
Keras之父出品:Twitter超千赞TF 2.0 + Keras速成课程

【新智元导读】本文是由Keras之父编写的TensorFlow 2.0 + Keras教程。本教程针对深度学习研究人员,非常详细的给出了代码以及运行结果。评论区表示本教程非常详实,实操性高。>>> 人工智能改变中国,我们还要跨越这三座大山 | 献礼 70 周年
可能没人比François Chollet更了解Keras吧?作为Keras的开发者François对Keras可以说是了如指掌。他可以接触到Keras的更新全过程、获得最一手的资源。同时他本人也非常乐于分享、教导别人去更好的学习TensorFlow和Keras。
在TensorFlow 1.x时代,TF + Keras存在许多问题:
使用TensorFlow意味着要处理静态计算图,对于习惯于命令式编码的程序员而言,这将感到尴尬且困难。
虽然TensorFlow API非常强大和灵活,但它缺乏完善性,常常令人困惑或难以使用。
尽管Keras的生产率很高且易于使用,但对于研究用例通常缺乏灵活性。
随着TensorFlow迈入2.0时代,相比上一代进行了非常大的改动。在吸取了4年来大量的用户反馈以及技术进步,针对TensorFlow和Keras进行了广泛重新设计,使得之前的历史遗留问题得到了很大程度的改善。
TensorFlow 2.0建立在以下关键思想之上:
让用户像在Numpy中一样急切地运行他们的计算。这使TensorFlow 2.0编程变得直观而Pythonic。
保留已编译图形的显着优势(用于性能,分布和部署)。这使TensorFlow快速,可扩展且可投入生产。
利用Keras作为其高级深度学习API,使TensorFlow易于上手且高效。
将Keras扩展到从非常高级(更易于使用,不太灵活)到非常低级(需要更多专业知识,但提供了极大灵活性)的工作流范围。
本文是TensorFlow 2.0的简介、速成课程和快速API参考。TensorFlow和Keras都是在4年前发布的,在深度学习领域已经算老资历了。
相比其他教程,François的教程或许更能体会到Keras的精髓、能够窥探到特性背后更深层的成因、更好的掌握TensorFlow和Keras。
教程内容主要由2个部分构成。第一部分主要讲TensorFlow一些基础,比如张量、变量、数学、梯度计算等;第二部分详细介绍了Keras API。
教程放在Google Colab上,可以一边看介绍一边运行代码。
这部分主要介绍了张量、随机常量张量、变量、数学计算、使用GradientTape计算梯度、线性回归的实例,以及使用tf.function来加速运行。能用代码解释就绝不用文字,比如:
Tensor
常量张量:

通过调用.numpy()来获取其作为Numpy数组的值:

与Numpy数组非常相似,它具有dtype和shape属性:

创建常量张量的常见方法是通过tf.ones和tf.zeros(就像np.ones和np.zeros一样):

随机常量张量
通常:

这是一个整数张量,其值来自随机均匀分布:

变量
变量是用于存储可变状态(例如神经网络的权重)的特殊张量。可以使用一些初始值创建变量。

可以使用.assign(value)或.assign_add(increment)或.assign_sub(decrement)方法来更新变量的值:

数学计算
可以像使用Numpy一样完全使用TensorFlow。主要区别在于你的TensorFlow代码是否在GPU和TPU上运行。

用tf.function加速
未加速前:

加速后:

Keras是用于深度学习的Python API。它适合所有人:
如果你是工程师,Keras将为你提供可重用的模块,例如层,指标,培训循环,以支持常见的用例。它提供了可访问且高效的高级用户体验。
如果你是研究人员,则可能不希望不使用这些内置模块,例如图层和训练循环,而是创建自己的模块。当然,Keras允许你执行此操作。在这种情况下,Keras为你提供了所编写块的模板,为你提供了结构,并为诸如Layers和Metrics之类的API提供了标准。这种结构使你的代码易于与他人共享,并易于集成到生产工作流程中。
库开发人员也是如此:TensorFlow是一个大型生态系统。它有许多不同的库。为了使不同的库能够彼此对话并共享组件,它们需要遵循API标准。这就是Keras提供的。
至关重要的是,Keras流畅地将高级UX和低级灵活性结合在一起:一方面,你不再拥有易于使用但不灵活的高级API;另一方面,你却不再具有灵活但仅具有灵活性的低级API。与专家接触。相反,你具有从高级到低级的一系列工作流。所有工作流程都是兼容的,因为它们是基于相同的概念和对象构建的。
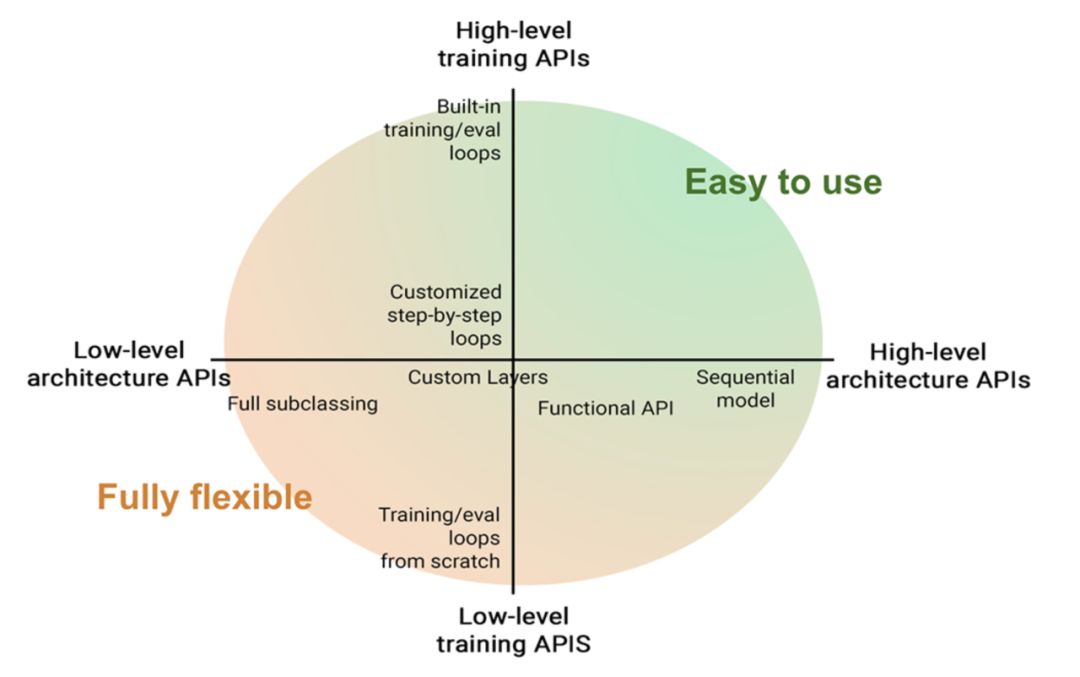
这部分主要介绍了:基础layer类、可训练及不可训练权重、递归组成图层、内置layer、call方法中的training参数、更具功能性的模型定义方式、损失类、矩阵类、优化器类以及一个端到端的training循环、add_loss方法、端到端的详细示例:变体自动编码器(VAE)、内置training循环实操、Callback。
这部分同样使用大量的代码和运行结果,让大家有一个更直观的理解。比如:
call方法中的training参数
一些层,尤其是BatchNormalization层和Dropout层,在训练和推理期间具有不同的行为。对于此类层,标准做法是在call方法中公开训练(布尔)参数。
通过在调用中公开此参数,可以启用内置的训练和评估循环(例如,拟合)以在训练和推理中正确使用该图层。

优化器类以及一个端到端的training循环
通常,你不必像在最初的线性回归示例中那样手动定义在梯度下降过程中如何更新变量。 通常,你将使用内置的Keras优化器之一,例如SGD,RMSprop或Adam。
这是一个简单的MNSIT示例,它将损失类,度量类和优化器组合在一起。


Callback
fit的简洁功能之一(内置了对样本加权和类加权的支持)是你可以使用回调轻松自定义训练和评估期间发生的情况。
回调是一个对象,它在训练过程中的不同时间点被调用(例如在每个批处理的末尾或每个纪元的末尾)并执行任务。
有很多内置的回调,例如ModelCheckpoint可以在训练期间的每个时期之后保存模型,或者EarlyStopping可以在验证指标开始停止时中断训练。
你可以轻松编写自己的回调。

本教程获得了大家的一致好评,也体现出该教程的实用性和教学效果。由于微信公众号的限制我们只能列举其中部分内容向大家展示,完整笔记本请在电脑上打开以下链接:
https://colab.research.google.com/drive/1UCJt8EYjlzCs1H1d1X0iDGYJsHKwu-NO#scrollTo=88ExjKfCo7aP