
Keras 预处理层了解一下


发布人:Keras 开发者 Matthew Watson
构建模型的过程中,为数据确定正确的特征表征可能是最棘手的环节之一。想象一下,您正在处理分类输入特征,例如颜色名称。您可以对该特征进行独热编码,让每种颜色在特定的索引中得到一个 1 ('red' = [0, 0, 1, 0, 0]),或者嵌入该特征,让每种颜色映射到一个唯一的可训练向量 ('red' = [0.1, 0.2, 0.5, -0.2])。较大的类别空间可能更适合嵌入向量,而较小的空间则适合独热编码,但这并非明确的定论,还需要在您的特定数据集上进行实验。
理想情况下,我们希望在紧密的迭代循环中对特征表征和模型架构进行更新,在改变模型架构的同时,将新的转换应用至数据。在实践中,特征预处理和模型构建通常由完全不同的库、框架或语言进行处理,而这可能会减缓实验的进程。
Keras 团队最近发布了 Keras 预处理层,这是一组旨在让预处理数据更自然地融入模型开发工作流的 Keras 层。本文,我们将使用该层,通过 imdb 电影评论数据集来构建一个简单的看法分类模型,以展示如何灵活地开发和应用预处理。首先,我们可以导入 TensorFlow 并下载训练数据。
Keras 预处理层
https://tensorflow.google.cn/guide/keras/preprocessing_layers
Keras 层
https://keras.io/api/layers/
imdb 电影评论数据集
https://tensorflow.google.cn/datasets/catalog/imdb_reviews
import tensorflow as tf
import tensorflow_datasets as tfds
train_ds = tfds.load('imdb_reviews', split='train', as_supervised=True).batch(32)Keras 预处理层可以处理各类输入内容,包括结构化数据、图像和文本。本次示例,我们将处理原始文本,因此会使用 TextVectorization 层。
TextVectorization
https://tensorflow.google.cn/api_docs/python/tf/keras/layers/TextVectorization
默认情况下,TextVectorization 层将分三个阶段处理文本:
首先,移除标点符号,并将输入内容转换成小写。
接下来,将文本分割成单个字符串词的列表。
最后,使用已知词汇表将字符串映射为数字输出。
我们在此处可以尝试一个简单的方法,即多热编码,只考虑评论中是否存在术语。例如,假设层词汇表为 ['movie', 'good', 'bad'],而评论为 'This movie was bad.'。我们会将其编码为 [1, 0, 1],其中存在 movie(第一个词汇)和 bad(最后一个词汇)。
text_vectorizer = tf.keras.layers.TextVectorization(
output_mode='multi_hot', max_tokens=2500)
features = train_ds.map(lambda x, y: x)
text_vectorizer.adapt(features)在以上操作中,我们创建了一个具有多热输出的 TextVectorization 层,并做了两件事来设置该层的状态。首先,我们映射了训练数据集,舍弃了表示正面或负面评论的整型标签。由此获得了一个只包含评论文本的数据集。接下来,我们在这个数据集上采用 adapt() 方法处理该层,如此一来,该层就会学习所有文档中出现最频繁的词汇,上限为 2500 个。
adapt()
https://tensorflow.google.cn/guide/keras/preprocessing_layers#the_adapt_method
Adapt 是全部有状态预处理层上的一个实用函数,可支持层根据输入数据设置其内部状态。adapt 的调用向来都是选用项。对于 TextVectorization,我们可以在构建层时提供预计算的词汇表,而跳过 adapt 步骤。
现在我们可以在此多热编码的基础上训练简单的线性模型。我们将定义两个函数:preprocess,其可将原始输入数据转换为我们想要的模型表征;forward_pass,其可支持应用可训练层。
def preprocess(x):
return text_vectorizer(x)
def forward_pass(x):
return tf.keras.layers.Dense(1)(x) # Linear model
inputs = tf.keras.Input(shape=(1,), dtype='string')
outputs = forward_pass(preprocess(inputs))
model = tf.keras.Model(inputs, outputs)
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True))
model.fit(train_ds, epochs=5)这就是一个端到端的训练示例,已经足以达到 85% 的准确率。本文最后附上了这个示例的完整代码。
现在对新的特征进行实验。我们的多热编码不包含任何评论长度的概念,所以我们可以尝试添加归一化字符串长度的特征。可以根据需要将预处理层与 TensorFlow 算子和自定义层混合。我们可以在此将 tf.strings.length 函数与归一化层相结合,以此让输入的平均值为 0,方差为 1。我们只更新了以下 preprocess 函数的代码,但为了清晰起见,我们将展示其余的训练内容。
归一化
https://tensorflow.google.cn/api_docs/python/tf/keras/layers/Normalization
# This layer will scale our review length feature to mean 0 variance 1.
normalizer = tf.keras.layers.Normalization(axis=None)
normalizer.adapt(features.map(lambda x: tf.strings.length(x)))
def preprocess(x):
multi_hot_terms = text_vectorizer(x)
normalized_length = normalizer(tf.strings.length(x))
# Combine the multi-hot encoding with review length.
return tf.keras.layers.concatenate((multi_hot_terms, normalized_length))
def forward_pass(x):
return tf.keras.layers.Dense(1)(x) # Linear model.
inputs = tf.keras.Input(shape=(1,), dtype='string')
outputs = forward_pass(preprocess(inputs))
model = tf.keras.Model(inputs, outputs)
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True))
model.fit(train_ds, epochs=5)以上,我们创建了归一化层,并让其适应我们的输入。在 preprocess 函数中,我们只是串联了多热编码和长度特征。我们会根据这两个特征表征联合学习线性模型。
我们可以做的最后一个改变是加快训练速度。可以借助一个重要机会来提高我们的训练吞吐量。现在,在每一个训练步骤中,我们都要花一些时间在 CPU 上进行字符串操作(不能在加速器上运行),然后在 GPU 上计算损失函数和梯度。
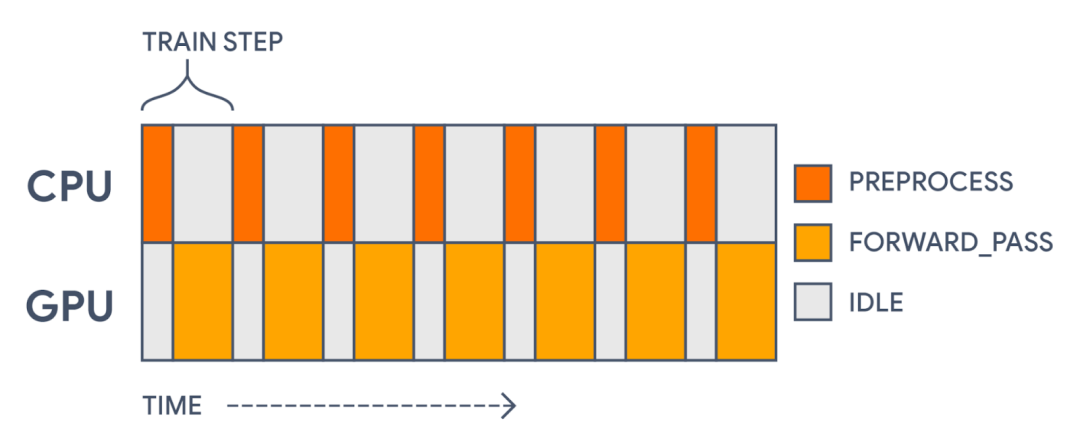
由于所有的计算都在一个模型中,我们会先在 CPU 上预处理每个批次,然后在 GPU 上更新参数权重。由此产生了 GPU 使用间隙
这种加速器使用间隙完全没有必要!预处理不同于模型的实际正向传递。预处理并不使用任何正在经受训练的参数。它是一个可以预先计算的静态转换。
为了加快进度,我们希望可以预提取预处理批次,如此一来,每次在一个批次上进行训练时,就会对下一个批次进行预处理。tf.data 库专为这样的用途构建而成,我们可在其助力下轻松地实现这一点。我们需要做的唯一重大改变是将单体式 keras.Model 一分为二:一个用于预处理,一个用于训练。利用 Keras 的函数式 API 很容易实现这一点。
tf.data
https://tensorflow.google.cn/guide/data
函数式 API
https://keras.io/guides/functional_api/
inputs = tf.keras.Input(shape=(1,), dtype="string")
preprocessed_inputs = preprocess(inputs)
outputs = forward_pass(preprocessed_inputs)
# The first model will only apply preprocessing.
preprocessing_model = tf.keras.Model(inputs, preprocessed_inputs)
# The second model will only apply the forward pass.
training_model = tf.keras.Model(preprocessed_inputs, outputs)
training_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True))
# Apply preprocessing asynchronously with tf.data.
# It is important to call prefetch and remember the AUTOTUNE options.
preprocessed_ds = train_ds.map(
lambda x, y: (preprocessing_model(x), y),
num_parallel_calls=tf.data.AUTOTUNE).prefetch(tf.data.AUTOTUNE)
# Now the GPU can focus on the training part of the model.
training_model.fit(preprocessed_ds, epochs=5在以上示例中,我们通过 preprocess 和 forward_pass 函数传递单个 keras.Input,但在转换后的输入上定义了两个独立的模型。这就把我们的单个操作图切成了两个。另一个有效方案是只构建训练模型,在对数据集进行映射时直接调用 preprocess 函数。在这种情况下,keras.Input 需要反映预处理特征的类型和形状,而不是原始字符串。
使用 tf.data 来预提取批次,可以将训练步骤的时间缩短 30% 以上!如今的计算时间如下图所示:
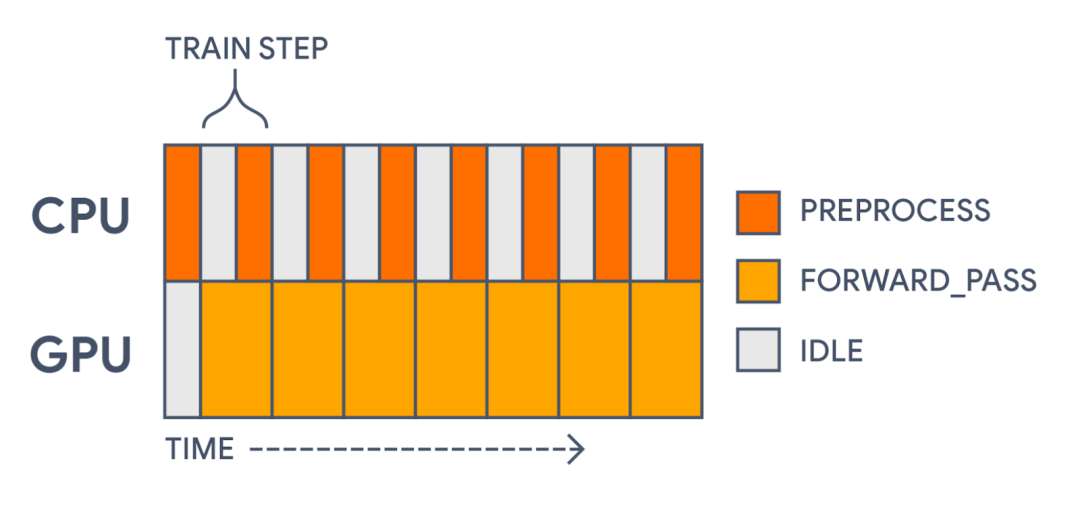
利用 tf.data,我们现在可以在 GPU 需要之前对每个预处理的批次进行预计算。这大幅提高了训练速度
我们甚至可以比这更进一步,使用 tf.data 在内存或磁盘上缓存我们的预处理数据集。只需在调用 prefetch 之前直接添加 .cache() 的调用即可。如此一来,我们就可以在训练的第一个纪元后完全跳过预处理批次的计算。
缓存
https://tensorflow.google.cn/api_docs/python/tf/data/Dataset#cache
训练结束后,我们可以在推理过程中把分块模型重新连接成单一的模型。这样便能够保存可以直接处理原始输入数据的模型。
inputs = preprocessing_model.input
outputs = training_model(preprocessing_model(inputs))
inference_model = tf.keras.Model(inputs, outputs)
inference_model.predict(
tf.constant(["Terrible, no good, trash.", "I loved this movie!"]))Keras 预处理层旨在提供一种灵活且富有表现力的方式来构建数据预处理流水线。预构建层可以与自定义层和其他 TensorFlow 函数混合和匹配。预处理可支持从训练中分离出来,并在 tf.data 的助力下得到有效应用,同时支持在日后进行连接以用于推理。我们希望它们能够在您的模型中对特征表征进行更加自然和高效的迭代。
欢迎点击此链接,在 Colab 中玩转本帖中的代码。有关预处理层可以帮助您执行哪些任务,可以在我们预处理指南的 Quick Recipes 部分中查看。
此链接
https://colab.research.google.com/gist/mattdangerw/521006cf44c1c1b3fa654112880ce4b5/keras-preprocessing-layers-sentiment-analysis-demo.ipynb
Quick Recipes
https://tensorflow.google.cn/guide/keras/preprocessing_layers#quick_recipes
您还可以进一步查看基本文本分类、图像数据增量和结构化数据分类的完整教程。
基本文本分类
https://tensorflow.google.cn/tutorials/keras/text_classification
图像数据增量
https://tensorflow.google.cn/tutorials/images/data_augmentation
结构化数据分类
https://tensorflow.google.cn/tutorials/structured_data/preprocessing_layers
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
