
【Python】图解Pandas重复值处理
公众号:尤而小屋
作者:Peter
编辑:Peter
今天带来的文章是关于Pandas中重复值处理。Pandas中处理重复值主要使用的是两个函数:
duplicated():判断是否有重复值 drop_duplicates() :删除重复值

一、模拟数据
在本文中模拟了两份不同的数据:
1、一份订单数据,后面会使用
import pandas as pd
import numpy as np
# 导入一份模拟数据:待用
df1 = pd.read_excel("订单重复值.xlsx")
df1

2、模拟的另一份数据:
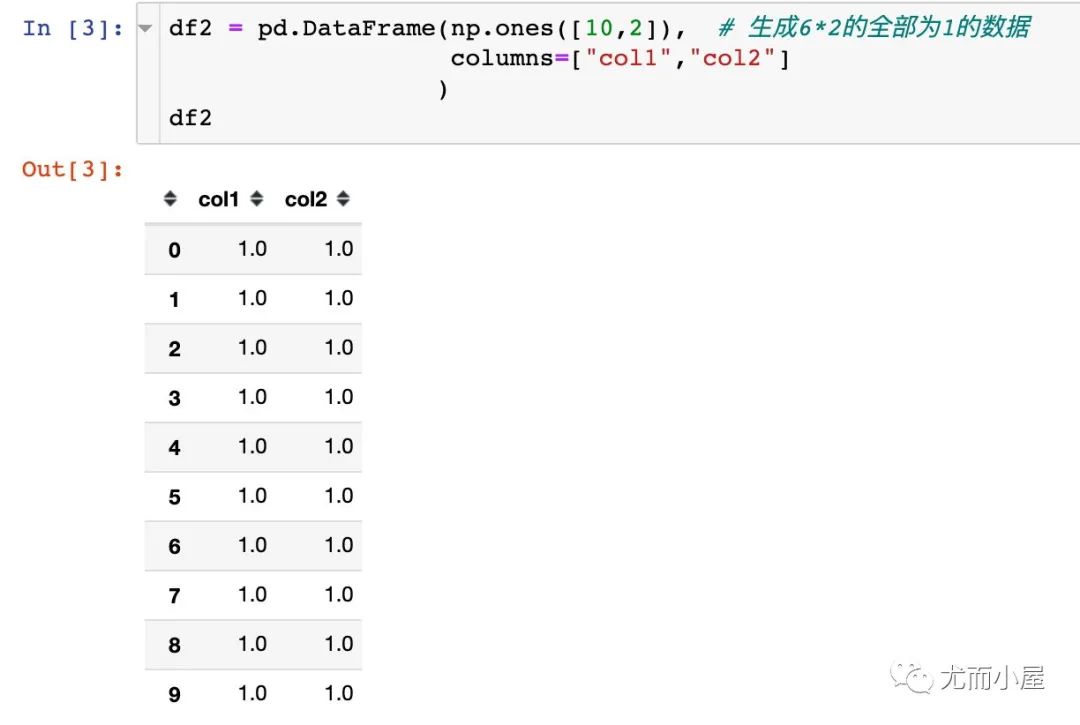
df2 = pd.DataFrame(np.ones([10,2]), # 生成6*2的全部为1的数据
columns=["col1","col2"]
)
df2
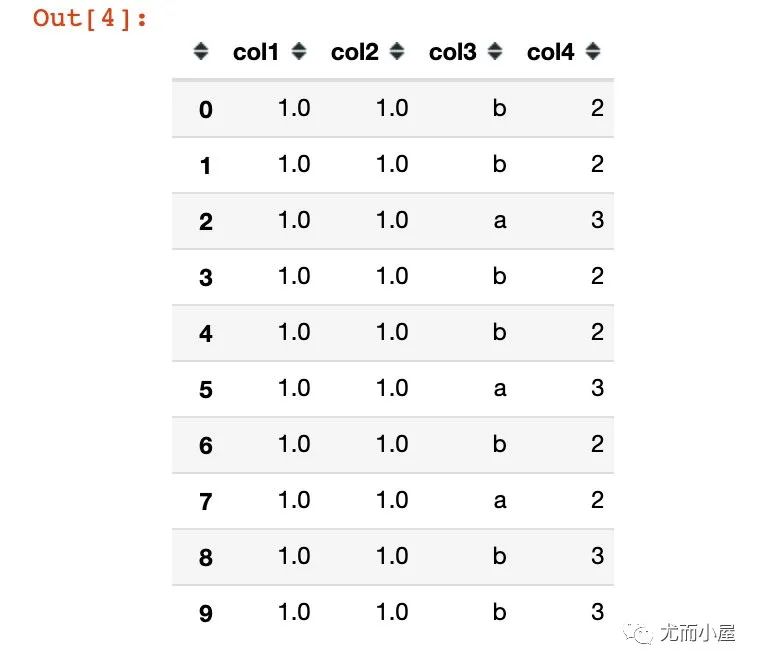
再增加了两个字段:都是从列表中随机有抽样放回的选取
# 增加两列
list1 = ["a","b"]
list2 = [2,3]
# 在列表中随机选择10个元素,有放回抽样
df2["col3"] = np.random.choice(list1,10)
df2["col4"] = np.random.choice(list2,10)
df2
二、判断重复值-duplicated()
函数的功能是检查数据中是否有重复值,用于标记 Series 中的值、DataFrame 中的记录行是否重复,重复为 True,不重复为 False。
每行数据都是和它前面的记录相比较。
2.1语法
针对DataFrame类型数据:
pandas.DataFrame.duplicated(subset=None,keep='first')
或者针对Series的数据:
pandas.Series.duplicated(keep='first')
keep参数的3种取值解释:
first:将重复项标记True为第一次出现的除外 last:将重复项标记True为最后一次除外 False:将所有重复项标记为True
2.2基本使用
通过这个函数能够判断哪些数据是重复的:重复标记为True,否则为False

2.3参数subset
df2.duplicated(subset=["col3"]) # 单独看col3列是否重复
# 结果
0 False
1 True
2 False
3 True
4 True
5 True
6 True
7 True
8 True
9 True
dtype: bool
df2.duplicated(subset=["col1"]) # 单独看col1:全部是1,后面全部是重复的
0 False
1 True
2 True
3 True
4 True
5 True
6 True
7 True
8 True
9 True
dtype: bool
上面的两个例子都是看单个字段是否重复,下面的例子是通过查看多个属性:
df2.duplicated(subset=["col3","col4"]) # 同时看col3和col4
0 False
1 True
2 False
3 True
4 True
5 True
6 True
7 False
8 False
9 True
dtype: bool
2.4参数keep
df2.duplicated(subset=["col3"],keep="last")
0 True
1 True
2 True
3 True
4 True
5 True
6 True
7 False # 第一次出现
8 True
9 False # 第一次出现
dtype: bool
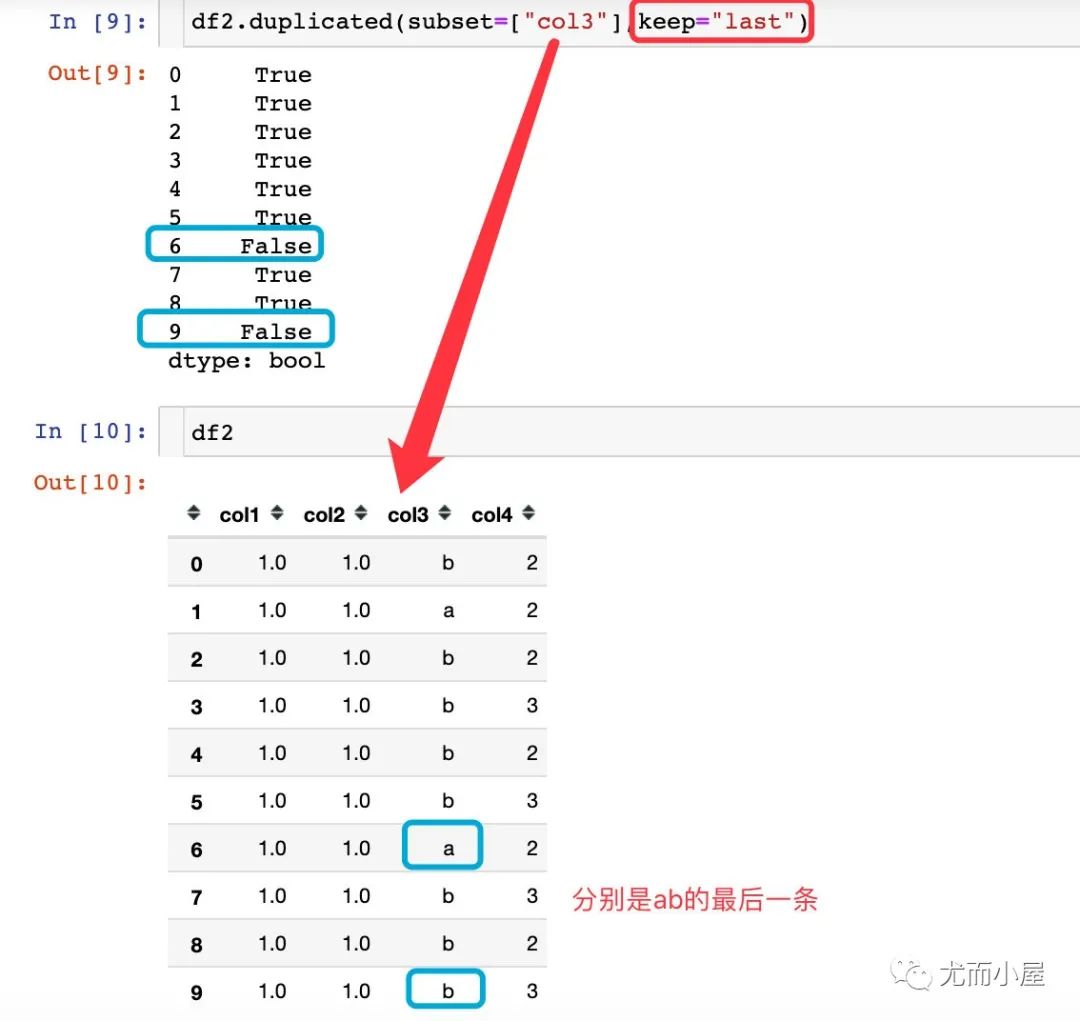
上面的keep参数使用的是last,相当于是最后的一条数据是初始值,前面的值和它进行比较,是否有重复值 下面的案例中keep使用的first(默认),相当于是将第一次出现的数据看做是初始值,后面的数据和它相比;如果重复标记为True
df2.duplicated(subset=["col3"],keep="first") # 默认是first
0 False # 第一次出现
1 True
2 False # 第一次出现
3 True
4 True
5 True
6 True
7 True
8 True
9 True
dtype: bool
df2.duplicated(subset=["col3"],keep=False) # 将所有的重复值标记为True
0 True
1 True
2 True
3 True
4 True
5 True
6 True
7 True
8 True
9 True
dtype: bool
三、drop_duplicates()
该函数的作用是删除数据中的重复值
3.1语法形式
subset:表示按照指定的一个或者多个列属性来删除重复值,可选性;默认是全部列属性 keep:表示删除重复值后保留的数据,默认是保留第一条数据 inplace:表示删除重复是生成副本,还是直接在原数据上进行修改。这个参数的功能在pandas的功能都是如此 ingoore_index:生成数据的索引是元数据的,还是从0,1,2...到n-1的自然数排列
下面是来自官网的参数解释:

3.2全部使用默认参数
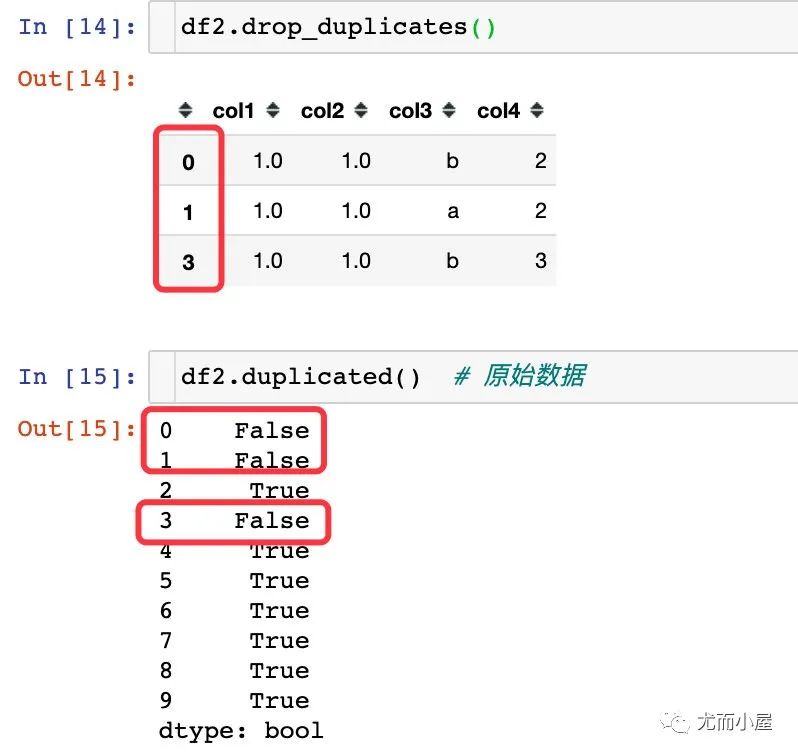
上面的结果有两个特点:
索引还是原数据的索引 保留的数据是每条值的第一条(如果存在重复值) 判断是否重复,使用的是全部列属性 上面的数据就是下面判断是否重复的为False的数据(对比序号)
3.3参数subset
subset是可以指定我们想通过哪些属性来进行删除:
1、通过单个属性字段来删除
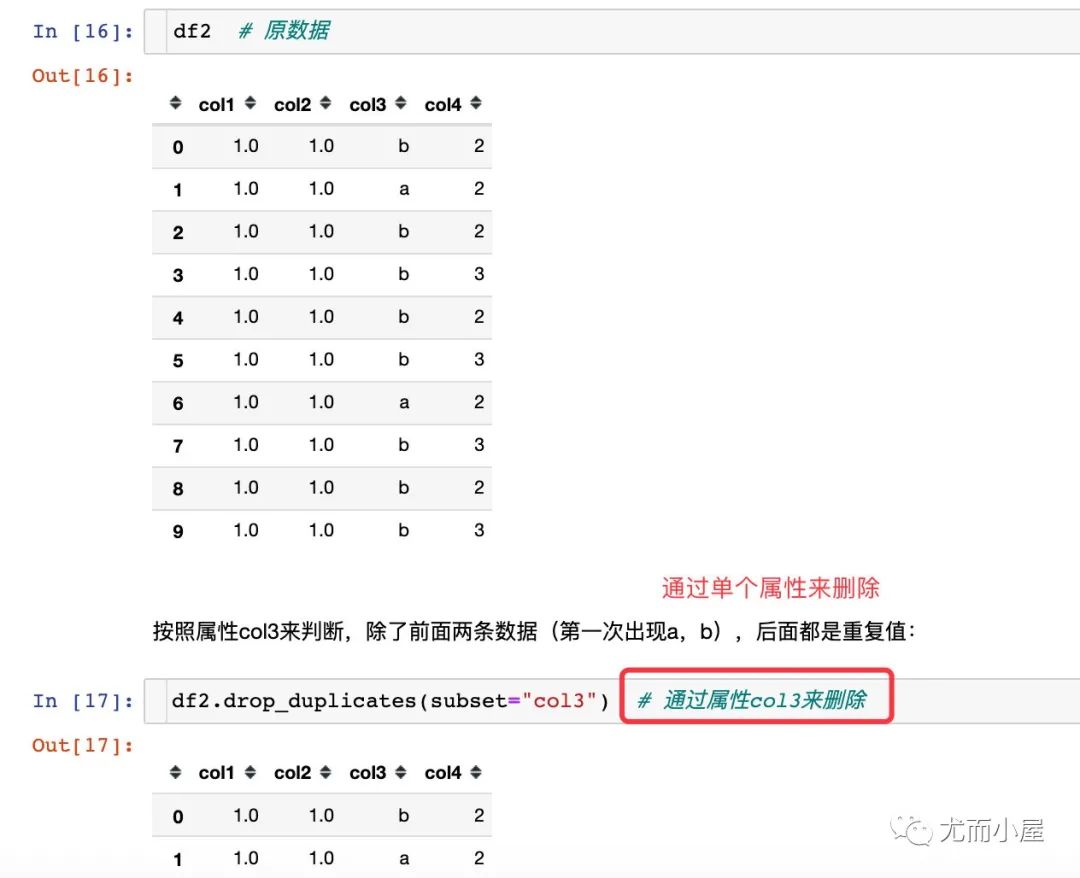
2、通过多个字段属性来删除
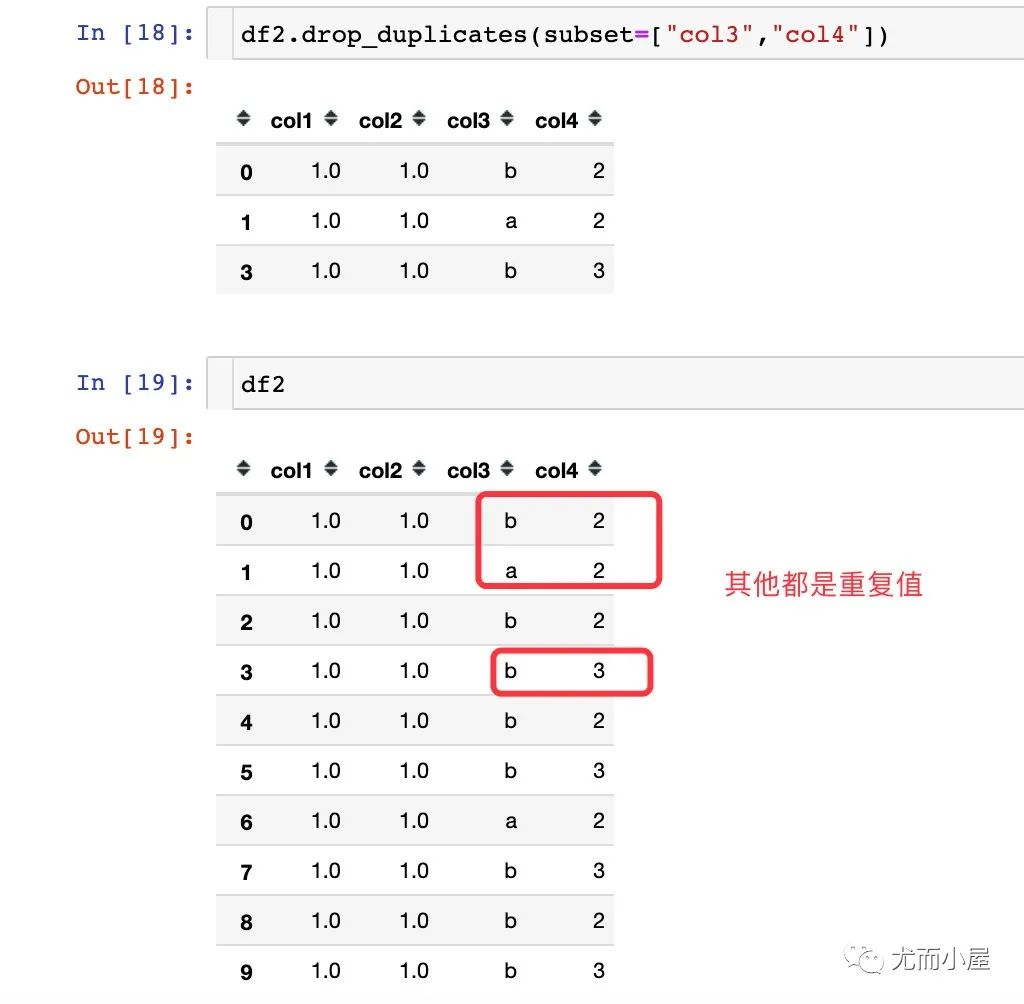
3.4参数keep
keep参数保留我们想要的数据:第一条还是最后一条
1、keep="first"

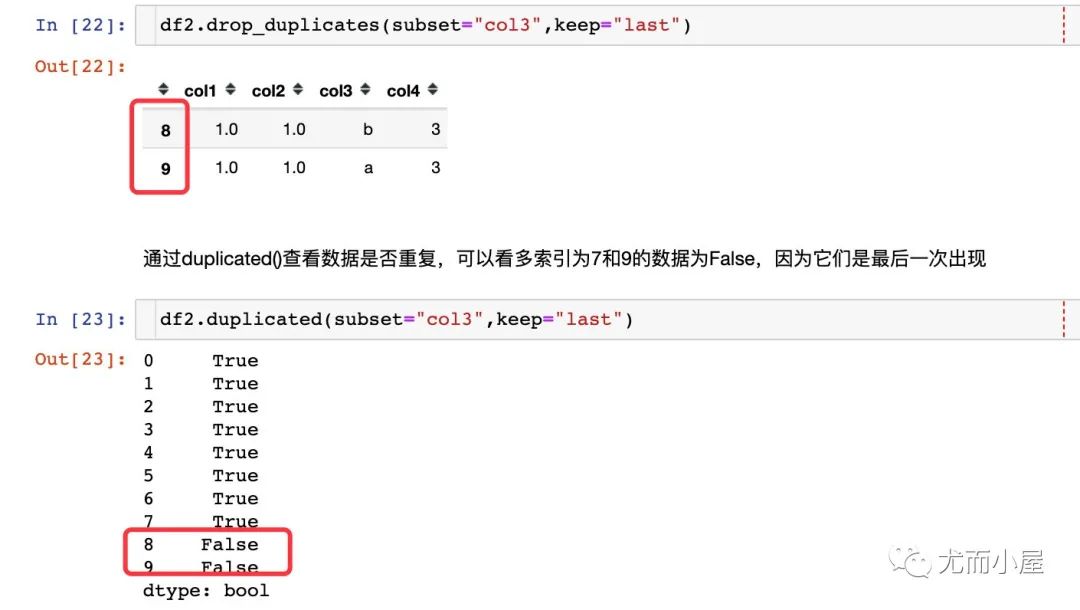
2、keep="last"
通过duplicated()查看数据是否重复,可以看多索引为7和9的数据为False,因为它们是最后一次出现
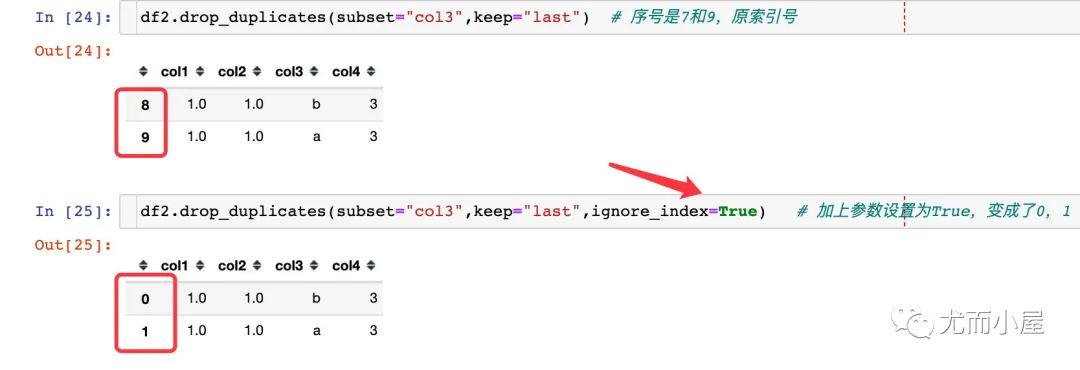
3.5参数ignore_index
该参数表示的是生成数据的索引是原数据的索引还是直接重新排名
3.6参数inplace
如果是使用默认值False:
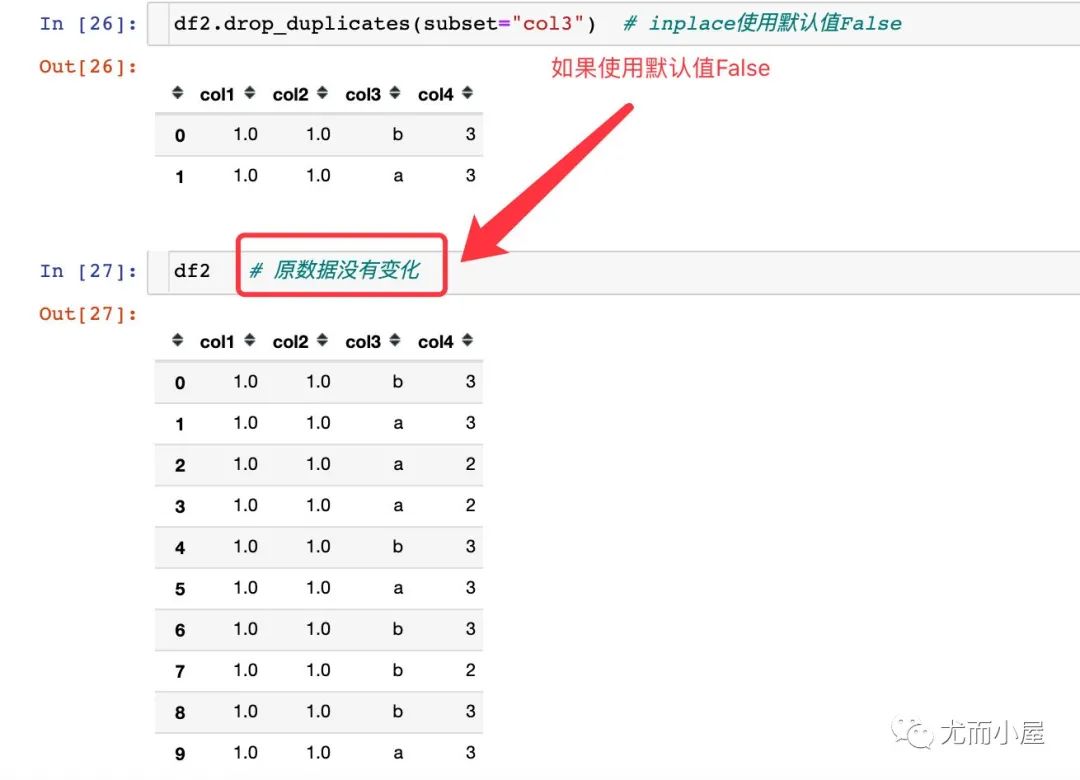
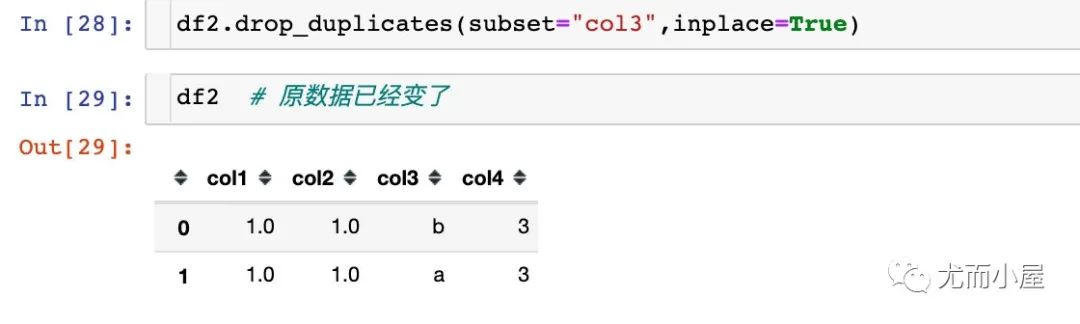
如果inplace使用True,不会生成数据,因为是在原数据的基础上修改的,导致原数据直接变化了:我们直接看df2
四、实战案例
在文章的最开始,我们已经导入了数据,几点需求说明:
每个订单可能存在多个状态,也可能只存在一个 我们想要找出最终的订单状态为“通过”的订单的所有数据
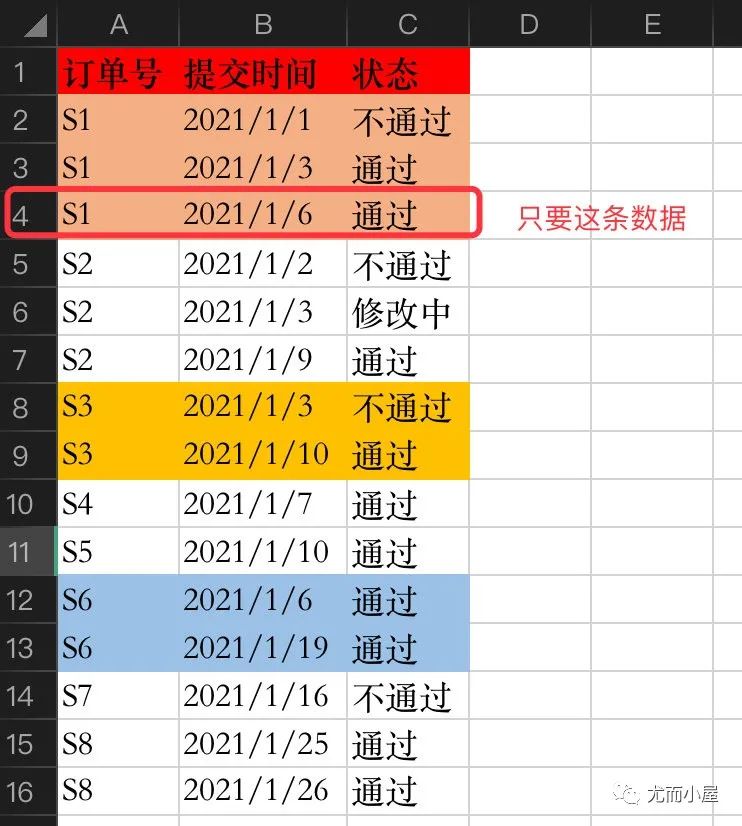
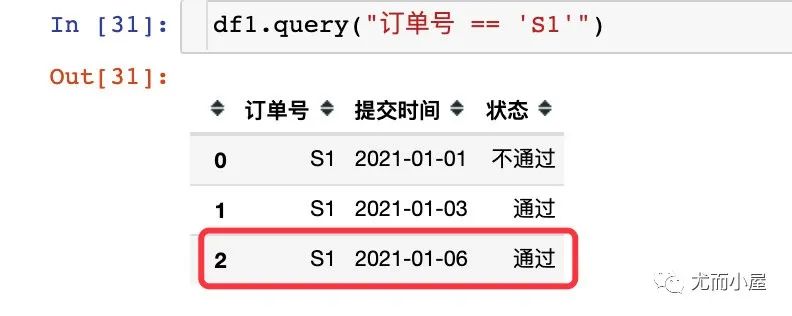
比如订单S1,存在3条状态,有两条是通过的,但是我们只想取出最近的一条通过的数据:2021-01-06
解决步骤1:先找出通过的全部订单,发现只有S7没有通过
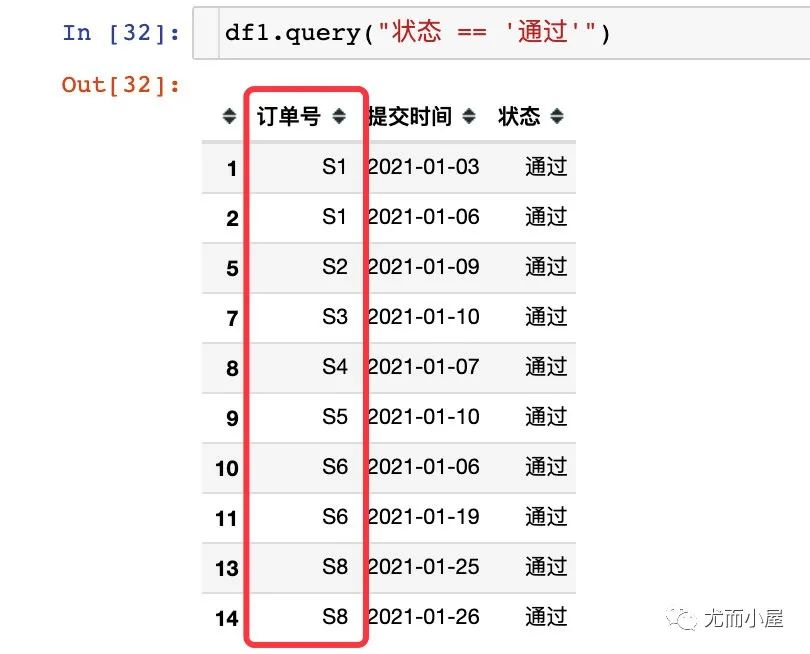
通过下面的代码也能够找出最终是通过的订单:
order_pass = df1.query("状态 == '通过'")["订单号"].unique()
order_pass

解决步骤2:筛选出最终状态为通过的订单信息,下面提供了两种方式

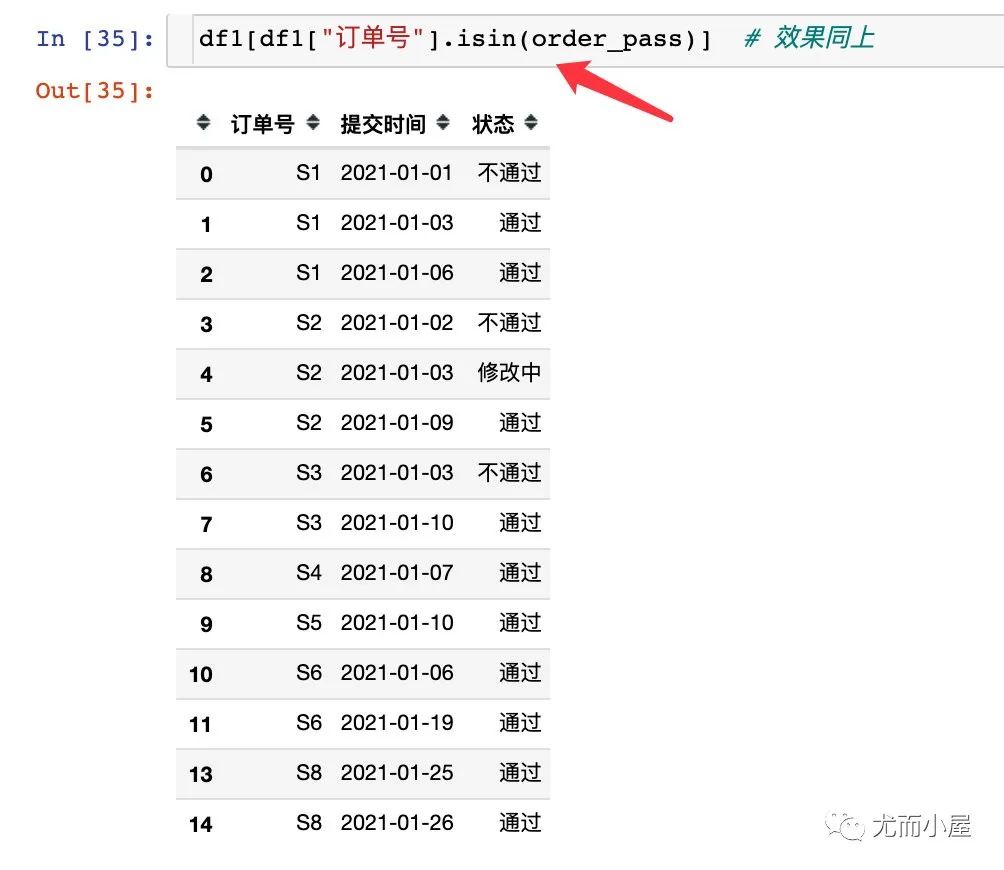
解决步骤3:对df3进行去重即可
df3.drop_duplicates(
subset="订单号", # 根据订单号去重
keep="last", # 保留最后一条
inplace=True, # 原地修改
ignore_index=True # 索引重排
)
df3 # 结果中没有S7

五、Pandas连载文章
Pandas的文章已经形成连载,欢迎关注阅读:
往期精彩回顾 本站qq群851320808,加入微信群请扫码: