
ElasticSearch 查询的性能与评分问题

Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,它天生支持分布式搜索机制,具有搜索、分析、挖掘海量数据的能力,同时还是一个可扩展、近实时的搜索引擎。

本文主要分析ElasticSearch分布式搜索的机制,比较不同的搜索类型,并针对ElasticSearch在搜索过程中存在的一些问题进行分析,同时给出优化方案。
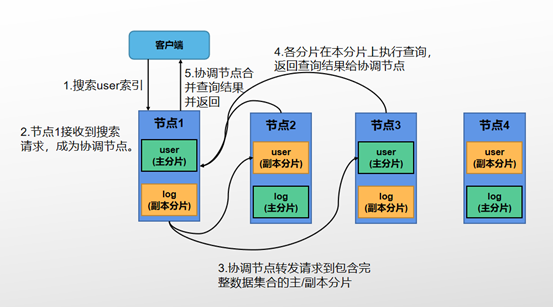
ES分布式搜索过程中,需要将请求分发到所有相关的分片,并将各分片的结果聚合到一起。故搜索过程分为两个阶段:Query和Fetch。假设集群设置为2个主分片、1个副本分片,即每个索引会有4个主副本分片。如图所示:
Query阶段:
1.用户搜索请求到ES集群的某一个节点上,该节点收到用户请求后,以协调节点的身份,在4个分片中随机选择2个分片(构成完整的数据集),将请求分发到对应分片所在的数据节点上。
2.各节点收到请求后,搜索相关分片上的文档,根据本分片上词频及文档频率进行相关性评分计算,同时根据分值进行排序,返回from+size个排序后结果给协调节点,这个结果并不包含全部的文档信息,仅提供足够协调节点对所有结果进行合并重排序的信息。
Fetch 阶段:
协调节点会将Query阶段从每个分片上获取到的排序后的结果重新进行排序及合并,按照集群配置,协调节点总共会收到2*(from+size)个结果,根据重新排序的结果选取from+size个结果,同时根据结果中的文档ID,去对应的分片根据文档ID获取详细文档数据,返回给客户端。
ES的这种查询方式存在两个问题:
1.性能问题
在查询过程中,每个分片需要返回的文档个数为:from+size个,协调节点需要汇总处理number_of_shards*(from+size)个文档,ES为了避免深度分页消耗节点过多内存,默认限定只能查询10000个文档,from+size的数量越大(出现深度分页情况),协调节点处理的数据越多,占用协调节点的内存越大,给协调节点带来较大压力。
2.评分问题
在查询过程中,为文档相关性评分计算都是基于本分片上的词频和文档频率进行的,而协调节点排序是基于各分片评分的结果进行综合排序的,各分片的评分依据不一致,会导致相关性评分偏离的问题;在主分片数量大于1的情况下,如果主分片数里越多,相关性算法会越不准。
针对以上的两个问题,ES提供了一些解决方案:
针对性能问题(深度分页问题),ES有两种用于查询深度分页情况下的查询方法:Search After,使用search after进行查询时,每次查询时会返回当前页的sort值,可以根据sort值查询下一页的数据。使用Search after时多个分页请求需要有相同的查询和排序参数。如果多次分页请求之间,ES进行了refresh操作(即index-buffer中的数据写入到segment,这时index-buffer中的数据将能被查询到),这样会导致排序结果的改变,使得跨页的排序结果不一致。为了避免发生这种情况,可以通过创建PIT的方式,在多次分页请求中保持当前索引的状态,获取PIT时可以指定keep_alive参数,指定PIT存在的时间。
例:POST /my-index-000001/_pit?keep_alive=1m
该API返回一个PIT ID:


第一次查询时,带上PIT ID,同时在sort参数中,需要指定一个唯一的排序字段,这个字段的取值是唯一的(例如doc IDs),如果排序参数中没有这个字段,则有可能会丢失结果或者出现重复结果。
查询返回结果:
返回结果中,会有sort值,在查询下一页时,带上前一页查询返回的sort值,即可实现向下翻页。如果使用了PIT需要一并放在查询参数中。

通过重复这个查询操作即可实现滚动翻页的功能。查询完毕后应该通过DELETE /_pit接口将PIT删除。
Search After存在的局限性:不支持指定页数,即不能设定from参数,只能从第一页开始往后进行;只支持向后翻页,不能跨页访问,只能从当前页一页一页往后翻。Scroll API(当前版本7.11已不再推荐使用Scroll进行深度分页,在这里还是介绍一下这种查询方式)
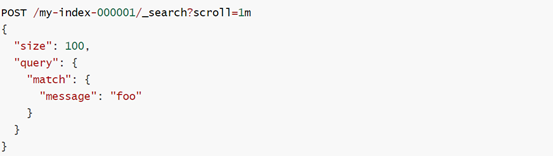
Scroll查询方式的原理相当于对当前查询创建一个快照,后面的每次查询,都基于第一次查询创建的快照进行。在第一次查询时,需要在请求中指定scroll参数,并设置快照保存的时间。如scroll=1m即该查询的快照将被保持一分钟。
查询将会返回_scroll_id,_scroll_id一般不会发生变化,但是以防万一,下一个查询的请求最好还是使用上一个查询请求返回的_scroll_id。当查询只需要返回全量文档,不考虑文档排序值时,可将sort值指定为_doc,这样可以优化查询的速度。可以通过 POST /_search/scroll 接口更新scroll保存的时间。
因为scroll是对当前查询创建一个副本快照,会占用较大的内存,所以当scroll使用完毕后,需要及时对scroll进行清理。可以使用DELETE /_search/scroll {scroll_id:””}的方式进行。es对scroll的最大数量进行了限制,默认可以创建500个scroll,可以通过search.max_open_scroll_context参数进行设置。
scroll存在的局限性:因为是对查询结果创建快照进行查询,所以当查询期间,如果有新数据写入,这些新增的数据将无法被查询到。
根据以上对不同查询类型的分析,可以得出不同搜索类型的适用场景:
普通from+size查询方式:适用于只需要获取排序靠前的部分文档。
Search after查询方式:适用于深度分页情况。
Scroll查询方式:适用于单个请求需要获取大量文档的情况。
评分问题
1.当数据量不大时,将主分片的数量设置为1,当数据量很大时,保证文档均匀分布在各个分片上。
2.使用DFS Query Then Fetch,这样在搜索的时候各个分片会收集词频和文档频率,然后根据这些词频和文档频率统一进行相关性评分计算,这样文档的相关性评分最为准确。但是一般不建议使用这种方式,因为会耗费较多的CPU和内存。
作者:中国农业银行研发中心 王灿
![]()