如果把指标⽐喻成⼀棵树上的果实,那模型就是这棵⼤树的躯⼲,想让果实结得好,必须让树⼲变得粗壮。真实场景举例:
⼤多数公司的分析师会结合业务做⼀些数据分析(需要⽤到⼤量的数据),通过报表的⽅式服务于业务部⻔的运营。但是在数据中台构建之前,分析师经常发现⾃⼰没有可以复⽤的数据,不得不使⽤原始数据进⾏清洗、加⼯、计算指标。由于他们⼤多是⾮技术专业出⾝,写的SQL质量⽐较差,甚⾄⻅过5层以上的嵌套。这种SQL对资源消耗⾮常⼤,会造成队列阻塞,影响其他数仓任务,会引起数据开发的不满。数据开发会要求收回分析师的原始数据读取权限,分析师⼜会抱怨数仓数据不完善,要啥没啥,⼀个需求经常要等⼀周甚⾄半个⽉。分析师与数据开发的⽭盾从此开始。这个⽭盾的根源在于数据模型⽆法复⽤,数据开发是烟囱式的,每次遇到新的需求,都从原始数据重新计算,⾃然耗时。⽽要解决这个⽭盾,就要搞清楚我们的数据模型应该设计成什么样⼦。
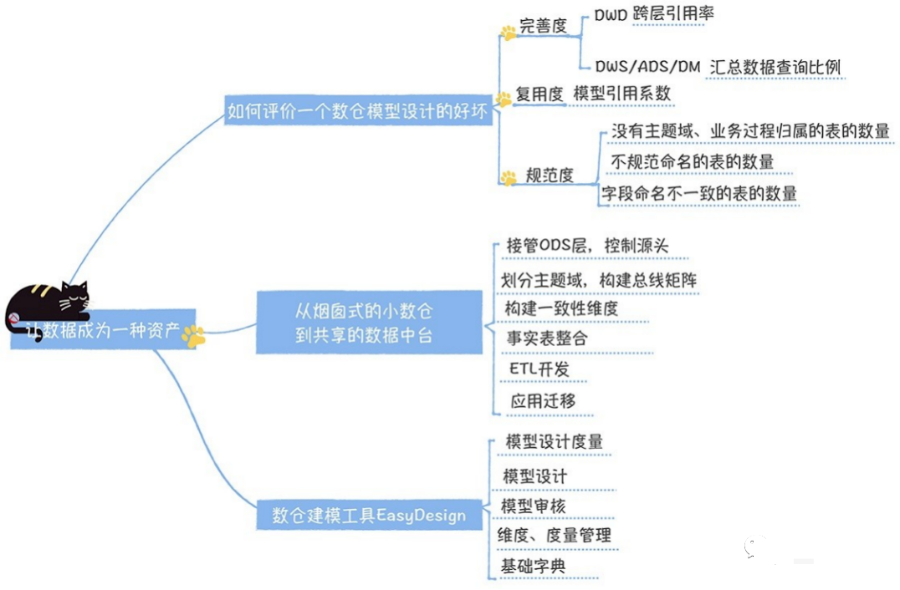
01 什么才是⼀个好的数据模型设计?
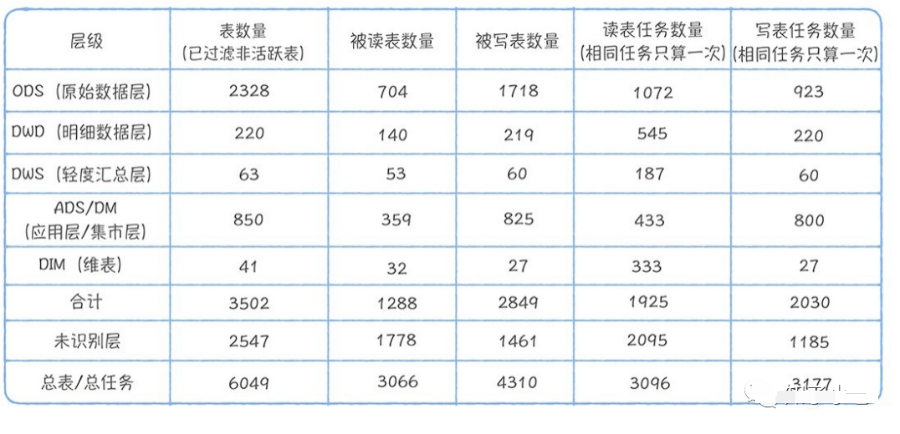
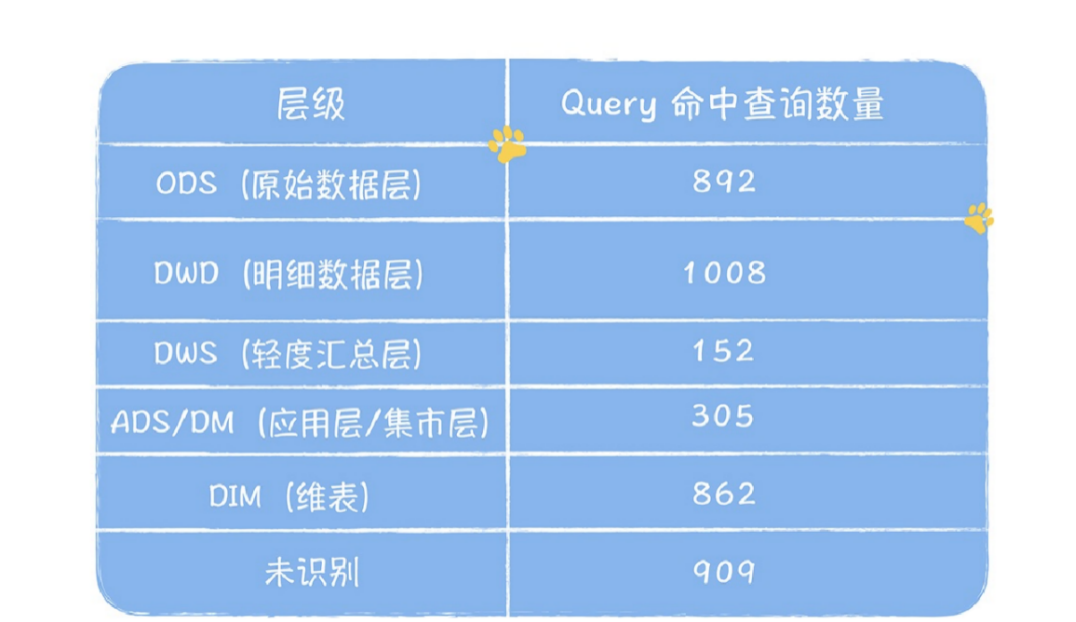
来看⼀组数据,这两个表格是基于元数据中⼼提供的⾎缘信息,分别对⼤数据平台上运⾏的任务和分析查询(Ad-hoc)进⾏的统计。下图是数仓分层架构图,⽅便回忆数据模型分层的设计架构:表1中有2547张未识别分层的表,占总表6049的40%,它们基本没办法复⽤。重点是在已识别分层的读表任务中,ODS:DWD:DWS:ADS的读取任务分别是1072:545:187:433,直接读取ODS层任务占这四层任务总和的47.9%,这说明有⼤量任务都是基于原始数据加⼯,中间模型复⽤性很差。在已识别的分层的查询中,ODS:DWD:DWS:ADS的命中的查询分别是892:1008:152:305,有37.8%的查询直接命中ODS层原始数据,说明DWD、DWS、ADS层数据建设缺失严重。尤其是ADS和DWS,查询越底层的表,就会导致查询扫描的数据量会越⼤,查询时间会越⻓,查询的资源消耗也越⼤,使⽤数据的⼈满意度会低。最后,进⼀步对ODS层被读取的704张表进⾏分解,发现有382张表的下游产出是DWS,ADS,尤其是ADS达到了323张表,占ODS层表的⽐例45.8%,说明有⼤量ODS层表被进⾏物理深加⼯。
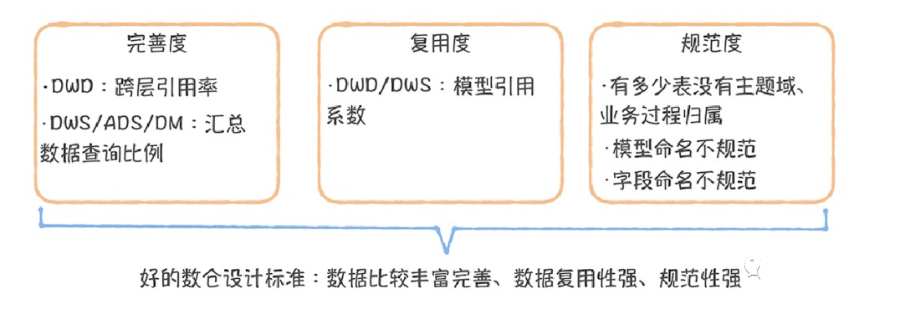
通过上⾯的分析,我们似乎已经找到了⼀个理想的数仓模型设计应该具备的因素,那就是“数据模型可复⽤,完善且规范”。
DWD层完善度:衡量DWD层是否完善,最好看ODS层有多少表被DWS/ADS/DM层引⽤。因为DWD以上的层引⽤的越多,就说明越多的任务是基于原始数据进⾏深度聚合计算的,明细数据没有积累,⽆法被复⽤, 数据清洗、格式化、集成存在重复开发。因此,我提出⽤跨层引⽤率指标衡量DWD的完善度。跨层引⽤率:ODS层直接被DWS/ADS/DM层引⽤的表,占所有ODS层表(仅统计活跃表)⽐例。跨层引⽤率越低越好,在数据中台模型设计规范中,要求不允许出现跨层引⽤,ODS层数据只能被DWD引⽤。DWS/ADS/DM层完善度:考核汇总数据的完善度,主要看汇总数据能直接满⾜多少查询需求(也就是⽤汇总层数据的查询⽐例衡量)。如果汇总数据⽆法满⾜需求,使⽤数据的⼈就必须使⽤明细数据,甚⾄是原始数据。汇总数据查询⽐例:DWS/ADS/DM层的查询占所有查询的⽐例。
要明确的是,这个跟跨层引⽤率不同,汇总查询⽐例不可能做到100%,但值越⾼,说明上层的数据建设越完善,对于使⽤数据的⼈来说,查询速度和成本会减少,⽤起来会更爽。
03 如何衡量复用度?
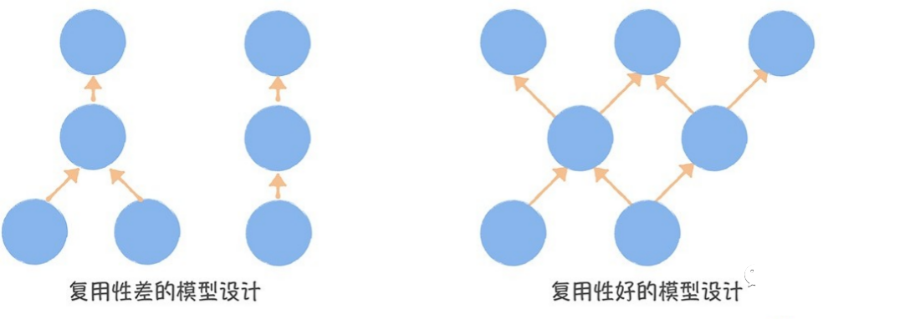
数据中台模型设计的核⼼是追求模型的复⽤和共享,通过元数据中⼼的数据⾎缘图,可以看到,⼀个⽐较差的模型设计,⾃下⽽上是⼀条线。⽽⼀个理想的模型设计,它应该是交织的发散型结构。⽤模型引⽤系数作为指标,衡量数据中台模型设计的复⽤度。引⽤系数越⾼,说明数仓的复⽤性越好。模型引⽤系数:⼀个模型被读取,直接产出下游模型的平均数量。
⽐如⼀张DWD层表被5张DWS层表引⽤,这张DWD层表的引⽤系数就是5,如果把所有DWD层表(有下游表的)引⽤系数取平均值,则为DWD层表平均模型引⽤系数,⼀般低于2⽐较差,3以上相对⽐较好(经验值)。
04 如何衡量规范度?
表1中,超过40%的表都没有分层信息,在模型设计层⾯,这显然是不规范的。除了看这个表有没有分层,还要看它有没有归属到主题域(例如交易域)如果没有归属主题域,就很难找到这张表,也⽆法复⽤。其次,要看表的命名。拿stock这个命名为例,当看到这个表时,知道它是哪个主题域、业务过程?是全量数据的表,还是每天的增量数据?总的来说,通过这个表名获取的信息太有限了。⼀个规范的表命名应该包括主题域、分层、表是全量快照,还是增量等信息。除此之外,如果在表A中⽤⼾ID的命名是UserID,在表B中⽤⼾ID命名是ID,就会对使⽤者造成困扰,这到底是不是⼀个东西。所以我们要求相同的字段在不同的模型中,它的命名必须是⼀致的。
经验和建议:
1. 可以拿着这些指标去评估⼀下,⾃⼰的数仓现状如何。
2. 然后制订⼀些针对性的改进计划,⽐如把这些不规范命名的表消灭掉,把主题域覆盖的表⽐例提⾼到90%以上。3. 在尝试完⼀段时间的模型重构和优化后,再拿着这些指标去测⼀测是不是真的变好了。模型重构到底对数据建设有多少帮助?有没有⼀些量化的指标可以衡量?基于上面的知识已经可以很好回答这两个问题了。
05 如何从烟囱式的小数仓到共享的数据中台?
建设数据中台本质就是构建企业的公共数据层,把原先分散的、烟囱式的、杂乱的⼩数仓,合并成⼀个可共享、可复⽤的数据中台。
第⼀:接管ODS层,控制源头
ODS是业务数据进⼊数据中台的第⼀站,是所有数据加⼯的源头,控制住源头,才能从根本上防⽌⼀个重复的数据体系的出现。数据中台团队必须明确职责,全⾯接管ODS层数据,从业务系统的源数据库权限⼊⼿,确保数据从业务系统产⽣后进⼊数据仓库时,只能在数据中台保持⼀份。这个可以跟业务系统数据库管理者达成⼀致,只有中台团队的账号才能同步数据。ODS层表的数据必须和数据源的表结构、表记录数⼀致,⾼度⽆损,对于ODS层表的命名采⽤ODS_业务系统数据库名_业务系统数据库表名⽅式,⽐如ods_warehous_stock,warehous是业务系统数据库名,stock是该库下⾯的表名。
第⼆:划分主题域,构建总线矩阵
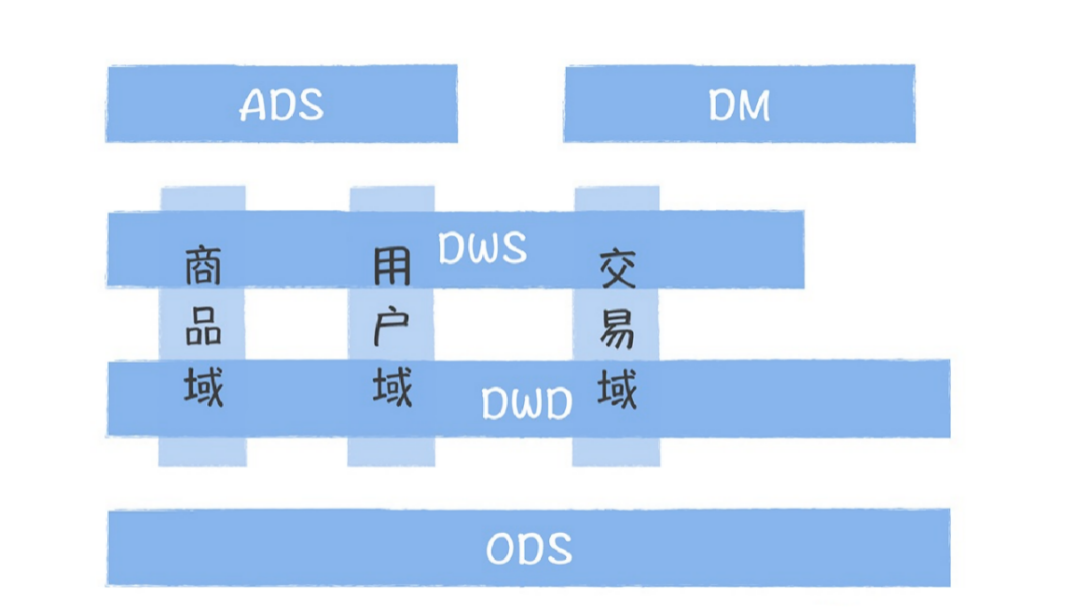
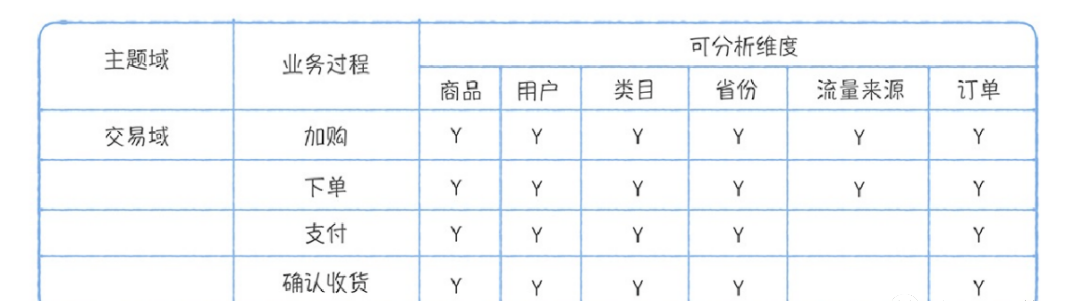
主题域是业务过程的抽象集合。可能这么讲,稍微有点⼉抽象,但其实业务过程就是企业经营过程中⼀个个不可拆分的⾏为事件,⽐如仓储管理⾥⾯有⼊库、出库、发货、签收,都是业务过程,抽象出来的主题域就是仓储域。主题域划分要尽量涵盖所有业务需求,保持相对稳定性,还具备⼀定的扩展性(新加⼊⼀个主题域,不影响已经划分的主题域的表)。主题域划分好以后,就要开始构建总线矩阵,明确每个主题域下的业务过程有哪些分析维度,举个例⼦:
第三:构建⼀致性维度。
售后团队的投诉⼯单数量有针对地区的分析维度,⽽配送团队的配送延迟也有针对地区的分析维度,你想分析因为配送延迟导致的投诉增加,但是两个地区的分析维度包含内容不⼀致,最终会导致⼀些地区没办法分析。所以我们构建全局⼀致性的维表,确保维表只存⼀份。维度统⼀的最⼤的难题在于维度属性(如果维度是商品,那么商品类别、商品品牌、商品尺⼨等商品的属性,我们称为维度属性)的整合。是不是所有维度属性都要整合到⼀个⼤的维表中,也不⻅得,我给你⼏个 建议。1. 公共维度属性与特有维度属性拆成两个维表。在⾃营平台中,通常也会有⼀些第三⽅的商家⼊驻,但是数 量很少。⼤部分商品其实都没有店铺的属性,这种情况,就不建议将店铺和商品的其他维度属性,⽐如商品类别、品牌设计成⼀个维表。2. 产出时间相差较⼤的维度属性拆分单独的维表,⽐如有些维度属性产出时间在凌晨2点,有些维度属性产出时间在凌晨6点,那2点和6点的就可以拆成两个维表,确保核⼼维表尽早产出。
3. 出于维表稳定性产出的考虑,你可以将更新频繁的和变化缓慢的进⾏拆分,访问频繁的和访问较少的维表 进⾏拆分。
对于维表的规范化命名,建议⽤“dim_主题域_描述_分表规则”⽅式。分表可以这样理解:⼀个表存 储⼏千亿⾏记录实在是太⼤了,所以需要把⼀个表切割成很多⼩的分区,每天或者每周,随着任务被调度,会⽣成⼀个分区。常⻅的分区规则(用时查询)。
第四:事实表整合
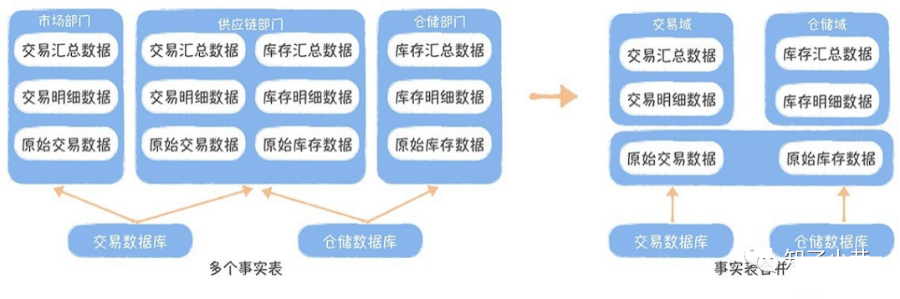
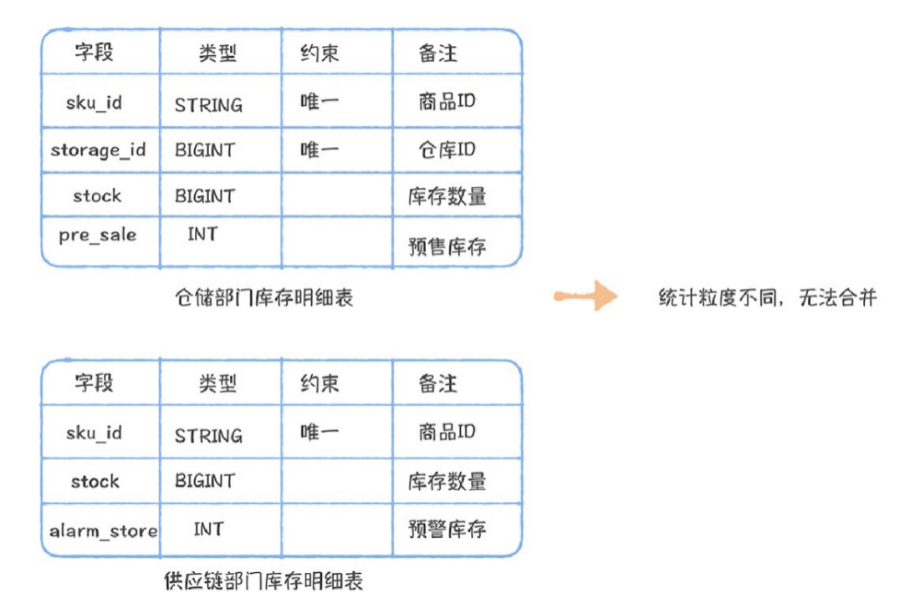
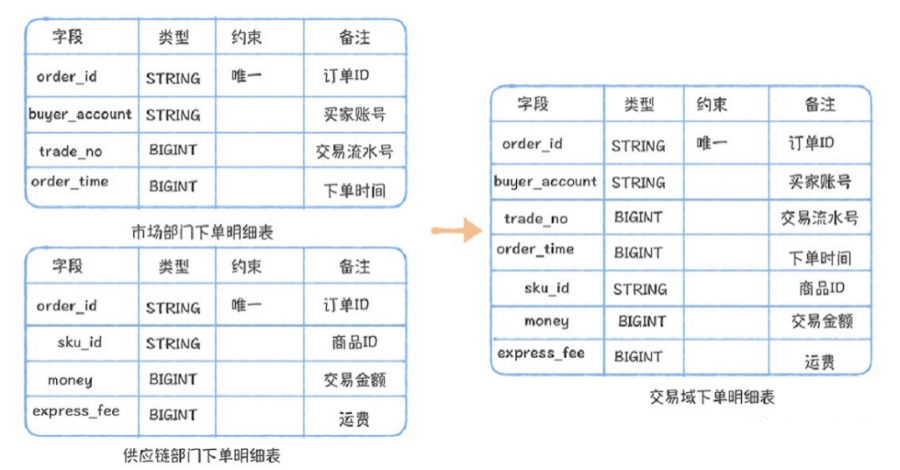
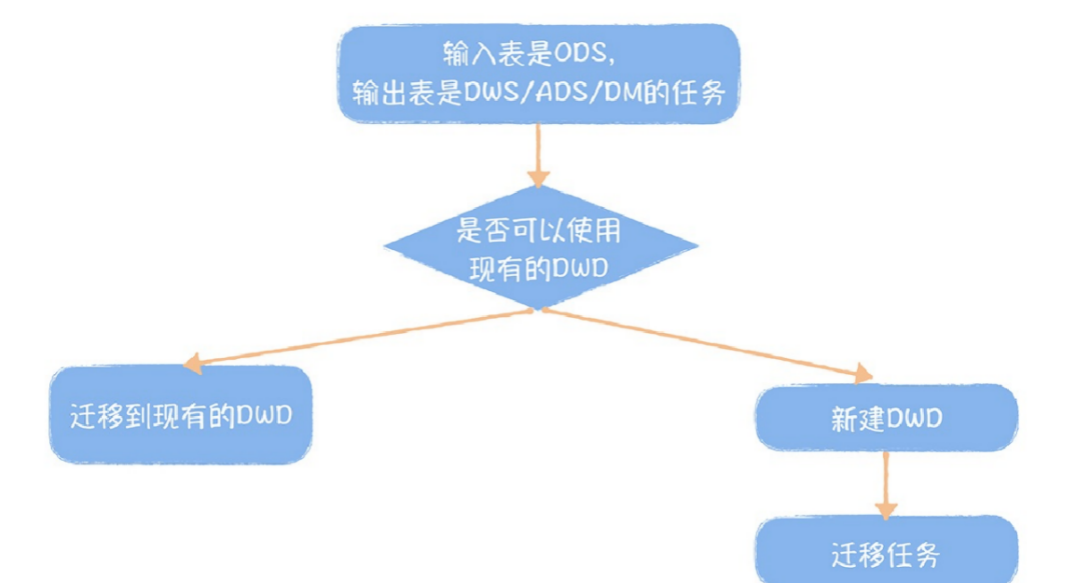
事实表整合遵循的最基本的⼀个原则是,统计粒度必须保持⼀致,不同统计粒度的数据不能出现在同在数据中台构建前,供应链部⻔、仓储部⻔和市场部⻔都有⼀些重复的事实表,我们需要将这些重复的内容进⾏去除,按照交易域和仓储域,主题域的⽅式进⾏整合。对于仓储部⻔和供应链部⻔都有的库存明细表,因为仓储部⻔的统计粒度是商品加仓库,⽽供应链部⻔的只有商品,所以原则上两个表是不能合并,⽽是应该独⽴存在。对于市场部⻔和供应链部⻔的两张下单明细表,因为统计粒度都是订单级别,都归属于交易域下的下单业务过程,所以可以合并为⼀张事实表。除此之外,还应该考虑将不全的数据补⻬。对于ODS层直接被引⽤产出DWS/ADS/DM层的任务,通过⾎缘,找到任务清单,逐个进⾏拆解。没有ODS对应的DWD的,应该⽣成DWD表,对于已经存在的,应该迁移任务,使⽤DWD层表。DWD/DWS/ADS/DM的命名规则适合采⽤“[层次][主题][⼦主题][内容描述][分表规则]”的命名⽅式。
第五:模型开发。
模型设计完成后,就进⼊模型开发阶段,需要注意的点:1. 所有任务都必须严格配置任务依赖,如果没有配置任务依赖,会导致前⼀个任务没有正常产出数据的情况下,后⼀个任务被调度起来,基于错误的数据空跑,浪费资源,同时增加了排查故障的复杂度;2. 任务中创建的临时表,在任务结束前应该删除,如果不删除,会发现有⼤量的临时表存在,占⽤空间;4. ⽣命周期的管理,对于ODS和DWD,⼀般尽可能保留所有历史数据,对于DWS/ADS/DM需要设置⽣命周期,7〜30天不等;5. DWD层表宜采⽤压缩的⽅式存储,可⽤lzo压缩。
第六:应⽤迁移
最后⼀步就是应⽤的迁移,这个过程的核⼼是要注意数据的⽐对,确保数据的完全⼀致,然后进⾏应⽤迁移,删除⽼的数据表。总的来说,建设数据中台不是⼀⼝⽓就能吃成⼀个胖⼦,它的建设往往是滚雪球的⽅式,随着⼀个个应⽤的迁移,中台的数据也越来越丰满,发挥的价值也越来越⼤。
06 数仓建模⼯具EasyDesign
上述步骤的实现,离不开⼀个好⽤的⼯具作为⽀撑,为了规范化数据模型的设计,研发了EasyDesign的模型设计产品,让这些流程实现系统化管理。EasyDesign的设计思路和功能:https://bigdata.163yun.com/product/easydesignEasyDesign构建于元数据中⼼之上,通过API调⽤元数据中⼼的数据⾎缘接⼝,结合数仓模型设计的指标,给出了模型设计度量。EasyDesign按照主题域、业务过程、分层的⽅式管理所有的模型。它还提供了维度、度量和字段基础字典的管理,同时具备模型设计审批流程的控制。
07 总结
本文主要了解了数据中台的模型设计。从确⽴设计⽬标,到通过⼀系列步骤,将⼀个个分散的、杂乱的、烟囱式的⼩数仓逐步规整到⼀个可复⽤、可共享的数据中台,最后通过产品化的⽅式实现系统化的管理。最后,再强调⼏个点:1. 完善度、复⽤度和规范度构成了衡量数据中台模型设计的度量体系,可以帮助你评估数仓设计的好坏。2. 维度设计是维度建模的灵魂,也是数据中台模型设计的基础,维度设计的核⼼是构建⼀致性维度。
3. 事实表的统计粒度必须保持⼀致,不同统计粒度的数据不能出现在同⼀个事实表中。
数据中台的构建往往需要花费半年甚⾄⼀年以上的时间,但是数据中台建成后,对研发效率的提升效果⾮常明显,在⽹易电商业务中,中台构建后相⽐构建前,数据需求的平均交付时间从⼀周缩短到3天内,需求响应速度的提升,为企业运营效果提升提供了数据⽀撑。
思考:
在数据中台实际实施落地的过程中,数据团队不但要建设公共数据层,形成数据中台,还要承担着巨⼤的新需求的压⼒。⽽且,往往需求的优先级都⾼于建设公共数据层的优先级,导致中台建设的进度难以保障。 1、先满⾜需求(活下去),再研发公共数据层(构建美好未来)。
2、获得⾼层领导的⽀持,以获得更多的研发资源。
3、在满⾜业务需求的过程中,根据业务需求不断对公共数据层进⾏迭代和优化。
4、随着时间的推移,越来越多的⽇常业务需求可以⽤公共数据层(中台来完成)。
5、⽇常业务需求开发和公共数据层构建是相互促进的循环。
另外,为了保障数据中台的推进速度,可以尝试成⽴专⼈团队,这些⼈的⽬标明确就是中台构建,模型的重构和整合,指标的梳理。这些⼈不接业务需求,这样可以避免⽇常业务需求对数据团队的中台建设的⼲扰;合理设置KPI和KPI权重,给予充足的中台建设的动⼒。
推荐阅读:
世界的真实格局分析,地球人类社会底层运行原理
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)
亿级(无限级)并发,没那么难
论数字化转型——转什么,如何转?
华为干部与人才发展手册(附PPT)
企业10大管理流程图,数字化转型从业者必备!
【中台实践】华为大数据中台架构分享.pdf
华为的数字化转型方法论
华为如何实施数字化转型(附PPT)
超详细280页Docker实战文档!开放下载
华为大数据解决方案(PPT)