CCF2020问答匹配比赛:如何只用“bert”夺冠

- 成员1:许明 中国海洋大学
- 成员2:刘猛 南京大学
非常感谢第一名“看我干啥”分享的方案 原文:https://xv44586.github.io/2021/01/20/ccf-qa-2/#sai-ti 作者:看我干啥 代码链接:https://github.com/xv44586/ccf_2020_qa_match
[前言] [赛题] [QA pair] [QA Point] [Pattern-Exploiting Training (PET)] [Concat] [focal loss] [对抗训练] [post training] [Post Training] [MLM] [nsp] [model-adaptive] [更新次数] [最终结果] [融入知识] [对比学习] [非监督对比学习] [监督对比学习] [实验结果] [数据增强] [EDA] [伪标签] [实验结果] [自蒸馏] [shuffle 解码] [模型融合] [实验总结] [比赛结果] [代码] [最后] [关于头图]

比赛链接:
https://www.datafountain.cn/competitions/474

数据示例

评测标准
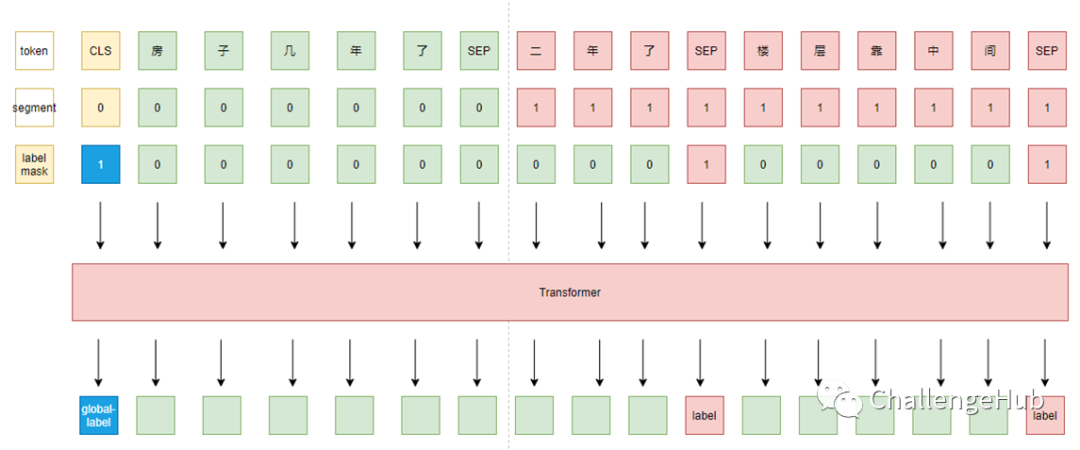
由于bert 中不同的transformer 层提取到的语义粒度不同,而不同粒度的信息对分类来说起到的作用也可能不同,所以可以将所有粒度的语义信息拼接后作为特征进行分类。

对抗训练主要尝试了FGM 方法对Embedding进行扰动,线下对比提升大约一个点上下。线下测试结果:
without adt0.831with adt0.838without adtwith adt0.8310.838


以上的方式中全程没有人为参与,所以新词的质量是无法保证的,即存在词的边界不准确。而此时的全词mask 退化为n-gram mask,依然是一种有效的提升方案。
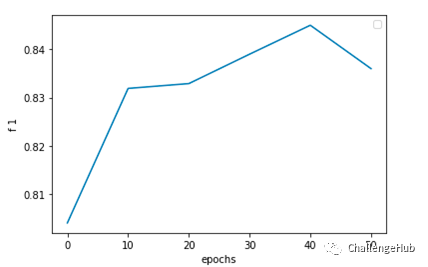
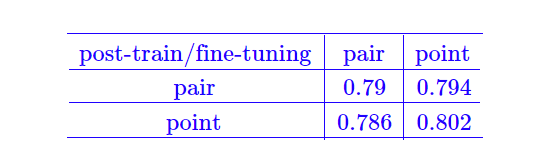
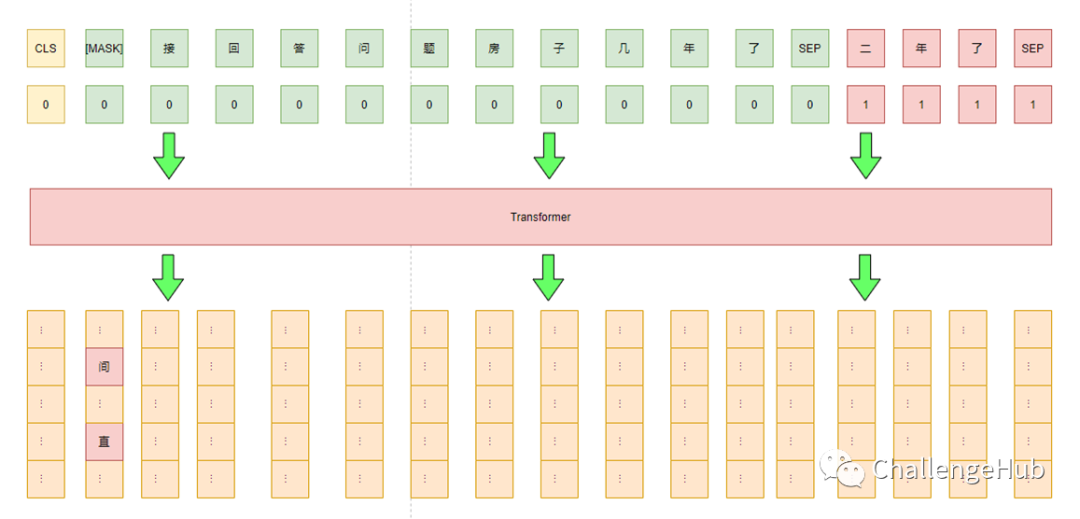
此时我们认为已经将bert的能力最大化了,于是这里也尝试了在bert 后面接一些复杂的分类层(cnn/rnn/dgcnn/..),发现都无法进一步提高,所以也证实了之前的判断。
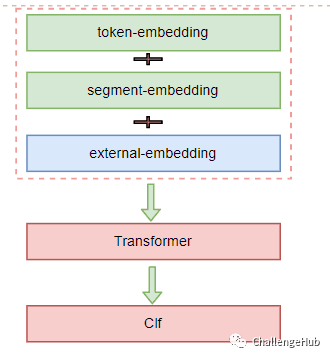
最底层注入 在Embedding 层融入外部的embedding。优点:更多的交互
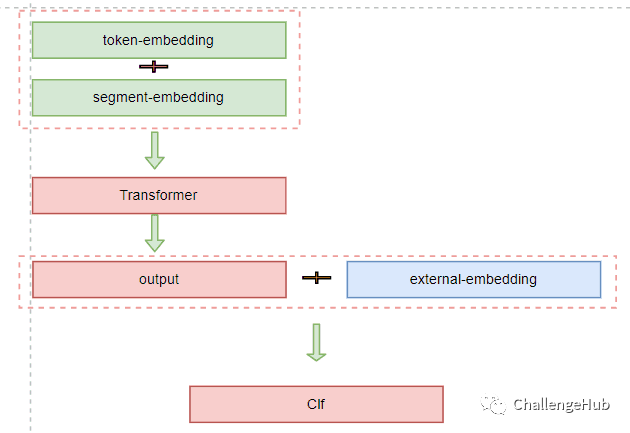
最顶层注入 在transformer output 层融入外部Embedding。优点:更灵活,不局限外部知识的形式(可以是Embedding,也可以说是其他特征,如手工特征)。

对应的loss:
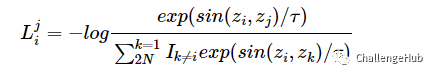
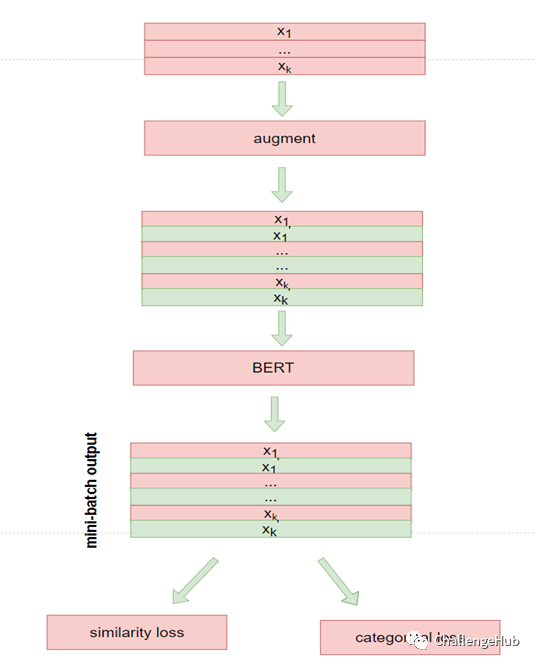
对应的模型:
loss
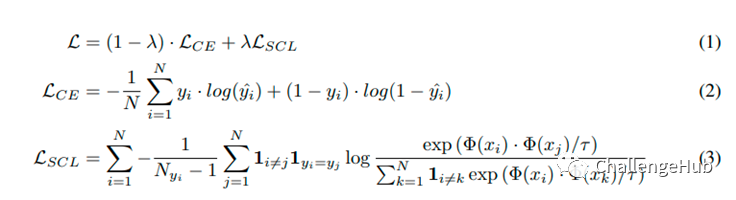
model
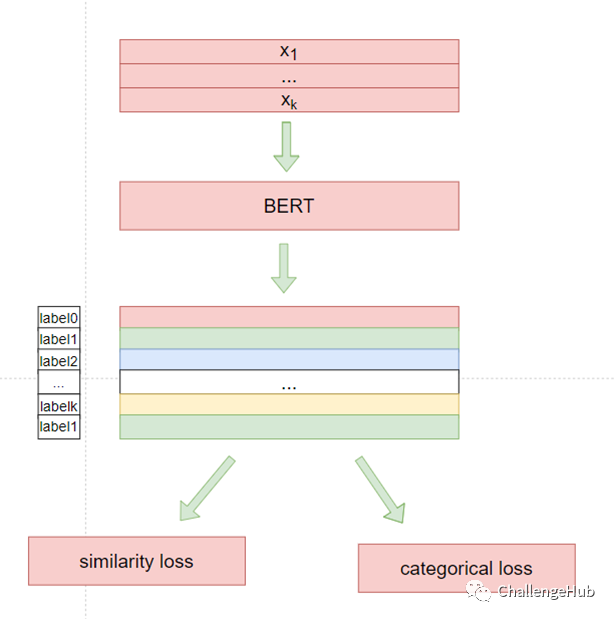
线下结果:

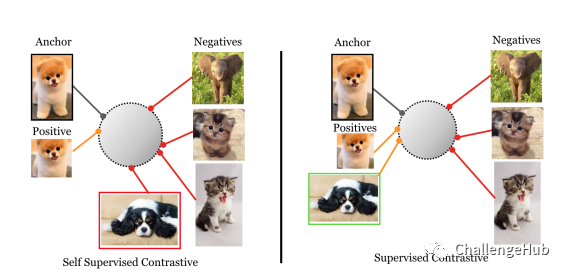
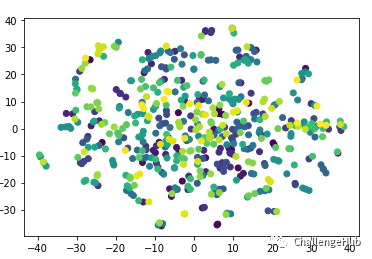
非监督对比学习结果可视化
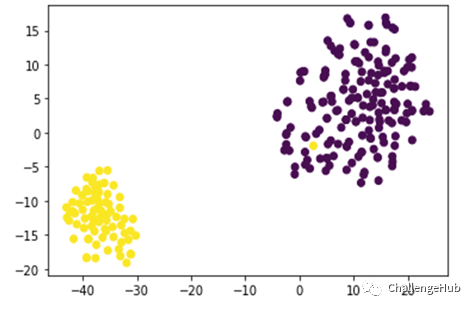
监督对比学习结果可视化
EDA
伪标签
实验结果
线上结果

soft labels:
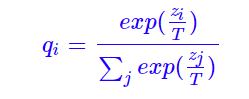
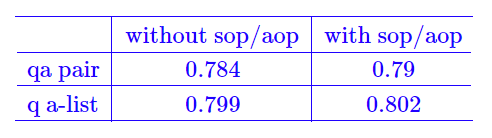
线下测试结果:

能work的方案
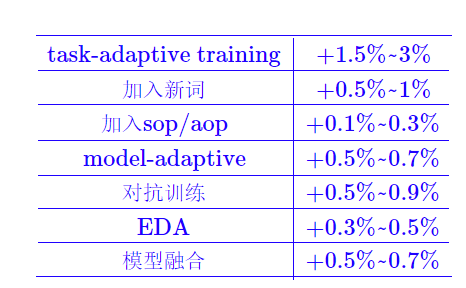
不能work的方案

线下有效但未提交

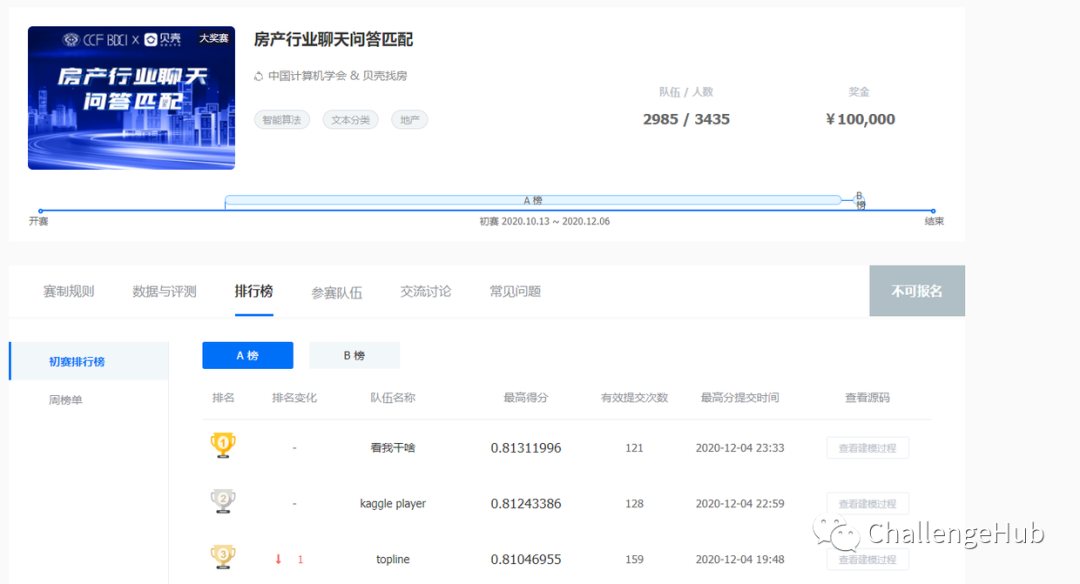
A榜得分:
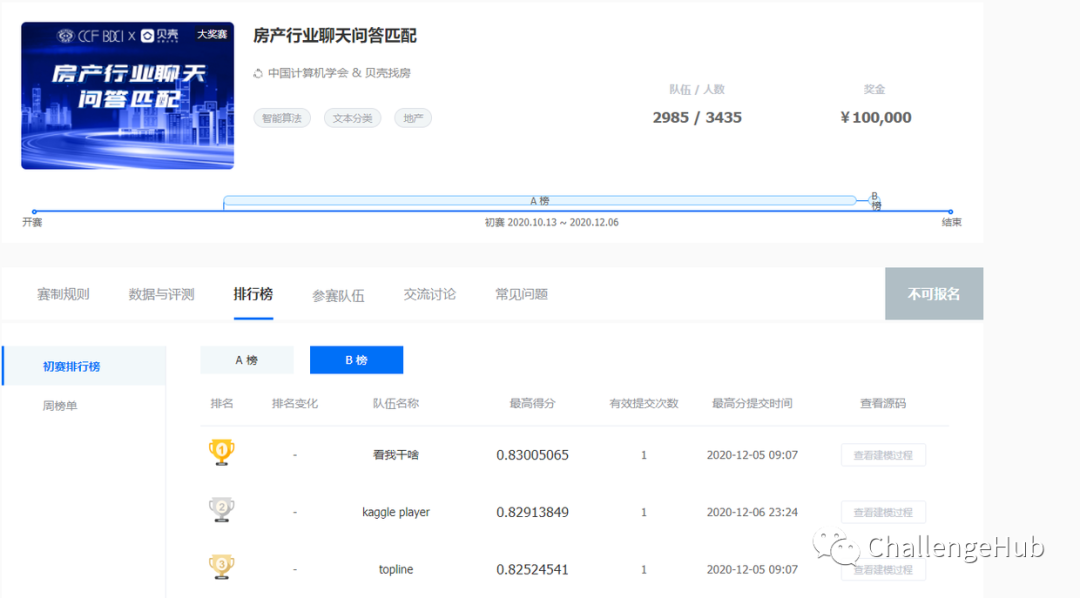
B榜得分:
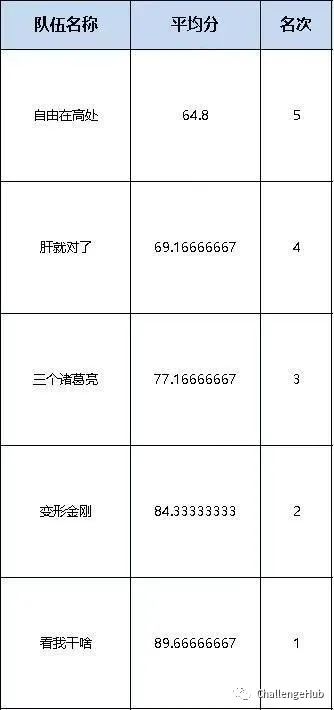
答辩得分:
比赛相关思路的代码开源在github上:ccf_2020_qa_match欢迎大家尝试使用,有问题或者想法可以提issue,一起讨论。
https://github.com/xv44586/ccf_2020_qa_match