
通俗易懂谈强化学习之Q-Learning算法实战

本文约3500字,建议阅读7分钟 本篇实战讲解强化学习,所有的实战代码可以自行下载运行。
01 强化学习
上一篇帖子
http://mp.weixin.qq.com/s?__biz=MzIyNjM2MzQyNg==&mid=2247601164&idx=1&sn=f04f1ce25158509cb632e724bf735809&chksm=e8729d41df051457e501db18fa649400e430515326be92c29c4f2ee58017df905912de7d969b&scene=21#wechat_redirect
02 Pacman Project讲解
03 Q-Learning介绍
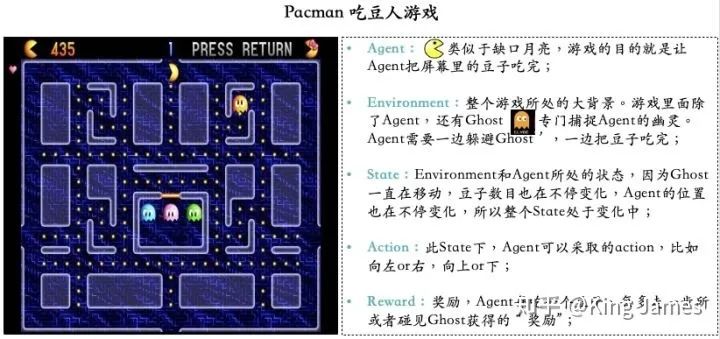
Agent(智能体): 强化学习训练的主体就是Agent:智能体。Pacman中就是这个张开大嘴的黄色扇形移动体; Environment(环境): 整个游戏的大背景就是环境;Pacman中Agent、Ghost、豆子以及里面各个隔离板块组成了整个环境; State(状态): 当前 Environment和Agent所处的状态,因为Ghost一直在移动,豆子数目也在不停变化,Agent的位置也在不停变化,所以整个State处于变化中;State包含了Agent和Environment的状态; Action(行动): 基于当前的State,Agent可以采取哪些action,比如向左or右,向上or下;Action是和State强挂钩的,比如上图中很多位置都是有隔板的,很明显Agent在此State下是不能往左或者往右的,只能上下; Reward(奖励):Agent在当前State下,采取了某个特定的action后,会获得环境的一定反馈就是Reward。这里面用Reward进行统称,虽然Reward翻译成中文是“奖励”的意思,但其实强化学习中Reward只是代表环境给予的“反馈”,可能是奖励也可能是惩罚。比如Pacman游戏中,Agent碰见了Ghost那环境给予的就是惩罚。
Q-Value(State, Action): Q-value是由State和Action组合在一起决定的,这里的Value不是Reward,Reward是Value组成的一部分,具体如何生成Q-value下面会单独介绍。实际的项目中我们会存储一张表,我们叫它Q表。key是(state, action), value就是对应的Q-value。每当agent进入到某个state下时,我们就会来这张表进行查询,选择当前State下对应Value最大的Action,执行这个action进入到下一个state,然后继续查表选择action,这样循环。Q-Value的价值就在于指导Agent在不同state下选择哪个action。
3.1 Bellman 方程
3.2 贝尔曼方程的Q-Value版


04 Q-Learning实战
4.1 预热
python pacman.py -p RandomAgent -n 14.2 Q-Learning算法训练
State:game.py文件已经将如何获取Agent当前的State定义成了Class,直接引用即可; Action:game.py文件已经将Agent在当前State可以采取的Action定义成了Class,直接引用即可;(感兴趣的同学可以自己打开文件查看代码,核心就是建立一个坐标系,然后确定挡板、Ghost、豆子、Agent的位置,然后进行判断和数学表达。) 参数设置:学习率alpha我们设置为0.2,折扣率gamma设置为0.8,最终训练完我们让Pacman运行numTraining=10次查看效果,同时这里面有一个探索率epsilon = 0.05。这就是上一篇介绍的EE问题,我们不能光让Agent去执行Q-value最大的action,同时我们也需要让Pacman有一定的探索。


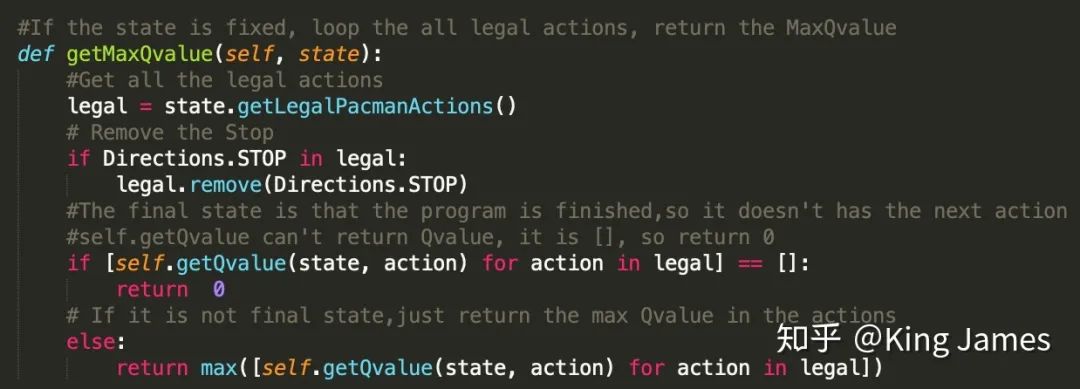
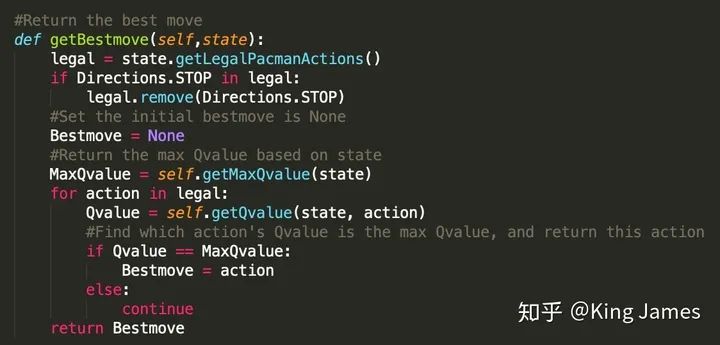
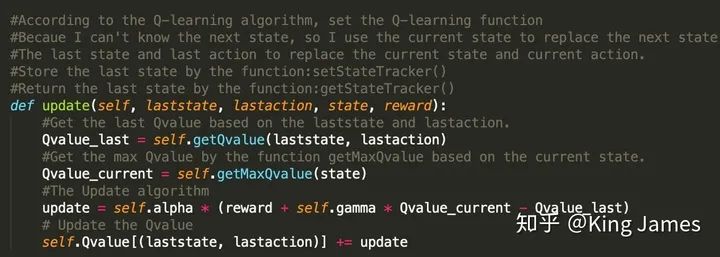
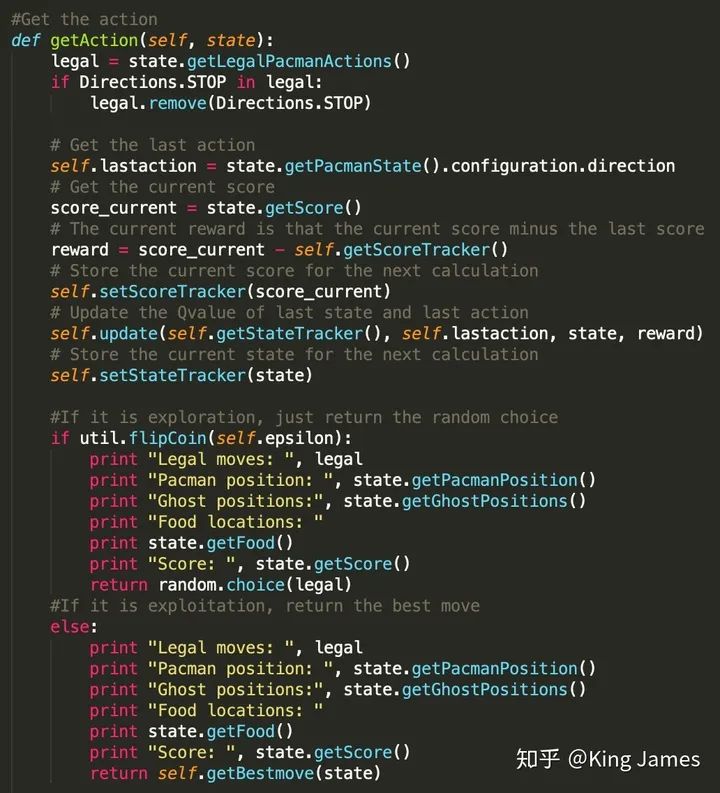
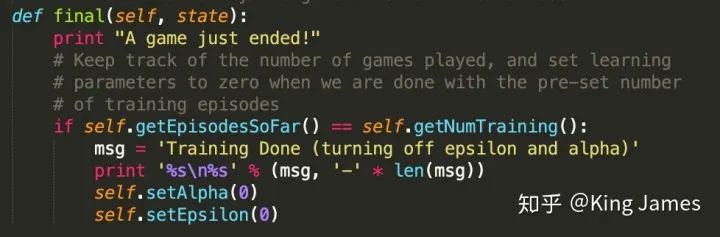
python pacman.py -p QLearnAgent -x 2000 -n 2010 -l smallGrid下图是训练时打印的message;


编辑:王菁
校对:龚力
评论