
聊聊推荐系统中的偏差
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


文 | 成指导
源 | 知乎
 背景
背景
推荐系统中大量使用用户行为数据,作为系统学习的标签或者说信号。但用户行为数据天生存在各式各样的偏差(bias),如果直接作为信号的话,学习出的模型参数不能准确表征用户在推荐系统中的真实行为意图,造成推荐效果的下降。
因此,本篇聊一聊推荐系统中常见的偏差,与相应的去偏思路与方法。本篇的主要脉络依据中科大何向南教授、合工大汪萌教授联合在 TKDE 上的一篇综述文章展开:Bias and Debias in Recommender System: A Survey and Future Directions。
推荐的反馈闭环
推荐系统是由用户、数据、模型,三者互相作用产生的一个动态的反馈闭环。闭环分为三个阶段:
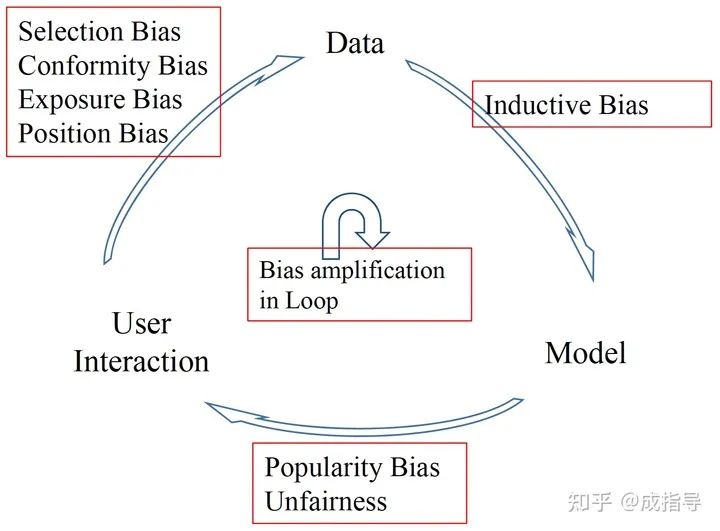
User -> Data
用户会产生大量的 user-item(对抖音是用户-视频、对头条是用户-文章)交互数据,以及各类周边信息包括 user 特征、item 属性、交互上下文信息等。其中 user-item 交互数据中 user 集合被表示成 ,item 集合被表示成 。
user 与 item 两者间互相作用形成反馈矩阵(feedback matrix),类型分为两种:
隐式反馈:表示为 ,矩阵中元素 是二值化 0、1 取值表示 user u 是否发生与 item i 的交互行为(bool 类型,例如购买、点击、查看等行为) 显式反馈:表示为 ,矩阵中元素 是 user u 对 item i 的评分(float 类型,例如豆瓣评分)
Data -> Model
根据历史观测数据,训练模型预测 user 是否采纳 item 的程度。
Model -> User
模型返回预测推荐结果给到用户,进一步影响用户的未来行为和决策。
三个阶段不断循环,在闭环中逐渐加剧各阶段的 bias,会造成更严重的问题。
常见偏差
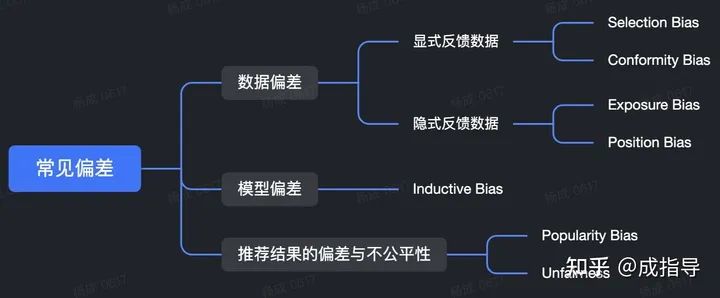
数据偏差
显式反馈数据 - Selection Bias
定义:当用户可以自由选择 item 进行评分,可观测到的评分并不是所有评分的有代表性样本。换而言之,评分数据是“非随机缺失”(missing not at random, MNAR)的
这个偏差的来源比较好理解,我们也可以想想自己是不是也是这样:倾向于评分喜爱的 item(例如,热衷粉丝的电影、歌曲等) ,倾向于评分特别好或者特别差的 item(例如,去看电影很想夸好片,很想喷烂片)
显式反馈数据 - Conformity Bias
定义:用户评分倾向于与其他人相似,即使是完全基于他们自己的判断,也会受到影响
这个偏差是由从众心理导致的。对于大众一致喜欢/讨厌的 item,个体用户做判断时经常会受到外界声音的影响
隐式反馈数据 - Exposure Bias
定义:仅有一部分特定 item 曝光给了用户,因此没有观测到的交互行为并不直接等同于是训练中的负例
可以想一想,对于没有产生交互行为(没有点击、购买等行为)的数据样本而言,其实是由 2 个原因造成:
用户的确不喜欢当前 item; 当前 item 没有曝光给用户(对于从没刷到过的视频,我们无法确定自己是否喜欢)
对于数据曝光问题,之前的研究有几个角度:
当前版本的曝光取决于上一个推荐系统版本的策略,决定了如何展现; 因为用户会主动搜索或寻找感兴趣的 item,因此用户选择成为了影响曝光的因素,使得高度相关/吸引力(例如标题党、美女图片类新闻)的 item 更容易被曝光; 用户的背景关系是影响曝光的一个因素,例如好友、社区、地理位置等因素会影响曝光; 流行的 item 会更容易曝光给用户,因此 Popularity Bias 是另一种形式 Exposure Bias
隐式反馈数据 - Position Bias
定义:用户倾向于无视相关性地去对推荐列表中更高位置上的 item 产生交互行为
位置偏差在搜索系统中是一个经典并持续存在的偏差,同样在推荐系统中也会存在,用户普遍会对于头部观测到的 item 产生更多点击(还没有产生审美疲劳?)。尤其会对“用户点击行为”作为正例信号进行学习的模型,位置偏差会在训练、评估阶段产生错误影响
模型偏差
Inductive Bias
偏差不一定总是有害的,实际上一些归纳偏差被故意加入到模型设计中为了实现某些特性
定义:为了模型更好地学习目标函数并且泛化到训练数据上,会设置一些模型假设。假设未必都是准确的,会产生一些偏差
列举某些经典的假设(未必造成有害影响):
用户交互行为可以由向量内积表示 Adaptive negative sampler 提出用于增加学习速度,即使结果损失函数不同于最初分布 CNN 网络的局部特征重要性
推荐结果的偏差与不公平性
Popularity Bias
定义:流行的 item 会被更频繁地推荐、产生用户交互
长尾效应或者说二八定律带来了这个偏差,会降低个性化层次、用户对于平台的惊喜体验,造成马太效应
Unfairness
定义:整个系统不公平歧视某些群体用户
这个偏差的本质原因是数据的不平衡性,会带来社会性问题(年龄、性别、种族、社交关系多少等歧视)。不公平的数据,会造成更不公平的用户体验,产生恶循环
不公平性更多是由于系统数据分布不平衡造成的,例如某个基本由中老年用户组成的 app 较难对于年轻用户的行为进行建模,系统推荐出的视频会更倾向于有“年代感”
反馈闭环加剧各类偏差
User->Data->Model->User 的不断循环,会在已有偏差的基础上,进一步放大偏差
这篇文章简单介绍了一些推荐系统中常见的偏差 bias,并进行了一些简单的分类。这里的分类体系并非绝对合理但却具有一定代表性。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!