
Elasticsearch 如何实现时间差查询?
1、Elasticsearch 线上实战问题
问个问题啊,es能通过两个字段差值进行查询吗?类似select * from myindex where endtimes- starttime > 10这种?
——问题来源:死磕Elasticsearch 知识星球
那么问题来了,Elasticsearch 如何实现时间差的查询呢?
2、先说一下 MySQL 实现
2.1 MySQL 表结构

2.2 MySQL 样例数据

2.3 MySQL 计算时间差?
select timestampdiff(MINUTE, start_time, end_time) as span from test;
结果如下:
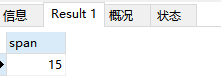
结果 15 代表 15 分钟的意思。
3、Elasticsearch 实现拆解
3.1 创建索引
PUT test-index-001
{
"mappings": {
"properties": {
"starttime": {
"type": "date"
},
"endtime": {
"type": "date"
}
}
}
}
3.2 插入数据
POST test-index-001/_bulk
{"index":{"_id":1}}
{"starttime":"2022-06-08T10:00:00Z","endtime":"2022-06-08T10:15:00Z"}
3.3 方案一:直接类MySQL 查询实现
POST test-index-001/_search
{
"query": {
"bool": {
"filter": {
"script": {
"script": {
"source": "doc['endtime'].date.minuteOfDay - doc['starttime'].date.minuteOfDay >= 15",
"lang": "expression"
}
}
}
}
}
}
解读一下:
lang 指的是脚本语言,这里使用的是:expression,不是 painless 无痛脚本,所以写法和往常会不同。

更多推荐查看:
3.4 方案二:ingest 预处理空间换时间实现
核心使用的是:painless 无痛脚本。在对时间的脚本处理上略显笨拙(大家有好的方法可以交流)。
步骤1:时间字段转成字符串; 步骤2:字符串转成 ZonedDateTime字段类型;步骤3:ZonedDateTime 字段类型转成 long长整形。步骤4:求解两个整形之差就可以了。
实现如下代码所示:
PUT _ingest/pipeline/my_pipeline_20220618
{
"processors": [
{
"script": {
"lang": "painless",
"source": """
String start_datetime = ctx.starttime;
ZonedDateTime start_zdt = ZonedDateTime.parse(start_datetime);
String end_datetime =ctx.endtime;
ZonedDateTime end_zdt = ZonedDateTime.parse(end_datetime);
long start_millisDateTime = start_zdt.toInstant().toEpochMilli();
long end_millisDateTime = end_zdt.toInstant().toEpochMilli();
long elapsedTime = end_millisDateTime - start_millisDateTime;
ctx.span = elapsedTime/1000/60;
"""
}
}
]
}
POST test-index-001/_update_by_query?pipeline=my_pipeline_20220618
{
"query": {
"match_all": {}
}
}
POST test-index-001/_search
{
"query": {
"range": {
"span": {
"gte": 15
}
}
}
}
如上 update_by_query 的实现完全可以转换为预处理+setting环节的 default_pipeline 方式实现,确保写入环节直接生成span字段值,确保候选实现空间换时间,提高检索效率。
default_pipeline 实现如下:
PUT test-20220619-10-02
{
"settings": {
"default_pipeline": "my_pipeline_20220618"
},
"mappings": {
"properties": {
"start_time": {
"type": "date"
},
"end_time": {
"type": "date"
}
}
}
}
### 步骤2:导入数据
PUT test-20220619-10-02/_doc/1
{
"start_time": "2022-01-01T12:00:30Z",
"end_time": "2022-01-01T12:15:30Z"
}
### 方案二优势地方:时间差值已经成为我们新的字段,直接用这个字段
POST test-20220619-10-02/_search
{
"query": {
"range": {
"span": {
"gte": 15
}
}
}
}
如上实现,更简洁写法如下:
PUT _ingest/pipeline/my_pipeline_20220618_03
{
"processors": [
{
"script": {
"lang": "painless",
"source": """
// create a Instant object
Instant start_instant = Instant.parse(ctx.starttime);
// get millisecond value using toEpochMilli()
long start_millisDateTime = start_instant.toEpochMilli();
// create a Instant object
Instant end_instant= Instant.parse(ctx.endtime);
// get millisecond value using toEpochMilli()
long end_millisDateTime = end_instant.toEpochMilli();
long elapsedTime = end_millisDateTime - start_millisDateTime;
ctx.span = elapsedTime/1000/60;
"""
}
}
]
}
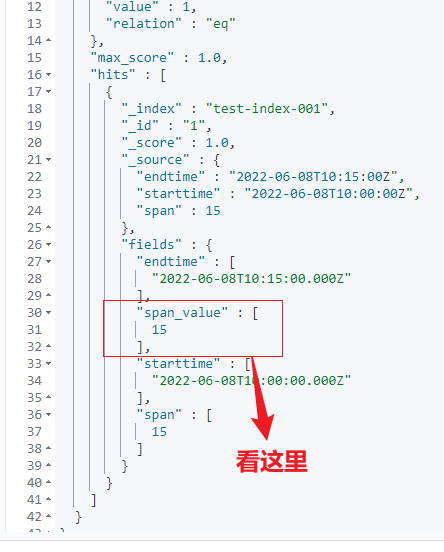
3.5 方案三:runtime_field 实时检索实现
POST test-index-001/_search
{
"fields": [
"*"
],
"runtime_mappings": {
"span_value": {
"type": "long",
"script": {
"source": "emit((doc['endtime'].getValue().toInstant().toEpochMilli() - doc['starttime'].getValue().toInstant().toEpochMilli())/60000)"
}
}
}
}
核心:同样是转化为毫秒,然后做的计算。
注意:fields 要设置,否则数据 _source 下不显示。
4、小结
关于 Elasticsearch 实现时间差查询,本文给出三种不同方案实现,视频解读如下。
从简洁程度推荐方案 1 或者方案 3。
从性能角度推荐方案 2 ——空间换时间,方案 2 可以优化为写入的时候指定 default_pipeline 全部预处理实现。
你的业务环境有没有遇到类似问题,你是如何实现的呢?
参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting-expression.html
https://www.elastic.co/guide/en/elasticsearch/reference/5.0/modules-scripting-expression.html#datefield_api
https://www.elastic.co/guide/en/elasticsearch/painless/master/painless-datetime.html#_datetime_input_from_an_indexed_document
https://www.elastic.co/guide/en/elasticsearch/painless/current/painless-api-reference-shared-java-time.html
推荐阅读
更短时间更快习得更多干货!
和全球 1600+ Elastic 爱好者一起精进!
