
Pandas 对数值进行分箱操作的4种方法总结对比

来源:DeepHub IMBA 本文约1500字,建议阅读5分钟
我们将讨论使用 python Pandas 库对数值进行分箱的 4 种方法。

import pandas as pd # version 1.3.5import numpy as npdef create_df():df = pd.DataFrame({'score': np.random.randint(0,101,1000)})return dfcreate_df()df.head()

1、between & loc
left:左边界 right:右边界 inclusive:要包括哪个边界。可接受的值为 {“both”、“neither”、“left”、“right”}。
A: (80, 100] B: (50, 80] C: [0, 50]
df.loc[df['score'].between(0, 50, 'both'), 'grade'] = 'C'df.loc[df['score'].between(50, 80, 'right'), 'grade'] = 'B'df.loc[df['score'].between(80, 100, 'right'), 'grade'] = 'A'
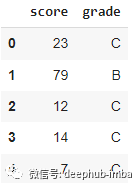
df.grade.value_counts()
2、cut
x:要分箱的数组。必须是一维的。 bins:标量序列:定义允许非均匀宽度的 bin 边缘。 labels:指定返回的 bin 的标签。必须与上面的 bins 参数长度相同。 include_lowest: (bool) 第一个区间是否应该是左包含的。
bins = [0, 50, 80, 100]labels = ['C', 'B', 'A']df['grade'] = pd.cut(x = df['score'], bins = bins, labels = labels, include_lowest = True)
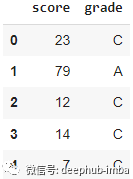
df.grade.value_counts()3、qcut
df['grade'], cut_bin = pd.qcut(df['score'], q = 3, labels = ['C', 'B', 'A'], retbins = True)df.head()
print (cut_bin)>> [ 0. 36. 68. 100.]
C:[0, 36] B:(36, 68] A:(68, 100]
df.grade.value_counts()
4、value_counts
df['score'].value_counts(bins = 3, sort = False)

df['score'].value_counts(bins = [0,50,80,100], sort = False)

总结
评论