
【推荐系统】协同过滤 零基础到入门
文章目录:
1 基于用户user-based
1.1 寻找偏好相似的用户
1.2 皮尔逊相关度
1.3 为相似的用户提供商品
1.4 小结
2 基于物品item-based
3 协同算法的更多描述
4 不同相似度计算的方法
4.1 欧几里得距离
4.2 Pearson-r系数
4.3 向量余弦
4.4 调整余弦
4.5 总结与个人感悟
5 预测用户打分
5.1 加权求和平均
协同过滤推荐算法是诞生最早,最为基础的推荐算法。 算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。
协同过滤算法分为两类:
基于用户的协同过滤算法(user-based collaborative filtering) 基于物品的协同过滤算法(item-based collaborative filtering)
其实我一开始对这个协同过滤 的概念不太了解,直到看了collaborative这个单词的释义,就是两个物体同时出现的频率。
1 基于用户user-based
基于用户的协同过滤算法是通过用户的历史行为数据 发现用户对商品或内容的喜欢,例如(商品的购买,收藏,内容评价或者分享内容等)。根据不同用户对相同商品或者内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户之间进行商品推荐。
换句话说 , 假如A和B用户都购买了同样的三本书,并且都给出了5星好评,那么就认为A和B是同一类用户。然后把A购买的另外一本书推荐给B。
1.1 寻找偏好相似的用户
现在考虑一种最简单的情况,5个用户都购买了两种商品,然后并对商品进行打分,如下图:
最简单的方法就是画图,加入用商品1的评分作为Y轴,商品2的评分作为X轴,那么就可以得到下面的散点图: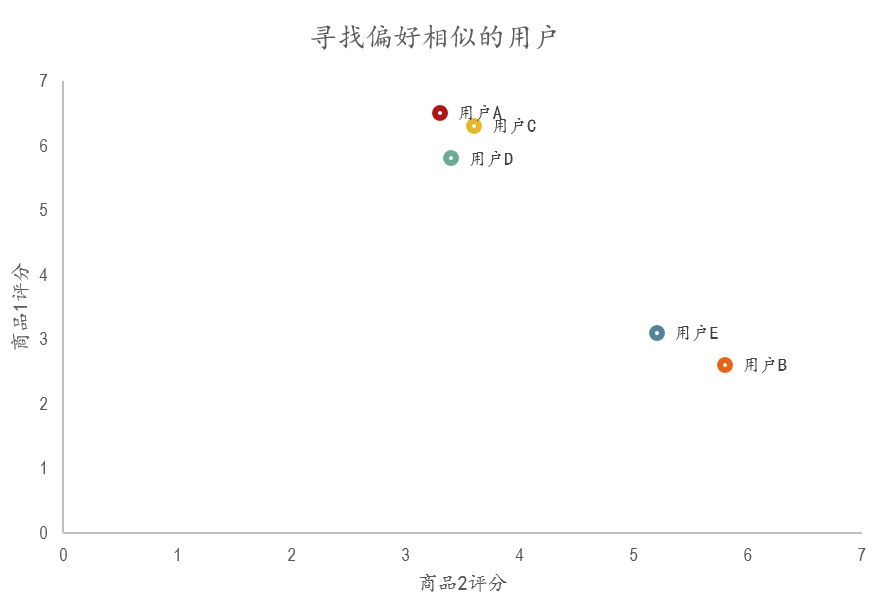
常见的想法可以用欧几里得距离来衡量用户之间的相似度。
1.2 皮尔逊相关度
Pearson correlation coefficient
除了用欧氏距离来衡量,皮尔逊相关度是另一种计算用户间关系的方法。现在考虑下面这一种更加复杂、也更加接近真实场景的数据:
其实呢?皮尔逊相关系数其实就是两个变量之间的协方差和标准差的比值: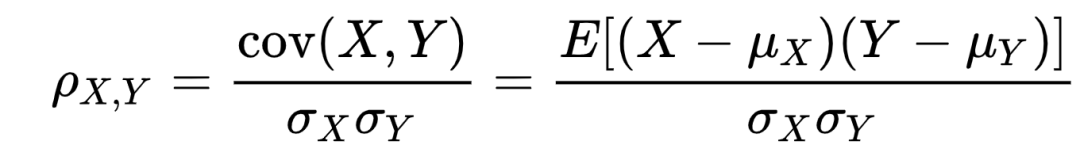
再换一个写法,就是下面这个公式:
对于这个,并不陌生。皮尔逊相关系数在-1到1之间。0表示不相关,1表示极强正相关,-1表示极强负相关。
现在来简单计算一下上面例子中,用户A与用户B之间的皮尔逊相关系数。
剩下的Pearson相关系数如下:
1.3 为相似的用户提供商品
假设我们为用户C推荐商品,先检查相似度列表,发现用户C和D、E的pearson系数较高。所以认为这三个用户有相同的偏好,所以对C推荐D和E买过的商品。但是不能推荐商品1~5,因为这些用户C已经买过了。
现在我们找到了用户D和E买过的其他的商品A,B,C,D,E,F。然后让用户D和E与用户C的相似度作为权重 ,计算他们给这些商品打分的加权分数。然后给C按照加权分数从高到低进行推荐。
1.4 小结
已经讲完了基于用户的协同过滤算法。这个算法依靠用户的历史行为数据来计算相似度,所以是需要一定的数据积累 ,这其中涉及到冷启动问题。对于新网站或者数据量较少的网站,一般会采用基于物品的协同过滤方法。
2 基于物品item-based
其实这个和基于用户的方法很想,就是把商品和用户互换。通过计算不同用户对不同物品的评分获得物品间的关系。然后根据物品间的关系对用户进行相似物品的推荐。
所以这里我们一开始的数据可以写成这个样子:
然后计算出物品之间的相关系数:
假设我们要给用户C推荐商品。
在基于用户的算法中,我们的流程是:推荐给用户C->寻找与用户C相同爱好的用户->寻找这些用户购买的其他商品的加权打分。
现在基于物品的算法中,我们的流程是。发现用户C购买了商品4和5,找到同样购买了4和5商品的其他用户123.然后找到其他用户123购买的新商品A、B、C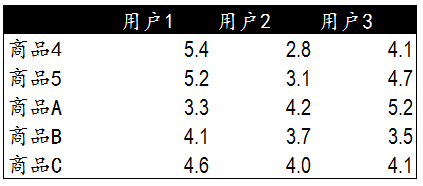
计算得到商品4和5与新商品ABC之间的相关度。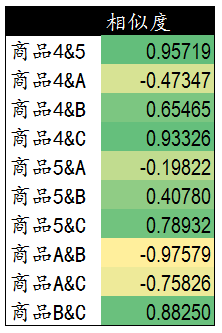
然后进行加权打分排序。
3 协同算法的更多描述
协同算法CF:Collaborative Filtering 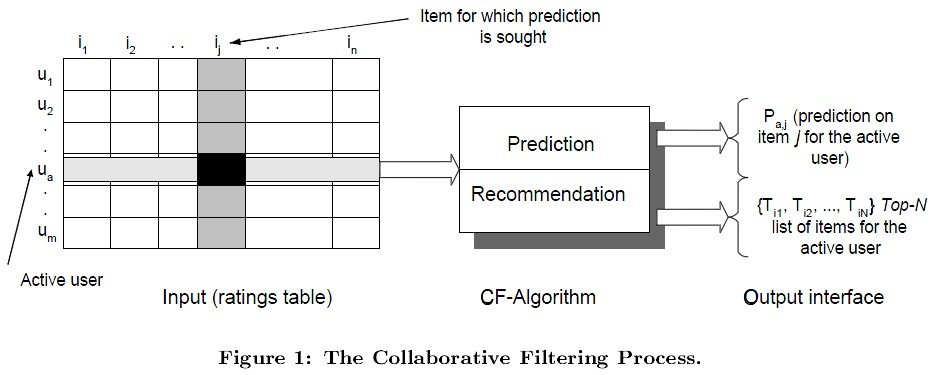
如上图,协同算法中,左边的的矩阵中,m表示样本的数量,n表示商品的数量。矩阵的数值表示用户对某一个商品的喜好程度,分数越高表示越喜欢这个物品。0表示没有买过该商品。
【整个协同过滤包括两个过程】
预测过程 :预测用户对没有购买过的商品的可能打分值; 推荐过程 :根据预测阶段的姐u共推荐用户最可能喜欢的TopN个商品。
【User-based & Item-based】
User-based的基本思想就是用户A喜欢物品a,用户B喜欢物品abc,用户C喜欢物品ac,那么使用以相关系数为衡量的最近邻算法,可以把用户C当成用户A的最近的邻居,而从推荐给A商品c。
Item-based的基本思想是现根据历史数据计算物品之间的相似性,然后把用户喜欢的相类似的物品推荐给用户。因为我们知道喜欢a的用户也喜欢c,所以推断出物品a和c非常相似,这样可以给购买过商品a的用户推荐商品c。
【User-based缺陷】
数据稀疏性。一个商场中一般有非常多的物品,而一个用户可能只够买过其中的1个商品,这样的话不同用户之间的物品重叠性非常低,从而导致无法找到一个用户的邻居(因为这个用户与其他所有用户的距离都相等,想象一下one-hot编码)。 算法扩展性。最近邻算法的计算量会随着用户和物品数量的增加而增加,大数据的话浪费算力。 冷启动。一开始没有历史数据的话,无法使用这种方法进行推荐。
而Item-based的话,可以预先在线下先计算冲不同商品之间的相似度,然后把结果存在表中,推荐的时候直接查表。
4 不同相似度计算的方法
4.1 欧几里得距离
这个就是差值平方的和的开方。
4.2 Pearson-r系数
这个就是之前详细讲解的相关系数。
4.3 向量余弦
通过计算两个向量之间的夹角来计算物品的相似度。因为不同的用户可能有不同的性格,可能有一个人给什么东西打分都很高,另外一个人给什么东西打分都低,这样的话使用Pearson系数会判定这两个人偏好不同,而向量余弦会更加关注用户给不同商品打分的相对情况。 (PS:其中分子为两个向量的内积,即两个向量相同位置的数字相乘。)
(PS:其中分子为两个向量的内积,即两个向量相同位置的数字相乘。)
4.4 调整余弦
余弦的优势在于关注相对打分,但是这也是他的缺点。女生相对于篮球,更喜欢足球一些。男生也是如此。难道我们能说男生女生的喜好一致吗?我们是不能推荐运动用品给这样的女生的。然而余弦相似度看不到这些,因为它只关注相对打分。
假设女生给篮球足球打分(1,2),男生打分(8,9)
【cosine】
而Adjective Cosine是让数值减去物品打分的均值,让低于平均水平的打分变成负数。这下子向量的方向一下有一个巨大的改变。篮球的均分4.5,足球的均分5.5
【Adjecitve Cosine】
一下子就把差距体现出来了。
4.5 总结与个人感悟
可以看的出来,余弦相似度存在一定的问题,所以建议使用调整余弦相似度与Pearson。
【Adjective Cosine VS Pearson】
Adjective Cosine中均值是所有用户对同一商品打分的均值; Pearson中的均值是同一用户对所有商品打分的均值。
5 预测用户打分
之前提到了预测过程(预测用户给为打分的商品的打分情况。)
5.1 加权求和平均
对用户已经打分的物品的分数进行加权求和,而权值自然是各个物品与预测物品之间的相似度,然后再除以总权重值得和即可。
- END -往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):