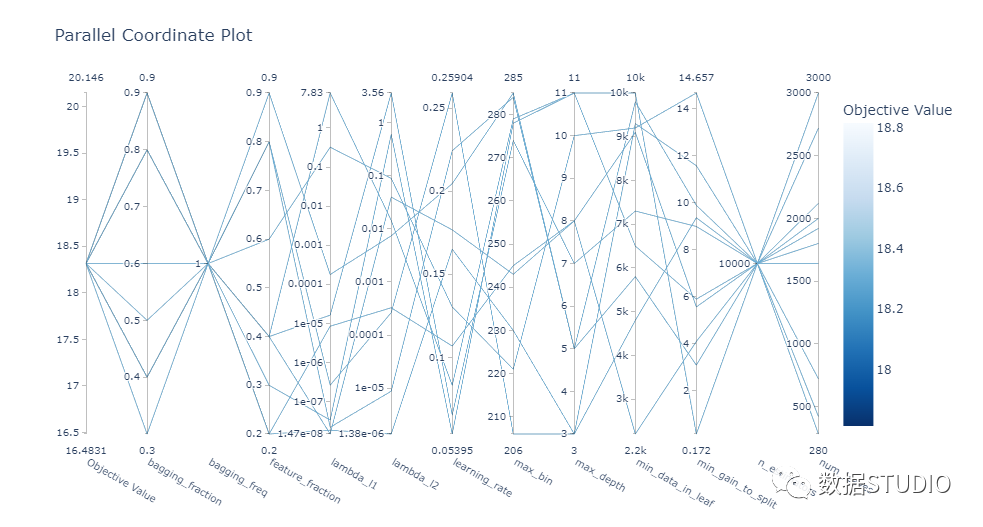
plot_parallel_coordinate: 以交互方式可视化超参数和分数
plot_parallel_coordinate(study)
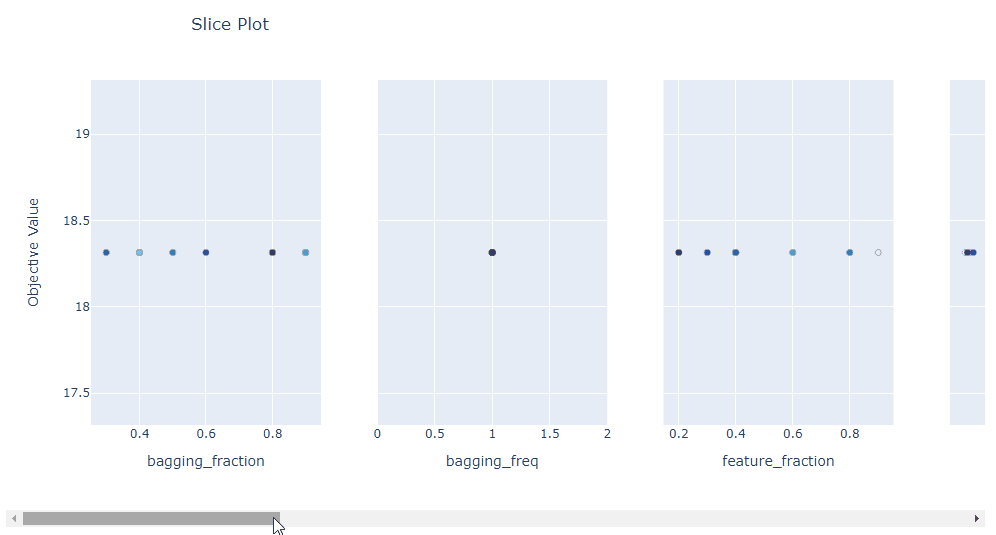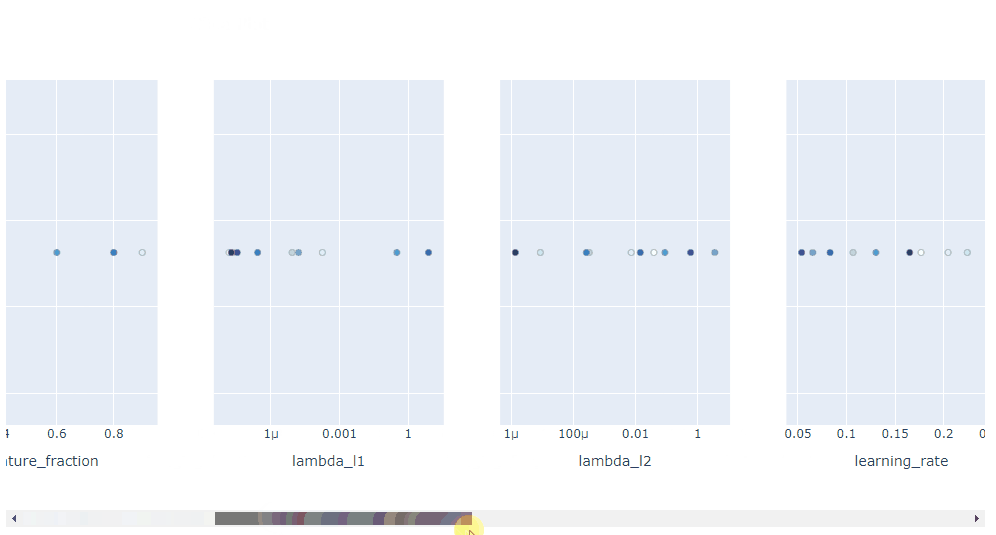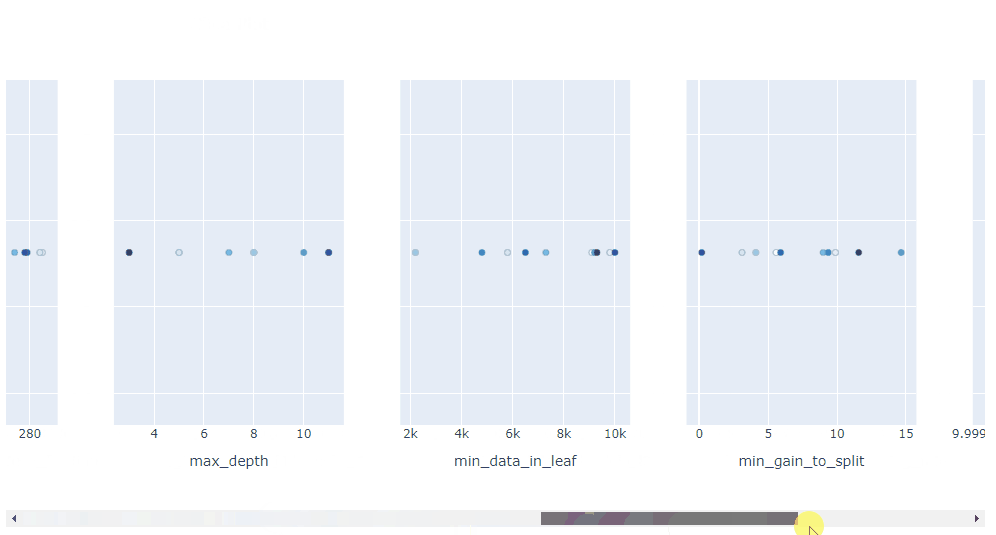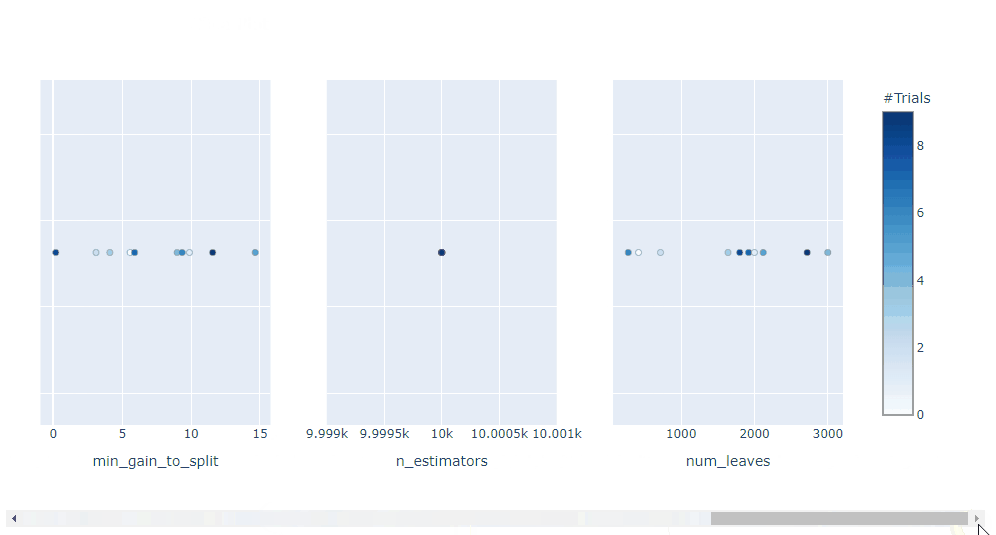
plot_slice: 显示搜索的演变。可以看到搜索在超参数空间中的哪个位置以及空间的哪些部分被探索得更多。
plot_slice(study)
总体而言, Optuna 中的可视化效果真是太棒了。它们助你放大超参数交互并帮助你决定如何运行下一个参数扫描。
Hyperopt
hyperopt.plotting 模块中有三个可视化函数:
main_plot_history: 显示每次迭代的结果并突出显示最佳分数。
main_plot_history(trail)
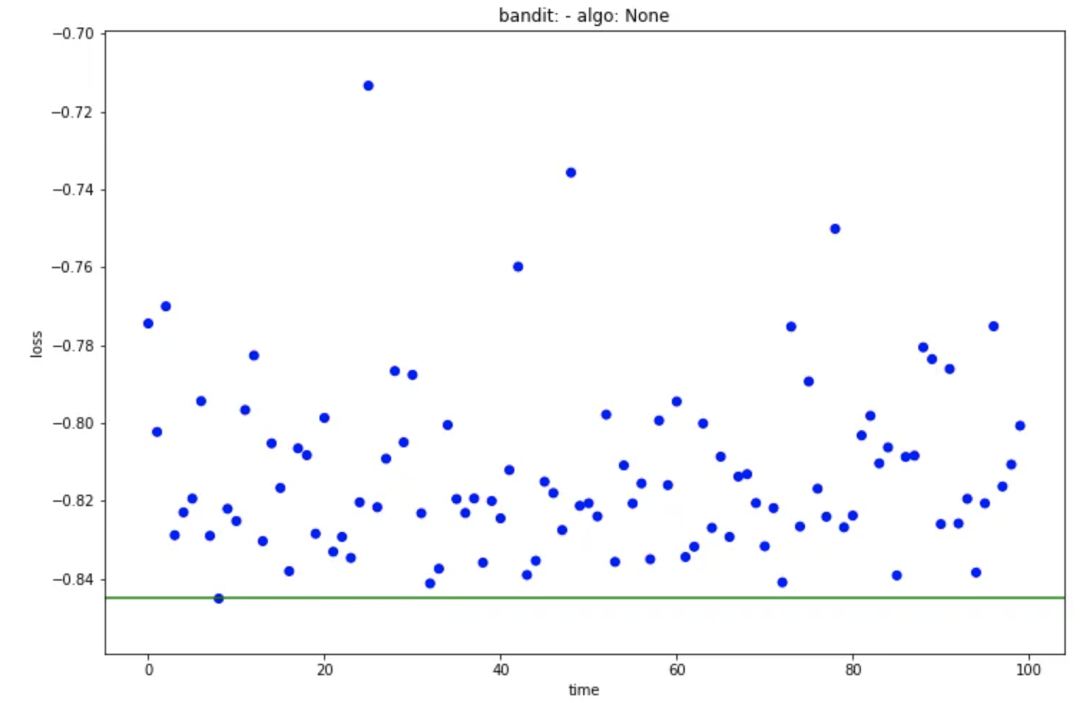
main_plot_histogram: 显示所有迭代结果的直方图。
main_plot_histogram(trail)
main_plot_vars: 暂时无法让它运行,不知道它做了什么,也没有文档字符串或示例(文档有些缺陷)。
总而言之,Hyperopt有一些基本的可视化实用程序,但它们并不是超级有用。
而 Optuna 中可用的可视化给我留下了深刻的印象。有用、可交互、美观。
Optuna > Hyperopt
速度和并行化
在超参数优化方面,能够将训练分布在机器或多台机器(集群)上可能至关重要。
Optuna
可以在一台机器或一组机器上运行分布式超参数优化,这实际上非常简单。
对于一台机器,只需更改 .optimize() 方法中的 n_jobs 参数 。
study.optimize(objective, n_trials=100, n_jobs=12)
如果要在多台机器集群上运行它,需要创建一个驻留在数据库中的study (可以在许多关系型数据库中进行选择)。
可以通过命令行界面执行此操作:
optuna create-study \
--study-name "distributed-example" \
--storage "sqlite:///example.db"
还可以在优化脚本中创建study。
通过使用 load_if_exists=True ,可以以相同的方式处理主脚本和工作脚本, 这大大简化了流程。
study = optuna.create_study(
study_name='distributed-example',
storage='sqlite:///example.db',
load_if_exists=True)
study.optimize(objective, n_trials=100)
最后可以在多台机器上运行工作脚本,它们都将使用study数据库中的相同信息。
terminal-1$ python run_worker.py
terminal-2$ python run_worker.py
Hyperopt
可以将计算分布在一组机器上。可以在Tanay Agrawal博客文章[9] 中找到好的分步说明, 但简而言之,需要:
启动一个带有 MongoDB 的服务器 ,它将使用训练脚本的结果并发送下一个参数集以尝试, 在训练脚本中, 创建一个指向你在上一步中启动的数据库服务器的 MongoTrials()对象,而不是Trials(),将 Objective函数移动到单独的脚本并将其重命名为 objective.py 函数,编译你的 Python 训练脚本, 运行 hyperopt-mongo-worker
虽然它能够实现分布式供能,但感觉并不完美。需要围绕Objective函数进行一些调整,并且可以在 CLI 中提供启动 MongoDB 以使事情变得更容易。
另外,可以通过 SparkTrials对象与 Spark 的集成。具体可以参考Scaling out search with Apache Spark[10],甚至可以使用 spark-installation 脚本更容易地处理分布式study。
best = hyperopt.fmin(fn = objective,
space = search_space,
algo = hyperopt.tpe.suggest,
max_evals = 64,
trials = hyperopt.SparkTrials())
这两个库都支持分布式训练。但是Optuna 在更简单、更用户友好的界面方面做得更好。
Optuna > Hyperopt
一个用来比较的通用测试模版
一个示例,在 二分类 问题上调整 LightGBM 模型的超参数。所有的训练和评估逻辑都放在 train_evaluate 函数中。我们可以将其视为一个黑匣子 ,它获取数据和超参数集并产生 AUC 评估分数。
上下滑动查看更多源码
import lightgbm as lgb
from sklearn.model_selection import train_test_split
import pandas as pd
NUM_BOOST_ROUND = 300
EARLY_STOPPING_ROUNDS = 30
def train_evaluate(X, y, params):
X_train, X_valid, y_train, y_valid = train_test_split(X, y,
test_size=0.2,
random_state=1234)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
model = lgb.train(params, train_data,
num_boost_round=NUM_BOOST_ROUND,
early_stopping_rounds=EARLY_STOPPING_ROUNDS,
valid_sets=[valid_data],
valid_names=['valid'])
score = model.best_score['valid']['auc']
return score
N_ROWS=10000
TRAIN_PATH = './data/train.csv'
data = pd.read_csv(TRAIN_PATH, nrows=N_ROWS)
X = data.drop(['ID_code', 'target'], axis=1)
y = data['target']
MODEL_PARAMS = {'boosting': 'gbdt',
'objective':'binary',
'metric': 'auc',
'num_threads': 12,
'learning_rate': 0.3,
}
score = train_evaluate(X, y, MODEL_PARAMS)
print('Validation AUC: {}'.format(score))多臂 bandid 方法: https://link.springer.com/content/pdf/10.1007/11564096_42.pdf
[2]大规模并行超参数调整系统: https://arxiv.org/abs/1810.05934
[3]HyperBand: https://arxiv.org/abs/1603.06560
[4]对 TPE 的改进: https://github.com/electricbrainio/hypermax
[5]more: https://optuna.readthedocs.io/en/latest/reference/integration.html
[6]Optuna 官方文档: https://optuna.org/
[7]read-the-docs文档: https://optuna.readthedocs.io/en/latest/tutorial/index.html
[8]Hyperopt官方文档: http://hyperopt.github.io/hyperopt/
[9]Tanay Agrawal博客文章: https://blog.goodaudience.com/on-using-hyperopt-advanced-machine-learning-a2dde2ccece7
[10]Scaling out search with Apache Spark: http://hyperopt.github.io/hyperopt/scaleout/spark/
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码