
常识知识确能被捕获,西湖大学博士探究BERT如何做常识问答
BERT 是通过常识知识来解决常识任务的吗?

预训练上下文化语言模型(例如 BERT)的成功激发了研究人员探索此类模型中的语言知识,以解释下游任务的巨大改进。
尽管先前的研究工作展示了 BERT 中的句法、语义和词义知识,但在研究 BERT 如何解决常识问答(CommonsenseQA)任务方面做的工作还很少。
近日,来自西湖大学、复旦大学和微软亚洲研究院的研究者提出了两种基于注意力的方法来分析 BERT 内部的常识知识,以及这些知识对模型预测的贡献。
论文一作 Leyang Cui 为西湖大学文本智能实验室(Text Intelligence Lab)的在读博士生。

论文地址:
https://arxiv.org/pdf/2008.03945.pdf
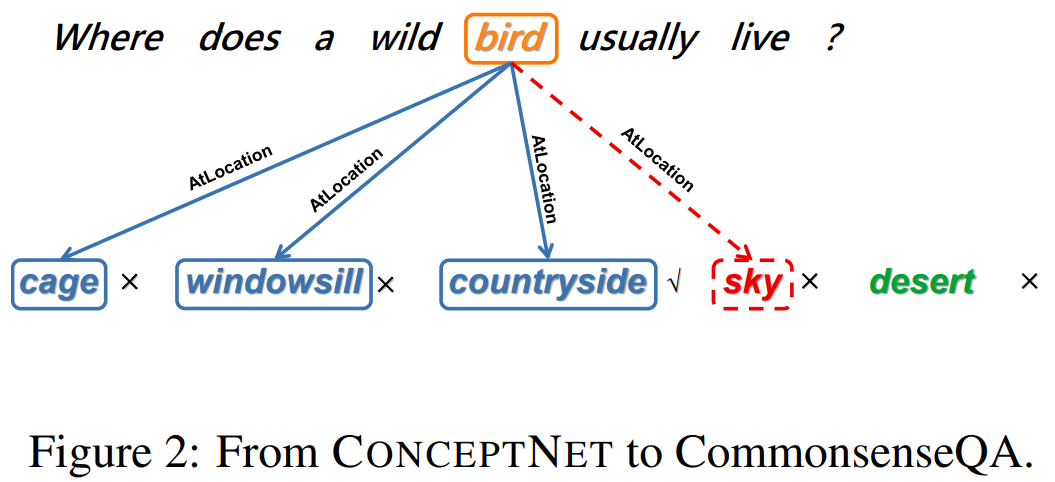
研究者采用 Talmor 等人在 2019 年提出的方法,在 CommonsenseQA 上使用 BERT(Devlin 等人,2019 年)。
结构如下图 3 所示:
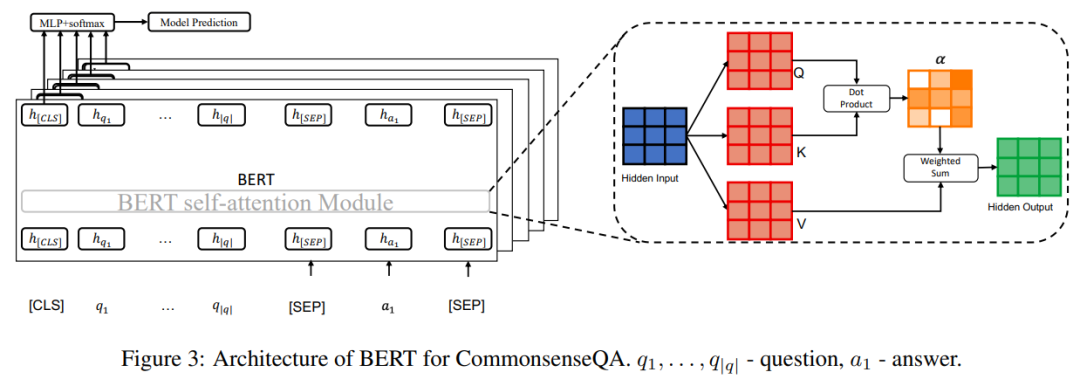
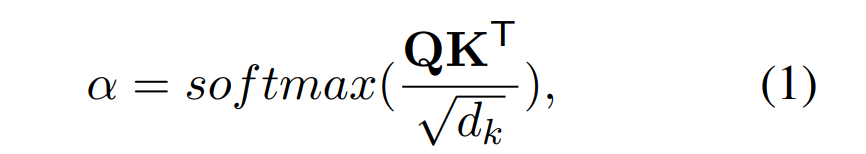
研究者使用一种名为集成梯度(Integrated Gradient,Sundararajan 等人 2017 年提出)的归因方法来解释 BERT 中的常识链接。
直观地讲,集成梯度方法模拟剪枝特定注意力头的过程(从初始注意力权重α到零向量α'),并计算反向传播中的集成梯度值。
值得注意的是,[CLS] token 的表示不是问题概念,而是直接连接至输出层以进行候选评分。
因此,在预训练和微调阶段,对于输出层以及答案概念 token 到问题概念 token 的链接权重,都没有直接的监督信号。
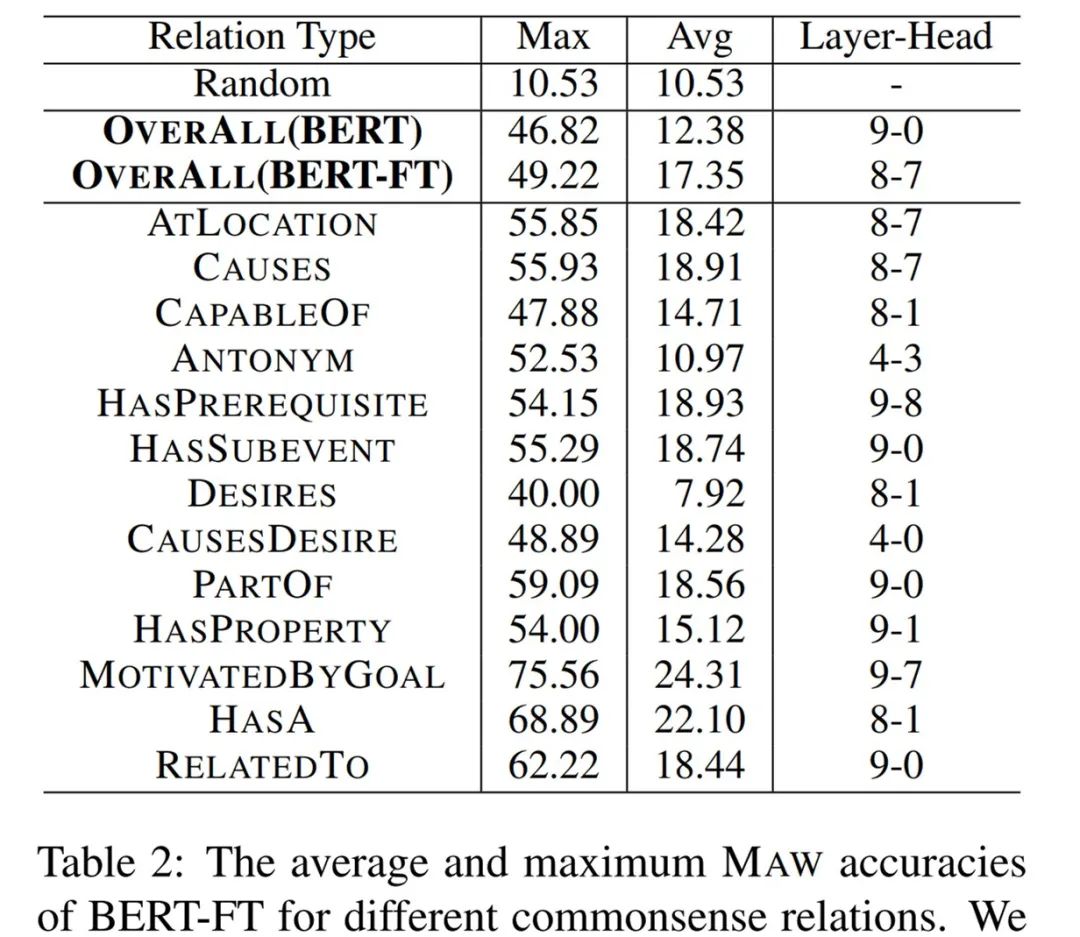
首先观察未经微调的原始 BERT,每一层的最大 MAW 准确率明显优于随机基准。这表明 BERT 确实捕获了常识知识。
此外,BERT 的平均 MAW 也明显优于随机基准(p 值 < 0.01),这表明相关的问题概念无需微调即可在 BERT 编码中发挥非常重要的作用。
研究者进一步进行了一组实验,来描述常识链接与模型预测之间的相关性。
目的是为了研究不同候选答案概念到问题概念的链接权重是否会对这些候选答案之间的模型决策造成影响。
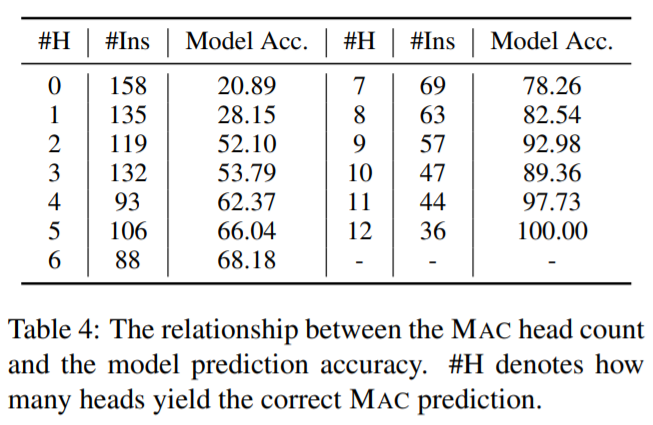
具体而言,研究者比较了 5 个候选答案对于同一问题的链接权重,并找出了与相关问题概念最相关的候选答案。
这个候选答案被称为最相关候选对象(most associated candidate, MAC)。
MAC 和每个问题的模型预测之间也存在着相关性。直观地讲,如果 MAC 与模型预测呈现相关性,则证明模型在预测过程中运用到了常识知识。
研究者进行实验来评估 MAC 对模型决策的贡献,以及 MAC 依赖与输出准确率之间的相关性。
实验中使用注意力权重和归因得分来测量链接,这是因为在考虑模型预测时梯度会发挥作用。
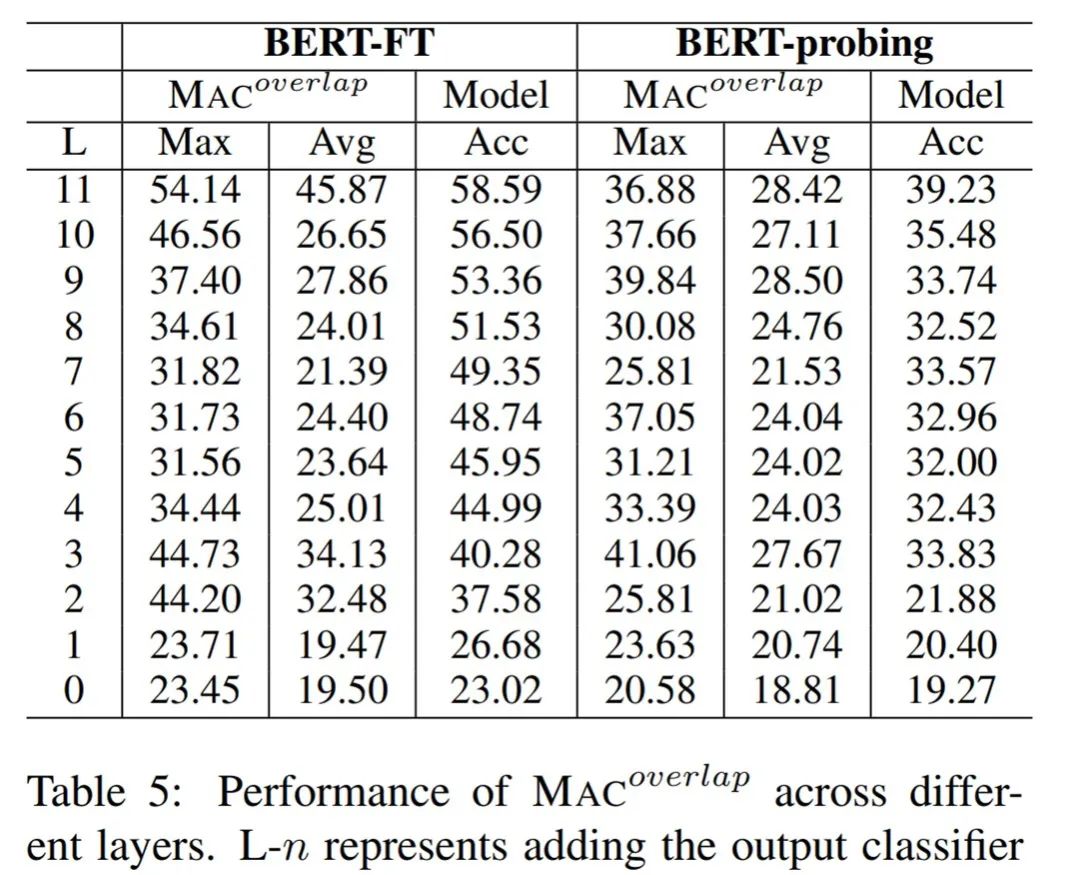
研究者测量了 BERT-FT 和 BERT-Probing(这是一个仅针对输出层进行微调的 BERT 变体)的 MAC 性能,其中 BERT-Probing 是一个线性探测(linear probing)模型。
直观地讲,如果线性分类器可以预测常识任务,则未经微调的原始模型可能会编码丰富的常识知识。
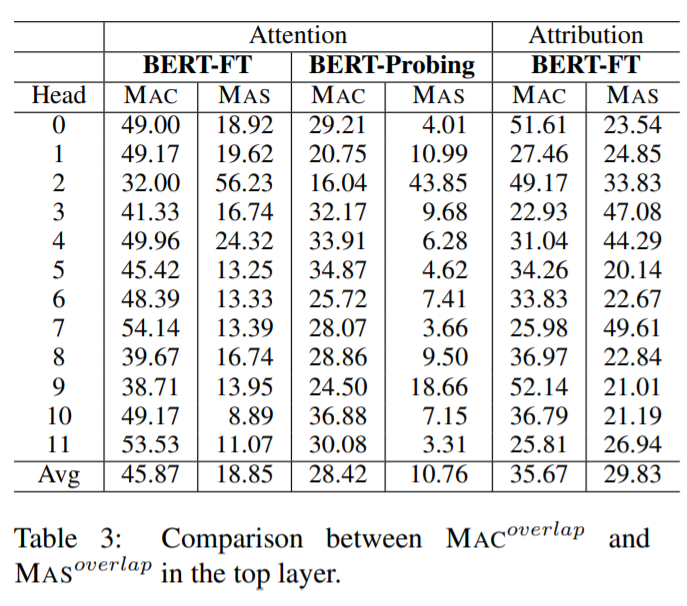
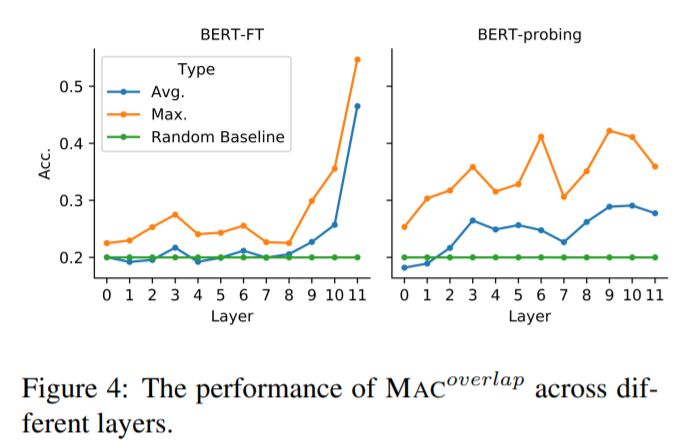
最后,研究者进一步探究了常识知识使用上的两个具体问题。其一,在决策过程中,BERT 最依赖哪个层?其二,BERT 使用的常识知识来自预训练或微调吗?
为此,研究者通过连接每个 Transformer 层上的输出层,对 12 个模型变体进行了比较。
论文地址:
https://arxiv.org/pdf/2008.03945.pdf
往期学员就业薪资??(部分截图)

(为保护学员隐私利益,特隐晦部分敏感信息)
此课程在教学模式、实战项目、讲师团队、就业服务,在国内都是非常领先的,还专门为学员提供一年的GPU云平台使用。
五大学习阶段,分别从NLP基础、pytorch实战、词向量与预训练模型、机器翻译、结构化预测、到问答系统和聊天机器人。
同时持续新增NLP前沿技术,BERT、RoBERTa、ALBERT、Google T5等全部一网打尽。并且提供“语言模型、文本分类、结构化预测”这三次大作业的辅导,更好的提升学员代码和项目能力。

本期课程拥有超豪华讲师团队,学员将在3位顶级讲师的手把手指导下完成五大阶段的学习,通过3个月学习挑战40万年薪。
授课老师、助教老师,多对一服务。从课上到课下,从专业辅导到日常督学、360度无死角为学员安心学习铺平道路。陪伴式解答学员疑惑,为学员保驾护航。
学员在完成所有的阶段学习后,将会有一对一的就业服务,包括项目总结和就业辅导、面试辅导与内推两大部分。
为了确保学员100%都能拿到满意的offer,七月在线还专门成立就业部,会专门为就业班学员提供就业服务,保证每一位学员都能拿到满意的offer。
扫码查看课程详情,同时大家也可以去看看之前学员的面试经验分享。
戳↓↓“阅读原文”查看课程详情!