
前端质量体系之纸上谈兵
枪炮一响,黄金万两。故障一出,一年白干。
1. 背景
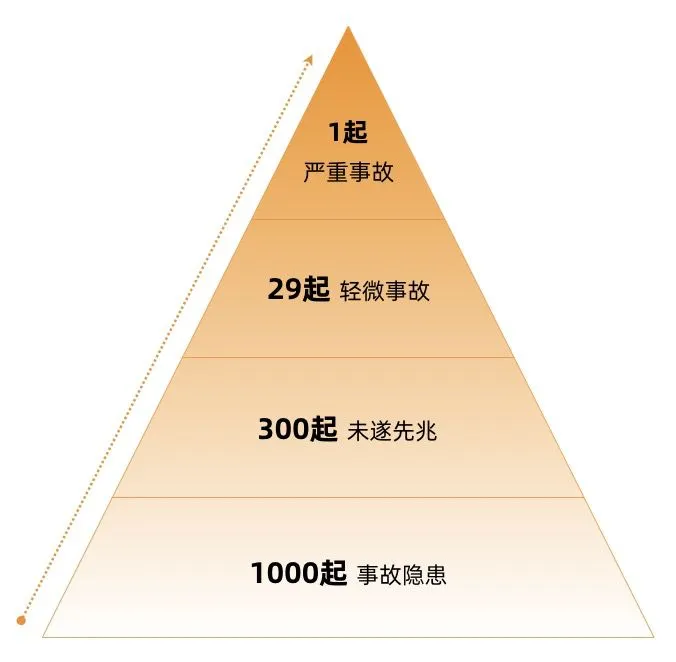
海恩法则指出:每一起严重事故的背后,必然有 29 次轻微事故和 300 起未遂先兆以及 1000 起事故隐患。
在日常开发工作中,即使我们什么安全措施也不做,好像也基本不会碰到特别严重的线上故障。大部分都是一些小的线上问题,比如样式错乱、文本错误、次按钮不能点击等等。这些问题发现之后,修一下,好像也就过去了,毕竟影响面很小。
但殊不知严重的故障往往就隐藏在这一起一起小的隐患中。
如果我问你:「你负责的系统今年会出现严重事故吗?」
应该没有人敢 100% 保证吧?可能我们会说「有概率,但概率很小」
根据墨菲定律:凡事只要有可能会出错,那就一定会出错。
假如每个系统每年有千分之一的可能性出现严重线上故障,那 1000 个系统出现一次线上故障的概率就是 100% 了。
这个故障有多严重,资损多少,影响用户面有多广,谁也没法预测。
我们每个人都坐在炸弹上,什么时候爆炸,威力有多大,谁也不知道,有可能直接把我们崩回家,也可能直接把公司炸没了。
这不,2021 年 2 月,微盟公司的炸弹,直接炸掉了几十亿。
1.1 微盟事件
2020 年 2 月 23 日 18 时 56 分,微盟研发中心运维部运维人员贺某通过个人虚拟专用网登入公司内网跳板机,删除了微盟 SAAS 业务服务主备数据库(但没有做数据覆盖,否则数据不可能找回)。
此次事件修复时间长达 6 天,300 万商铺无法正常营业,微盟公司直接赔付 1.5 亿,股票下跌约 30 亿,当事人判刑 6 年。
万幸的是数据恢复回来了,如果数据恢复不回来,公司应该会直接倒闭。一个炸弹,直接炸掉了公司半条命。
员工数据库权限过大,有删库隐患的问题,肯定不止微盟一家。只是微盟成为天选之子,炸弹爆炸了。
类似的问题微盟不是第一个,也不是最后一个。其它有类似隐患的公司,都有可能成为下一个微盟。

1.2 前端三方依赖隐患
作为前端开发,肯定碰到过依赖升级导致的各种问题。
代码一行没改,重装下依赖,构建不起来了
代码一行没改,发到线上样式出问题了
......
每一次问题都是一次「未遂先兆」,大部分同学可能骂一下三方库维护者,然后回退下版本,修复了这个问题,就好了,并没有重视这些小问题背后的隐患。这不,炸弹炸了。2018 年圣诞节,使用 ant design 组件库的项目发现按钮上多了一个「雪花」,并带有「Ho Ho Ho!」的提示。
事情的根源是 ant design 开发者在 9 月 10 号提交了一次代码,增加了一个时间判断,圣诞节当天触发彩蛋。
此次事件在社区影响很大。


依赖引起的大大小小的故障,你有没有重视?如果没有,那下一个炸弹可能就在你那里爆炸,可能是这样的:
有一天你们的网站突然被重定向到了「黄赌毒」网站。原因是某个库加了这个逻辑,判断某个特定时间做跳转。
有一天你们的网站上的金额展示不正确,用户各种投诉。原因是某个库注入了恶意代码。
某个库监听了账号密码输入框,并发送到自己的服务器。
某个库引入了 Evil.js
某个库引入了挖矿脚本(比如 ua-parser-js)
从以上两个案例中,我们可以看到「有可能出问题的地方,一定会出问题」,「大问题出现前会有很多次征兆」。
当然问题肯定是不能完全避免的,我们需要做的就是重视小问题和行业经验,减少事故隐患,降低出问题的概率,同时为所有可能出现的问题做好应急方案。
回到我们的主题,前端质量体系主要的目的就是:
变更前,吸取自身和行业经验,通过流程、工具、机制等避免常见问题
变更时,在不可避免的引起线上故障时,能及时发现,并有效控制影响范围和时间
变更后,建立起线上问题追踪机制,吸取自身经验教训,完善流程工具,避免出现同类问题
接下来,我会分变更前、变更时、变更后三个部分,来罗列各种能帮助我们提升前端质量的措施。当然有很多方案我也没有实际使用过,所以今天更多的是「纸上谈兵」。
2. 变更前
2.1 使用 TypeScript
我认为现代项目都应该使用 TS,TS 的静态类型能力,可以极大提升编码质量,提高编码效率,提升代码的可维护性,减少代码隐患。
对比一下使用 JS 和 TS 写的代码
// JS 版本
function editUser(userInfo){
return request('/api/edit', {
data: userInfo
})
}
// TS 版本
interface UserInfo {
id: string;
name?: string;
age?: number;
gender?: 'male' | 'female'
}
function editUser(userInfo: UserInfo){
return request('/api/edit', {
data: userInfo
})
}
以上两份代码,你更乐意接手哪份代码呢?
再举个例子
function onChange(params1, params2){
// 一些复杂的代码
}
上面的函数,如果不阅读函数体代码,谁能知道入参格式呢 ~
TS 的更多好处这里就不赘述了,建议能用尽用。
2.2 静态扫描
代码静态扫描检查,可以帮助我们避免低级 Bug,统一代码习惯,提升代码质量。
我们最常见的静态代码扫描工具是 ESLint,使用注意事项有:
在公司内部统一 ESLint 规则(单个项目也要支持自定义规则)
在代码提交之前,增加 ESLint 检查卡点,保证提交的代码一定是符合规范的
在非本地环境也要加上 ESLint 检查卡点,比如代码合并之前 CI 检查,防止本地绕过提交卡点
有些公司也会定期去扫描代码仓库,检查有风险代码,比如容易造成 XSS 攻击的 dangerouslySetInnerHTML 等等。
2.3 三方依赖
前端的依赖该不该锁死版本,是一个难题,锁与不锁都会带来严重的问题
锁依赖: 依赖包修复的任何 bug,开发的任何新功能我们都不能享受。并且时间久了完全升不动了。
不锁依赖: 依赖包新版本引入的 bug、以及恶意投毒,会导致我们的代码没改,仅仅重装下依赖就跑不起来了。

之前蚂蚁针对锁与不锁,争论了好几年,最后在两者之间找到了一个相对平衡的解法:项目中依赖不锁,由中间商保证依赖版本。
DevOps 平台提供了「迭代锁」能力,也就是在一个迭代周期内,依赖版本是固定的。不会出现在开发阶段没问题,但是在预发重新构建后出问题了。
umi 框架锁依赖,定期升级,并对此负责。能解决 node(webpack、babel) 部分依赖,不能解决 bowser (ant design)部分依赖。
阿里 npm 包管理工具 tnpm,支持在公司层面锁定某个包的依赖,一旦发现某个包有问题,立即锁定依赖版本。
整体看,蚂蚁的这些依赖管控措施,效果还是挺不错的,之前的几次大的 npm 包故障,对蚂蚁都没啥大的影响。
但对于大部分公司,基础设施没有这么完备,就要根据自己的业务发展阶段和规模自行决定锁与不锁了。我个人建议有一定规模的项目都应该把依赖锁起来,毕竟安全是底线。
感觉未来应该会有新的包管理方案出来,彻底解决类似问题。
2.4 标准化
将通用的解决方案标准化,比如图片怎么引入、国际化怎么写、CSS 解决方案、请求解决方案、API 格式 等等。
最好能有一份公司内公认的最佳实践,并且大部分项目能遵守这些约定。
我认为比较好的落地方案是:搞一个使用最佳实践的 demo 项目,所有新项目初始化的时候,都使用这一套代码,自然就会延续最佳实践的写法。
2.5 单元测试
单元测试通常是指对代码中最小可测试单元进行检测,比如一个函数、一个组件、一个 React Hook 等等。
比如测试一个函数:
const add = (a, b) => {
return a + b;
}
// 单元测试
test("add numbers", ()=>{
const result = add(1, 2);
expect(result).toBe(2);
})
比如测试一个组件:
// 测试 Button 组件 disabled 属性正常工作
test('renders with disabled', () => {
const { getByRole } = render(<Button disabled>Disabled</Button>)
const button = getByRole('button')
expect(button).toBeDisabled()
})
比如测试一个 React Hook:
it('should update document title', () => {
const hook = renderHook((props) => useTitle(props), { initialProps: 'Current Page Title' });
expect(document.title).toBe('Current Page Title');
act(() => {
hook.rerender('Other Page Title');
});
expect(document.title).toBe('Other Page Title');
});
单元测试的优点是:
能精细化的保障每个小部件的质量
能帮助开发者写出易于测试的代码
单元测试的缺点是:
编写用例工作量大
能保证单个部件的正确性,不能保证整个项目的正确性
2.6 E2E 测试
e2e 测试,英文全称 End To End Test,也可以翻译成端到端测试。它模拟真实用户,从某个入口开始,逐步执行操作,直到完成某项工作。
比如测试登录功能:
打开登录页面
输入账号、密码
点击确认按钮
判断是否登录
it('should register work', async () => {
const BASE_URL = 'http://localhost:8000/login';
await page.goto(`${BASE_URL}`);
await page.waitForSelector('button[class="ant-btn ant-btn-primary ant-btn-lg"]');
await page.fill('input[id="username"]', 'admin'); // 输入用户名
await page.fill('input[id="password"]', 'ant.design'); // 输入密码
await page.click('button[class="ant-btn ant-btn-primary ant-btn-lg"]'); // 点击按钮
await page.waitForNavigation(); // 页面跳转
const url = await page.url();
expect('go home after login', url).toBe(homeUrl);
});
如果我们把项目中主要的功能都编写好测试用例,在每次代码变更后,自动全量执行一遍,就能知道本次变更是否影响到了主流程。这个又叫自动化测试。
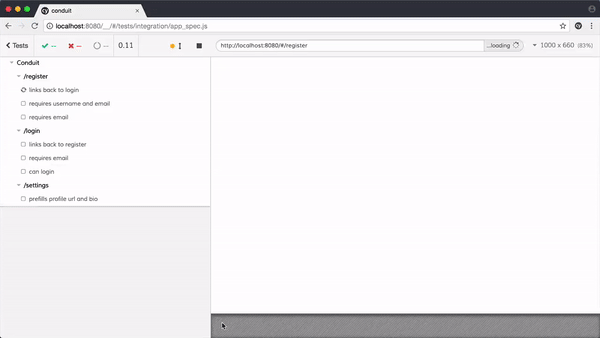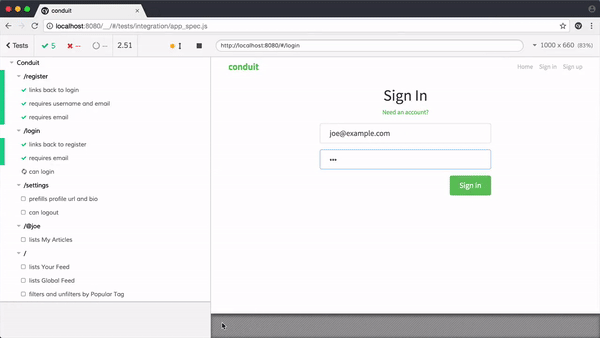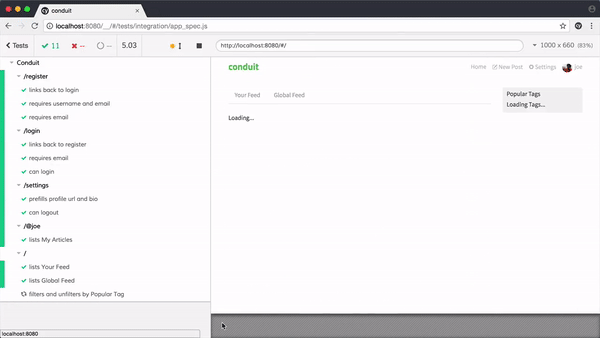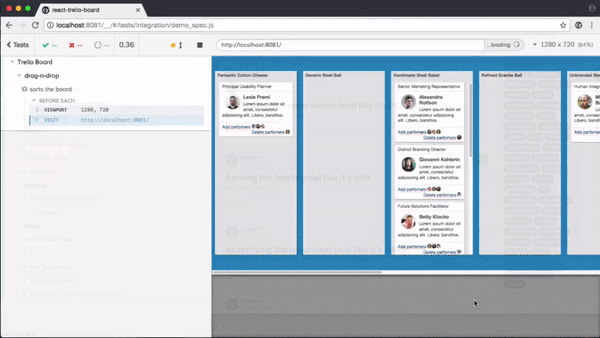
如果我们把上述用例在各种浏览器跑一遍,就知道是否存在阻塞主流程的兼容性问题,这个又叫前端兼容性测试。
如果我们能在关键步骤上,增加截图对比断言,就可以知道页面样式是否错乱。类似下面这样
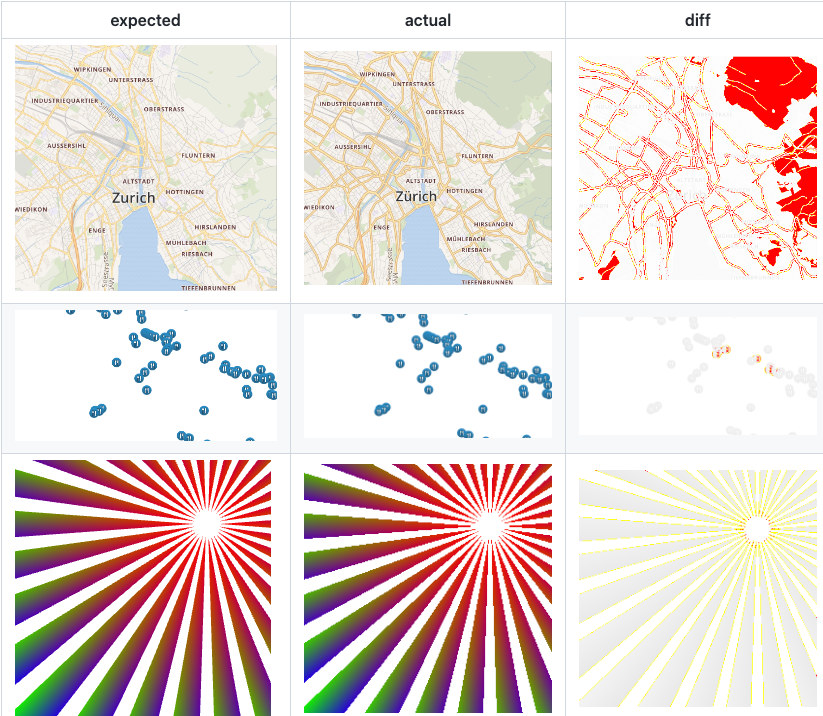
最后如果你觉得编写测试用例很复杂,那你可以使用录制工具,将你在浏览器的真实操作录制成测试用例。
用例的录制对非开发同学非常友好,比如测试同学就可以录制各种用例,做自动化测试。
如果能把 e2e 测试融合到公司的软件研发流程中,对项目质量的提升一定是大有裨益的。但难点也在如何很好的融合到公司的整个研发流程中。
e2e 测试看起来很美好,但也有很多缺点:
通过 XPath 来定位元素,如果页面结构有调整,则用例很可能会失败
由于在浏览器端执行,执行速度会比较慢
依赖后端接口,如果后端接口不稳定,用例也会失败
2.7 纯前端全覆盖测试
e2e 测试一般是核心功能测试,前后端集成测试,依赖后端接口,很多边界情况没办法测试到。
比如一个上拉加载的列表页,在前端层面看,会有以下几种情况:
无数据
有一页数据,正常加载出来
第一页数据加载失败
有多页数据,上拉加载可以正常工作
有多页数据,上拉加载失败
以上五种情况,需要 5 种不同的接口数据,怎么做?这我提一个思路:
在前端开发过程中,完整 Mock 各种接口返回结果
当前迭代通过 Mock 数据跑出的页面,和上一个迭代同页面同 Mock 数据跑出的页面,做对比,即可知道前端层面是否有变化
理论上,同一个页面,同一份 Mock 数据,在不同迭代之间渲染出来的前端页面是一样的。如果我们能把每一个页面的每一种 Mock 数据渲染的页面做对比,就能知道当前迭代前端层面实际引起的所有变更。
该方案的难点在如何工程化,即如何管理 Mock 数据,怎么跟着迭代走,总得来说就是怎么很好的融合到公司的研发流程中。
2.8 变更卡点
对于本地提交的代码,默认都是不可信的,因为 ESLint 检查是可以绕过的,TS 类型可能有报错,测试用例也可能没有执行通过。
所以在非本地环境,我们一定要加上检查卡点,检查内容包括不限于 ESLint 等静态代码检查、测试用例是否通过、测试覆盖率、构建产物的大小等等。
卡点阶段可以是在代码合并之前,部署之前,迭代阶段推进之前,发布之前等,需要根据不同的卡点内容选择合适的阶段。
2.9 Code Review
CR 是代码准入的一个人工卡点环节,能比较有效的提升代码质量。但如何建设好的 CR 文化是一个比较难的命题,很多人都是「点点工程师(不看光点)」?有些公司会在待 CR 的代码中注入一些恶意代码,看评审人有没有认真审核代码。
3. 变更中
3.1 灰度
灰度发布是指我们可以将新版本逐步放量,让部分用户先来使用新版本。
假如我们的用户量有一百万,如果没有灰度,我们每次发布的时候都是「牙一咬,眼睛一闭,心一横」,点击发布按钮,全量生效。如果出问题,影响面就非常广。
具备灰度能力的话,我们就可以根据特定条件筛选出来一部分用户,比如 1% 的用户,当这 1% 的用户使用没有问题的话,我们再逐步扩大用户范围,直到全量发布完成。
灰度发布可以极大降低发布风险,在前端安全中是非常重要的一环。
部分公司也会引入智能灰度,比如灰度过程中程序发现监控故障增加,自动回滚。或者在没有故障的情况下,自动推进灰度进程。
3.2 应急
对于任何变更,我们都需要提前设计好应急措施。
新的变更最好可以添加开关控制。比如本次变更新增了一块功能,我们可以在数据库新增一个 isShow 的标识,如果这个功能出问题,我们可以立即修改数据库,下线该功能。
另外就是迭代之间的「回滚」能力一定要具备,对于开关控制满足不了的,要能立即回滚到上一个迭代。
3.3 监控
如果系统没有监控,那我们就是两眼抹黑,对系统当前的运行状态完全不了解。出问题全靠用户反馈,迟早要出大问题。
标准的前端监控应该包括以下数据:
JS 异常
Promise 异常
资源异常
API 请求
页面整体访问情况,包括 PV、UV
页面性能情况
其它核心业务自定义数据
一个优秀的监控系统,需要考虑以下几个方面:
数据上报要够方便,最好接入一个 SDK 之后,一行代码都不用写,必要的数据自动上报。这个是完全可以实现的,比如 JS 异常、资源异常、PV、性能数据、API 请求等等都是可以在最外层拦截到的。
上报的数据要够全,比如当前 URL 、浏览器信息、用户位置等等。
支持自定义数据上报。
数据大盘要够直观,可以直观的看到各种趋势变化。
支持多版本上报,比如灰度的 1% 用户的数据变化,要和其它 99% 用户的区分开。
支持采样率
JS 异常可以快速定位,要支持 sourcemap 绑定,同样这里要考虑 sourcemap 什么时候上传,如何和当前的研发流程融合。
支持单个用户纬度上报数据时间线查看,在碰到问题时可以更方便的分析上下文。
自身的稳定性要好,不能影响宿主系统的性能和稳定性。
其它~~
有些前端异常,仅凭借前端自身是监控不到的。比如用户完全打不开前端页面,html 都加载失败了。这种情况下我们需要和容器端配合做监控了。
拥有了监控数据后,我们就能实时看到项目的健康度了,比如接口成功率、JS 异常数量、实时用户数等等。
如果我们在灰度 1% 的时候,突然发现新增了以前没有出现过的 JS 异常,那大概率是这次发布引起的。或者灰度用户核心接口的调用量下跌了 30%,那也要仔细排查了。
3.4 报警
拥有监控数据后,我们就可以根据数据的变化,来配置报警,以便及时发现线上故障。
我认为通用的前端应该具备以下报警能力:
新增异常报警,比如出现了过去 30 天没有过的 JS 异常,或者资源异常等
异常数量上升严重,比如过去 5 分钟 JS 异常数量环比上升了 50%
PV/UV 同比/环比下跌严重,比如过去 5 分钟 PV 环比下跌了 30%
核心接口请求量同比/环比下跌严重,比如下单接口请求量 5 分钟环比下跌了 30%
核心接口成功率同比/环比下跌严重,比如下单接口成功率下跌到了 70%
其它核心业务数据变化报警
关于报警配置,我自己有两点看法:
JS 异常报警,往往能发现绝大部分前端问题
接口监控,能反映出非常多问题。比如页面白屏,就可以通过监听接口请求量下跌发现。比如表单填写出现问题,就可以通过表单提交接口的请求量下跌发现。
报警配置一定要做好降噪,如果经常都是无效报警,那就是狼来了,等出现真正线上问题的时候就没人关心了。所以报警的配置需要根据业务的情况不断调整到合适的数值。
手中有粮,心中不慌~
4. 变更后
4.1 巡检
巡检是指通过脚本,定时去检查线上应用是否正常工作。比如:
网页是否能正常打开
网页上的核心元素是否正常展示
网页上的所有链接是否都能正常访问,没有死链
跑提前写好的用例,或者录制好的用例,看用例是否能正常工作。这个就类似 e2e 用例~
4.2 质量运营
质量建设不是一次性的,需要持续不断的提升开发者的质量意识,检查质量建设进度,复盘线上故障。
故障演练 故障演练是指通过技术手段触发线上故障,观察开发人员的发现能力和应急能力,以持续提升公司故障应急能力。我认为故障演练是有效提升应急能力的手段之一。
度量和排名要能对质量进行有效的度量,比如以故障次数、严重程度等进行评分。对于单个项目在一个绩效周期内,需要看到质量评分的提升。对多个项目要整体排名,以提升整体水位。
故障分析对线上故障进行复盘,持续完善质量方案。
文化建设 持续进行文化宣传,让质量安全深入人心。之前在蚂蚁,人人都能熟背变更三板斧「可监控、可灰度、可应急」,因为三天两头会宣传,会考试。
5. 总结
前端质量解决方案有很多,至于哪些适合自己,需要根据自己的项目阶段和规模来筛选。
在接入各种质量手段的时候,需要考虑手段采用的越多,越影响我们的开发效率。作为质量负责人,一定不能顾头不顾尾,逼着大家接入 ABCDEFG~。最好的解决方案是在质量和效率之间找到一个平衡点,如果能做到润物细无声就最好了。
如何把前端质量体系很好的融入到 devops 的整个环节中,做到自然而然,是一件非常有挑战性的事情。
生产稳定性一定是产品的生命线,只有重视每一个小问题,才能在最大程度上减少线上故障,希望大家的系统都不出故障~~
关于作者
砖家,brickspert
前蚂蚁集团前端技术专家
开源库 ahooks 作者,10k+ star ⭐️
开源库 antd mobile 前负责人,10k+ star ⭐️
你可以在以下渠道找到我:
公众号:前端技术砖家
B 站:前端技术砖家
知乎:砖家
掘金:前端技术砖家
Github:brickspert