
Django数据库性能优化之 - 使用Python集合操作
PS:今天有两篇推送哦
人员基础信息(记作人员A),10w 某种类型的人员信息(记作人员B),1000
要求在后台上(Django Admin)分别展示:已录入A的人员B列表、未录入的人员B列表
团队的DBA提议使用视图可以解决这个问题(不愧是搞数据库的 )
)
PS:起先我觉得Django的Model是直接管理数据库表的,使用Model来映射数据库模型怕是有一定的麻烦,不过查了一下资料发现并不会~
只需要在Model的Meta子类中添加
managed = False即可,同时将db_table属性设置为视图名称

但这项目是Django写的,我认为既然有这么好用的ORM,何必多此一举去用SQL实现功能逻辑呢
于是大手一挥,不行,咱用Python来搞!
粗略实现
想想有挺多种方式来实现的,可以在Model中加一个方法,例如is_in_a(),然后在里面判断该人员B是否在人员A中
也可以在admin的配置中增加一个字段~
最终我是在Model中增加了新的方法,当然思路不必局限,Django还是很灵活的。
这个方法大概写成这样
def is_in_a(self) -> bool:
from apps.people.models import PersonA
queryset = PersonA.objects.filter(id_number=self.id_number)
return queryset.exists()
is_in_a.short_description = '是否已录入'
is_in_a.boolean = True
OK,没啥问题,接着配置一下admin
@admin.register(PersonB)
class PersonBAdmin(admin.ModelAdmin):
list_display = ['name', 'id_number', 'is_in_a']
这样就可以在后台上正常展示了 ,
,is_in_a就和普通的model字段一样使用
不过如果要加一个筛选功能的话,就不行,admin默认的list_filter只能支持数据库字段
要把我们自定义的字段加入筛选,就只能自己写一个Filter
首先来看一个错误的示范
class IsInAFilter(admin.SimpleListFilter):
title = '是否已录入'
parameter_name = 'is_in_a'
def lookups(self, request, model_admin):
return (
('true', '已录入'),
('false', '未录入')
)
def queryset(self, request, queryset):
raw_ids = []
if self.value() == 'true':
for item in queryset:
if item.is_in_a():
raw_ids.append(item.pk)
if self.value() == 'false':
for item in queryset:
if not item.is_in_a():
raw_ids.append(item.pk)
return queryset if self.value() is None else queryset.filter(pk__in=raw_ids)
写完了在admin的filter配置写上就行
list_filter = [IsInAFilter]
实现是实现了,但筛选的时候速度奇慢,因为渲染列表的时候,每一项都要访问一次数据库(恕我直言,这种代码就是shit)
PS:很遗憾,这代码是从我前年写的一个项目里copy过来的
(逃
优化思路
这我肯定不能忍啊
最讨厌的就是有人写了屎山代码
更何况这是自己写的shit,更不能忍了
立刻开始着手优化代码!
冷静下来,稍加思索
这个东西慢在于列表中的每一项都要去判断id_number在不在人员A中,那我改成批量判断不就好了?
一想到批量,我就想到values_list,用它来生成俩id_number的列表,既然有俩列表了,那这不就是集合操作了?
完事,开搞!
集合
首先复习一下集合哈
这应该是高中数学知识
集合,就是将数个对象归类而分成为一个或数个形态各异的大小整体。一般来讲,集合是具有某种特性的事物的整体,或是一些确认对象的汇集。构成集合的事物或对象称作“元素”或“成员”。集合的元素可以是任何事物,可以是人,可以是物,也可以是字母或数字等。
集合的三大特性
无序性:一个集合中,每个元素的地位都是相同的,元素之间是无序的。
集合上可以定义序关系,定义了序关系后,元素之间就可以按照序关系排序。但就集合本身的特性而言,元素之间没有必然的序。(参见序理论) 互异性:一个集合中,任何两个元素都认为是不相同的,即每个元素只能出现一次。
有时需要对同一元素出现多次的情形进行刻画,可以使用多重集,其中的元素允许出现多次。 确定性:给定一个集合,任给一个元素,该元素或者属于或者不属于该集合,二者必居其一,不允许有模棱两可的情况出现。
数学概念不用深究,编程语言中的集合与数学的集合也有些许不同,不过互异性是都有的,也就是集合中没有重复的元素。
集合操作
为了实现前文提到的性能优化,这里我们只需要掌握集合的几种运算就行
设a、b是两个不同的集合
a = set([1, 2, 3, 4])
b = set([3, 4, 5, 6])
四种操作直接看表格
| 计算 | 代码 | 说明 |
|---|---|---|
| 差集 | a - b | 集合a中包含而集合b中不包含的元素 |
| 并集 | `a | b` |
| 交集 | a & b | 集合a和b中都包含了的元素 |
| 对称差集 | a ^ b | 不同时包含于a和b的元素 |
为了便于理解,再来画个图
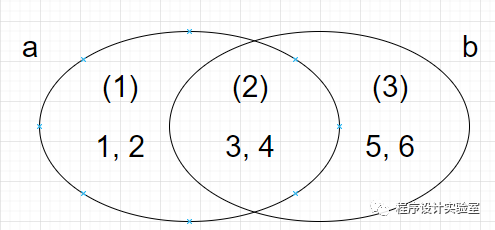
| 操作 | 结果 | 所得新集合元素 |
|---|---|---|
a - b | (1) | {1, 2} |
| `a | b` | (1) + (2) + (3) |
a & b | (2) | {3, 4} |
a ^ b | (1) + (3) | {1, 2, 5, 6} |
这下就很清楚了吧~
所以上面那个问题,简化成集合操作就是分别取交集和差集
最终实现
最终实现的代码不仅性能高起来了,代码量也比原来少,简直完美
def queryset(self, request, queryset):
from apps.people.models import PersonA
# 使用集合操作提高性能
set1 = set(PersonA.objects.values_list('id_number', flat=True))
set2 = set(queryset.values_list('id_number', flat=True))
id_numbers = set()
# 选择已录入的,取交集
if self.value() == 'true':
id_numbers = set1 & set2
# 选择未录入的,取差集
elif self.value() == 'false':
id_numbers = set2 - set1
return queryset if self.value() is None else queryset.filter(id_number__in=id_numbers)
搞定~!
等等
最后推荐一下我查资料过程中发现的好东西
Django ORM Cookbook
中文版地址:https://django-orm-cookbook-zh-cn.readthedocs.io/zh_CN/latest/index.html
这是一本书,顾名思义教你使用DjangoORM的,里面有50个例子,感觉挺不错的,可以查缺补漏~
Intermediate Python
中文版地址:https://eastlakeside.gitbook.io/interpy-zh/
也是一本书,中文名“Python进阶”,所以你应该知道里面讲啥了吧~
参考资料
集合 (数学) - 维基百科:https://zh.m.wikipedia.org/zh/集合_(数学) python set集合运算(交集,并集,差集,对称差集):https://blog.csdn.net/sxingming/article/details/51922776 Python集合(Set)常用操作:https://www.jianshu.com/p/f60fabfefc09 https://www.runoob.com/python3/python3-set.html