
【数据库优化】MySQL性能优化基础
同大多数关系型数据库一样,日志文件是MySQL数据库的重要组成部分。MySQL有几种不同的日志文件,通常包括错误日志文件,二进制日志,通用日志,慢查询日志,等等。这些日志可以帮助我们定位mysqld内部发生的事件,数据库性能故障,记录数据的变更历史,用户恢复数据库等等。
错误日志:记录启动、运行或停止mysqld时出现的问题。
通用日志:记录建立的客户端连接和执行的语句。
更新日志:记录更改数据的语句。该日志在MySQL 5.1中已不再使用。
二进制日志:记录所有更改数据的语句。还用于复制。
慢查询日志:记录所有执行时间超过long_query_time秒的所有查询或不使用索引的查询
Innodb日志:InnoDB redo log(记录了事务的行为,可以很好的通过其对页进行“重做”操作)
1. 开启慢查询日志
开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
通过show variables like 'slow_query%';查询是否开了慢查询(默认禁用OFF)
mysql> show variables like '%slow_query_log%';+---------------------+------------------------------------------------------+| Variable_name | Value |+---------------------+------------------------------------------------------+| slow_query_log | OFF || slow_query_log_file | D:\mysql-5.7.27-winx64\data\DESKTOP-E9F062A-slow.log |+---------------------+------------------------------------------------------+
slow_query_log 慢查询开启状态 OFF 未开启 ON 为开启slow_query_log_file 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
开启慢查询,需要设置slow_query_log参数。当然,如果不是调优需要的话,一般不建议开启该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志写入文件。
mysql> set global slow_query_log = 1; //设置开启或者关闭,0为关闭,1为开启mysql> set global long_query_time = 3; //设置慢的阙值时间,默认10秒
[mysqld]slow_query_log = 1 #开启slow_query_log_file = /mysql-5.7.27-winx64/data/mysql-slow.log #默认host_name_show.loglong_query_time = 3 #默认10秒(查询超过多少秒才记录)log-queries-not-using-indexes = on #如果值设置为ON,则会记录所有没有利用索引的查询,一般在性能调优的时候会暂时开启。log_output = 'FILE,TABLE' #输出的格式(FILE:文本, TABLE:表中, FILE,TABLE:同时输出到文本和表中)
如果通过终端命令设定的话,需要重新连接或新开一个会话才能看到修改值
使用set global slow_query_log 命令开启慢查询日志,只对当前数据库生效,如果Mysql重启后则会失效。如果要永久生效,必须修改my.cnf配置文件(其他系统变量也是如此)
插入一条测试慢查询
mysql> select sleep(5);通过MySQL命令查看有多少慢查询
mysql> show global status like '%Slow_queries%';+---------------+-------+| Variable_name | Value |+---------------+-------+| Slow_queries | 1 |+---------------+-------+
2. 慢查询日志分析工具
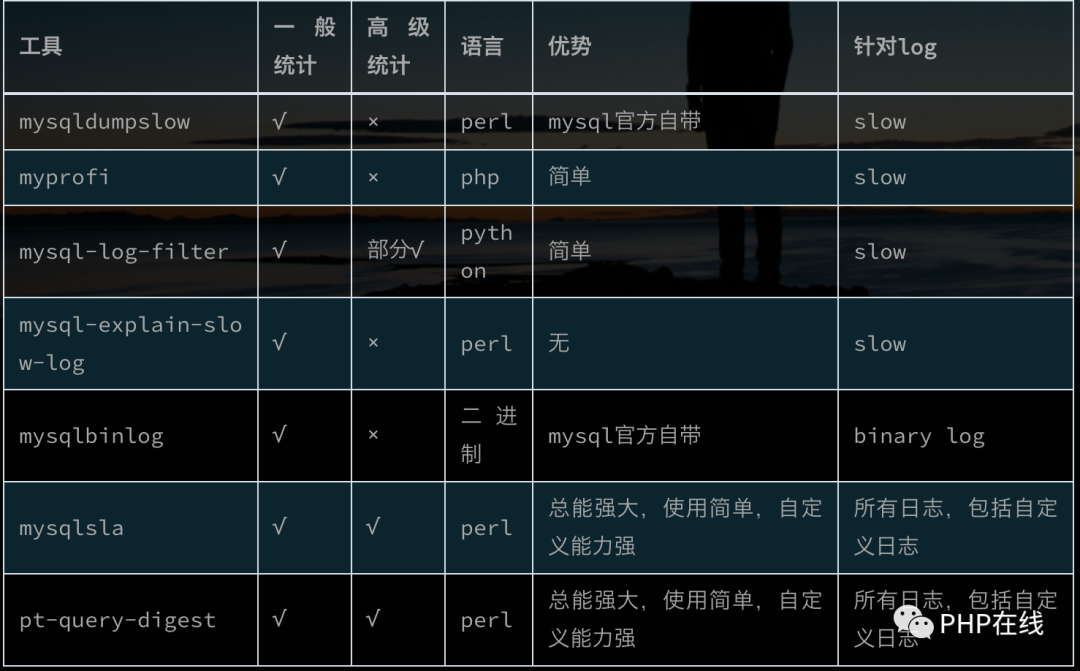
2.1 mysqldumpslow
MySQL自带的慢查询日志分析工具mysqldumpslow主要功能是, 统计不同慢sql的:
出现次数(Count),
执行最长时间(Time),
累计总耗费时间(Time),
等待锁的时间(Lock),
发送给客户端的行总数(Rows),
扫描的行总数(Rows),
用户以及sql语句本身(抽象了一下格式, 比如 limit 1, 20 用 limit N,N 表示).
安装后基本使用:
mysqldumpslow -s r -t 10 /data/mysql/mysql-slow.log //得到返回记录集最多的10个SQLmysqldumpslow -s c -t 10 /data/mysql/mysql-slow.log //得到访问次数最多的10个SQLmysqldumpslow -s t -t 10 -g "left join" /data/mysql/mysql-slow.log //得到按照时间排序的前10条里面含有做了连接的查询SQLmysqldumpslow -s r -t 10 /data/mysql/mysql-slow.log | more //另外建议在使用这些命令时结合|和more使用,否则有可能出现爆屏情况
2.2 mysqlsla
hackmysql.com推出的一款日志分析工具(该网站还维护了 mysqlreport, mysqlidxchk 等比较实用的mysql工具)
整体来说, 功能非常强大. 数据报表,非常有利于分析慢查询的原因, 包括执行频率, 数据量, 查询消耗等.
安装后基本使用方法:
mysqlsla -lt slow -sort t_sum -top 1000 /tmp/slow_query.log结果选项说明:总查询次数 (queries total),去重后的sql数量 (unique),输出报表的内容排序(sorted by),最重大的慢sql统计信息(包括 平均执行时间, 等待锁时间, 结果行的总数, 扫描的行总数)Count, sql的执行次数及占总的slow log数量的百分比.Time, 执行时间, 包括总时间, 平均时间, 最小, 最大时间, 时间占到总慢sql时间的百分比.95% of Time, 去除最快和最慢的sql, 覆盖率占95%的sql的执行时间.Lock Time, 等待锁的时间.95% of Lock , 95%的慢sql等待锁时间.Rows sent, 结果行统计数量, 包括平均, 最小, 最大数量.Rows examined, 扫描的行数量.Database, 属于哪个数据库Users, 哪个用户,IP, 占到所有用户执行的sql百分比Query abstract, 抽象后的sql语句Query sample, sql语句mysqlsla常用参数说明:-log-type (-lt) type logs:通过这个参数来制定log的类型,主要有slow, general, binary, msl, udl,分析slow log时通过制定为slow-sort:t_sum:按总时间排序(默认),c_sum:按总次数排序c_sum_p: sql语句执行次数占总执行次数的百分比。-top:显示sql的数量,默认是10,表示按规则取排序的前多少条–statement-filter (-sf) [+-][TYPE]:过滤sql语句的类型,比如select、update、drop,[TYPE] 有SELECT, CREATE, DROP, UPDATE, INSERT,例如”+SELECT,INSERT”,不出现的默认是-,即不包括。-db:要处理哪个库的日志:
# 举个例子,只取funsion数据库的select语句,并按照总时间排序,取前1000条数据# 保存到当前目录下的 slow_query.pretty.log文件中mysqlsla -lt slow -sort t_sum -sf "+select" -db funsion -top 1000 /tmp/slow_query.log > ./slow_query.pretty.log
2.3 pt-query-digest
pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog、General log、slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdump抓取的MySQL协议数据来进行分析。可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。
# 分析最近12小时内的查询:pt-query-digest --since=12h slow.log > slow_report2.log
pt-query-digest语法及重要选项
pt-query-digest [OPTIONS] [FILES] [DSN]--create-review-table 当使用--review参数把分析结果输出到表中时,如果没有表就自动创建。--create-history-table 当使用--history参数把分析结果输出到表中时,如果没有表就自动创建。--filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析--limit 限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。--host mysql服务器地址--user mysql用户名--password mysql用户密码--history 将分析结果保存到表中,分析结果比较详细,下次再使用--history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review时,如果存在相同的语句分析,就不会记录到数据表中。--output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。--until 截止时间,配合—since可以分析一段时间内的慢查询。
分析pt-query-digest输出结果
总体统计结果
Overall:总共有多少条查询
Time range:查询执行的时间范围
unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询
total:总计 min:最小 max:最大 avg:平均
95%:把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值
median:中位数,把所有值从小到大排列,位置位于中间那个数
查询分组统计结果
Rank:所有语句的排名,默认按查询时间降序排列,通过–order-by指定
Query ID:语句的ID,(去掉多余空格和文本字符,计算hash值)
Response:总的响应时间
time:该查询在本次分析中总的时间占比
calls:执行次数,即本次分析总共有多少条这种类型的查询语句
R/Call:平均每次执行的响应时间
V/M:响应时间Variance-to-mean的比率
Item:查询对象
每一种查询的详细统计结果
由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
ID:查询的ID号,和上图的Query ID对应
Databases:数据库名
Users:各个用户执行的次数(占比)
Query_time distribution :查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量是10s以上的两倍。
Tables:查询中涉及到的表
Explain:SQL语句
3. explain查看执行计划
在上面的慢查询中,我们已经将查询时间超过阀值的sql语句过滤了出来,explain+查询语句具体分析是哪里出了问题。
MySQL 提供了一个 Explain 命令, 它可以对 select 语句进行分析, 并输出 select 执行的详细信息, 以供开发人员针对性优化.
mysql> explain select * from user_info where id = 2\G*************************** 1. row ***************************id: 1select_type: SIMPLEtable: user_infopartitions: NULLtype: constpossible_keys: PRIMARYkey: PRIMARYkey_len: 8ref: constrows: 1filtered: 100.00Extra: NULL1 row in set, 1 warning (0.06 sec)
各列的含义如下:id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.select_type: SELECT 查询的类型.SIMPLE, 表示此查询不包含 UNION 查询或子查询PRIMARY, 表示此查询是最外层的查询UNION, 表示此查询是 UNION 的第二或随后的查询DEPENDENT UNION, UNION 中的第二个或后面的查询语句, 取决于外面的查询UNION RESULT, UNION 的结果SUBQUERY, 子查询中的第一个 SELECTDEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果.table: 查询的是哪个表partitions: 匹配的分区type: join 类型type字段比较重要, 它提供了判断查询是否高效的重要依据依据. 通过type字段, 我们判断此次查询是 全表扫描 还是 索引扫描 等.system: 表中只有一条数据. 这个类型是特殊的 const 类型.const: 针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可.eq_ref: 此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是 =, 查询效率较高.ref: 此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了 最左前缀 规则索引的查询.range: 表示使用索引范围查询, 通过索引字段范围获取表中部分数据记录. 这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中.index: 表示全索引扫描(full index scan), 和 ALL 类型类似, 只不过 ALL 类型是全表扫描, 而 index 类型则仅仅扫描所有的索引, 而不扫描数据.ALL: 表示全表扫描, 这个类型的查询是性能最差的查询之一. 通常来说, 我们的查询不应该出现 ALL 类型的查询, 因为这样的查询在数据量大的情况下, 对数据库的性能是巨大的灾难.possible_keys: 此次查询中可能选用的索引表示 MySQL 在查询时, 能够使用到的索引. 注意, 即使有些索引在 possible_keys 中出现, 但是并不表示此索引会真正地被 MySQL 使用到. MySQL 在查询时具体使用了哪些索引, 由 key 字段决定.key: 此字段是 MySQL 在当前查询时所真正使用到的索引.key_len: 表示查询优化器使用了索引的字节数. 这个字段可以评估组合索引是否完全被使用, 或只有最左部分字段被使用到.ref: 哪个字段或常数与 key 一起被使用rows: 显示此查询一共扫描了多少行. 这个是一个估计值.rows 也是一个重要的字段. MySQL 查询优化器根据统计信息, 估算 SQL 要查找到结果集需要扫描读取的数据行数, 这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好.filtered: 表示此查询条件所过滤的数据的百分比extra: EXplain 中的很多额外的信息会在 Extra 字段显示Using filesort: 当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大.Using index: “覆盖索引扫描”, 表示查询在索引树中就可查找所需数据, 不用扫描表数据文件, 往往说明性能不错Using temporary: 查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高, 建议优化.type 类型的性能比较通常来说, 不同的 type 类型的性能关系如下:ALL < index < range ~ index_merge < ref < eq_ref < const < systemALL 类型因为是全表扫描, 因此在相同的查询条件下, 它是速度最慢的.而 index 类型的查询虽然不是全表扫描, 但是它扫描了所有的索引, 因此比 ALL 类型的稍快.后面的几种类型都是利用了索引来查询数据, 因此可以过滤部分或大部分数据, 因此查询效率就比较高了.
4. MySQL性能分析语句show profile
Query Profile是MySQL自带的一种Query诊断分析工具,可以完整的显示一条sql执行的各方面的详细信息,默认关闭;
看看当前的MySQL版本是否支持: show variables like 'profiling';或show variables like 'profiling%';mysql> show variables like 'profiling%';+------------------------+-------+| Variable_name | Value |+------------------------+-------+| profiling | OFF || profiling_history_size | 15 |+------------------------+-------+
使用前需要开启: set profiling = 1; (1:开 / 0:关)
mysql> set profiling = 1;