
实战总结!18种接口优化方案的总结

前言
之前工作中,遇到一个504超时问题。原因是因为接口耗时过长,超过nginx配置的10秒。然后 真枪实弹搞了一次接口性能优化,最后接口从11.3s降为170ms。本文将跟小伙伴们分享接口优化的一些通用方案。
1. 批量思想:批量操作数据库
优化前:
//for循环单笔入库
for(TransDetail detail:transDetailList){
insert(detail);
}
优化后:
batchInsert(transDetailList);
打个比喻:
打个比喻:假如你需要搬一万块砖到楼顶,你有一个电梯,电梯一次可以放适量的砖(最多放
500), 你可以选择一次运送一块砖,也可以一次运送500,你觉得哪种方式更方便,时间消耗更少?
2. 异步思想:耗时操作,考虑放到异步执行
耗时操作,考虑用异步处理,这样可以降低接口耗时。
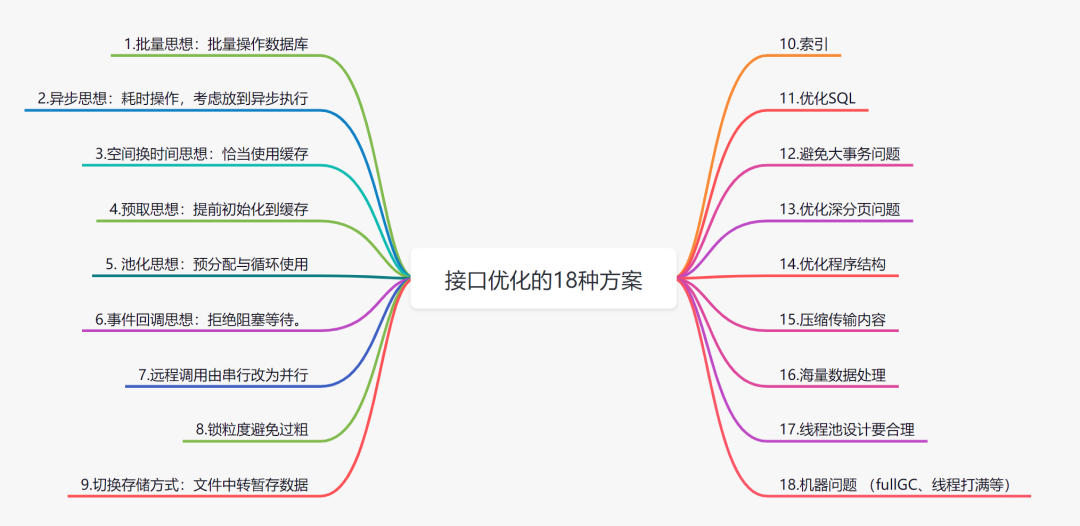
假设一个转账接口,匹配联行号,是同步执行的,但是它的操作耗时有点长,优化前的流程:
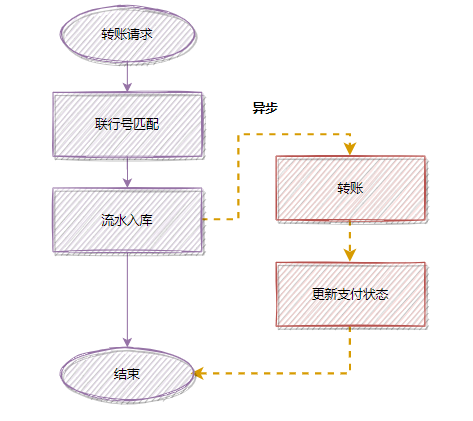
为了降低接口耗时,更快返回,你可以把匹配联行号移到异步处理,优化后:
除了转账这个例子,日常工作中还有很多这种例子。比如:用户注册成功后,短信邮件通知,也是可以异步处理的~ 至于异步的实现方式,你可以用线程池,也可以用消息队列实现。
3. 空间换时间思想:恰当使用缓存。
在适当的业务场景,恰当地使用缓存,是可以大大提高接口性能的。缓存其实就是一种空间换时间的思想,就是你把要查的数据,提前放好到缓存里面,需要时,直接查缓存,而避免去查数据库或者计算的过程。
这里的缓存包括:Redis缓存,JVM本地缓存,memcached,或者Map等等。我举个我工作中,一次使用缓存优化的设计吧,比较简单,但是思路很有借鉴的意义。
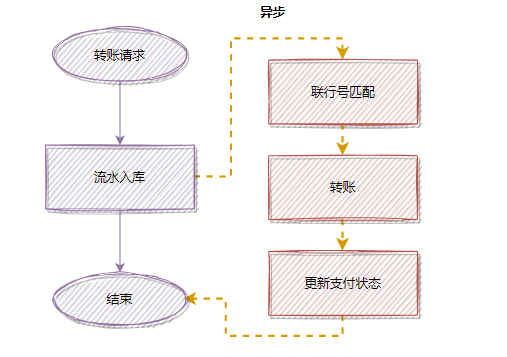
那是一次转账接口的优化,老代码,每次转账,都会根据客户账号,查询数据库,计算匹配联行号。
因为每次都查数据库,都计算匹配,比较耗时,所以使用缓存,优化后流程如下:
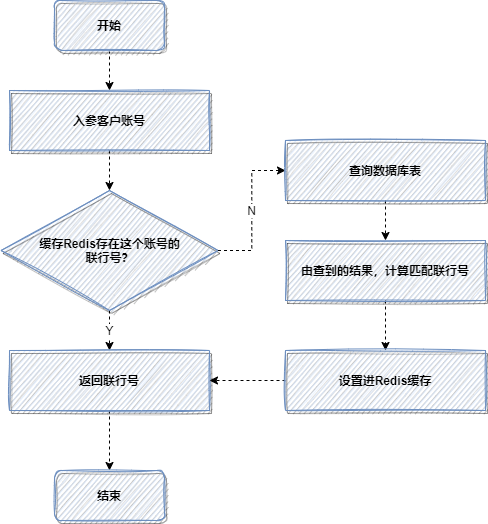
4. 预取思想:提前初始化到缓存
预取思想很容易理解,就是提前把要计算查询的数据,初始化到缓存。如果你在未来某个时间需要用到某个经过复杂计算的数据,才实时去计算的话,可能耗时比较大。这时候,我们可以采取预取思想,提前把将来可能需要的数据计算好,放到缓存中,等需要的时候,去缓存取就行。这将大幅度提高接口性能。
我记得以前在第一个公司做视频直播的时候,看到我们的直播列表就是用到这种优化方案。就是启动个任务,提前把直播用户、积分等相关信息,初始化到缓存。
5. 池化思想:预分配与循环使用
大家应该都记得,我们为什么需要使用线程池?
线程池可以帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。
如果你每次需要用到线程,都去创建,就会有增加一定的耗时,而线程池可以重复利用线程,避免不必要的耗时。 池化技术不仅仅指线程池,很多场景都有池化思想的体现,它的本质就是预分配与循环使用。
比如TCP三次握手,大家都很熟悉吧,它为了减少性能损耗,引入了Keep-Alive长连接,避免频繁的创建和销毁连接。当然,类似的例子还有很多,如数据库连接池、HttpClient连接池。
我们写代码的过程中,学会池化思想,最直接相关的就是使用线程池而不是去new一个线程。
6. 事件回调思想:拒绝阻塞等待。
如果你调用一个系统B的接口,但是它处理业务逻辑,耗时需要10s甚至更多。然后你是一直阻塞等待,直到系统B的下游接口返回,再继续你的下一步操作吗?这样显然不合理。
我们参考IO多路复用模型。即我们不用阻塞等待系统B的接口,而是先去做别的操作。等系统B的接口处理完,通过事件回调通知,我们接口收到通知再进行对应的业务操作即可。
7. 远程调用由串行改为并行
假设我们设计一个APP首页的接口,它需要查用户信息、需要查banner信息、需要查弹窗信息等等。如果是串行一个一个查,比如查用户信息200ms,查banner信息100ms、查弹窗信息50ms,那一共就耗时350ms了,如果还查其他信息,那耗时就更大了。
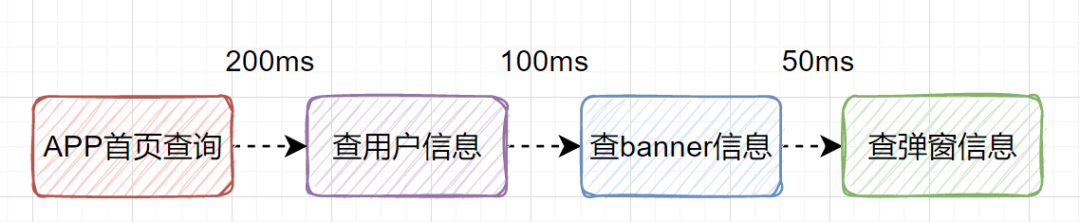
其实我们可以改为并行调用,即查用户信息、查banner信息、查弹窗信息,可以同时并行发起。
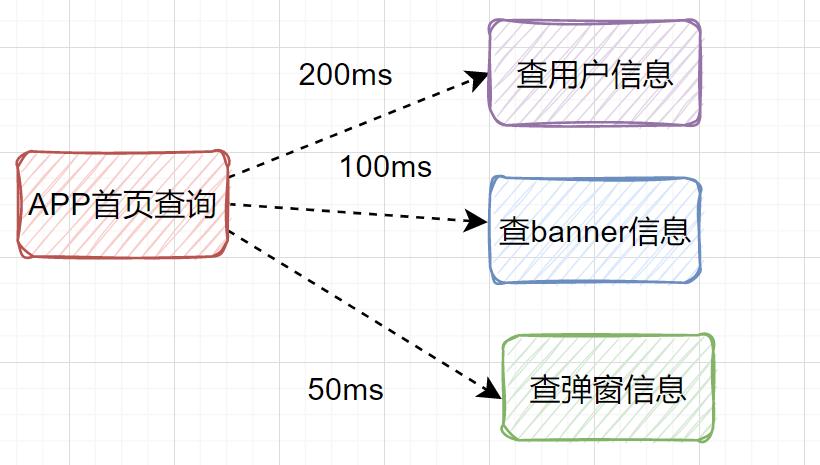
最后接口耗时将大大降低。有些小伙伴说,不知道如何使用并行优化接口?
8. 锁粒度避免过粗
在高并发场景,为了防止超卖等情况,我们经常需要加锁来保护共享资源。但是,如果加锁的粒度过粗,是很影响接口性能的。
什么是加锁粒度呢?
其实就是就是你要锁住的范围是多大。比如你在家上卫生间,你只要锁住卫生间就可以了吧,不需要将整个家都锁起来不让家人进门吧,卫生间就是你的加锁粒度。
不管你是synchronized加锁还是redis分布式锁,只需要在共享临界资源加锁即可,不涉及共享资源的,就不必要加锁。这就好像你上卫生间,不用把整个家都锁住,锁住卫生间门就可以了。
比如,在业务代码中,有一个ArrayList因为涉及到多线程操作,所以需要加锁操作,假设刚好又有一段比较耗时的操作(代码中的slowNotShare方法)不涉及线程安全问题。反例加锁,就是一锅端,全锁住:
//不涉及共享资源的慢方法
private void slowNotShare() {
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
}
}
//错误的加锁方法
public int wrong() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
//加锁粒度太粗了,slowNotShare其实不涉及共享资源
synchronized (this) {
slowNotShare();
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
正例:
public int right() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
slowNotShare();//可以不加锁
//只对List这部分加锁
synchronized (data) {
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
9. 切换存储方式:文件中转暂存数据
如果数据太大,落地数据库实在是慢的话,就可以考虑先用文件的方式暂存。先保存文件,再异步下载文件,慢慢保存到数据库。
这里可能会有点抽象,给大家分享一个,我之前的一个真实的优化案例吧。
之前开发了一个转账接口。如果是并发开启,10个并发度,每个批次
1000笔转账明细数据,数据库插入会特别耗时,大概6秒左右;这个跟我们公司的数据库同步机制有关,并发情况下,因为优先保证同步,所以并行的插入变成串行啦,就很耗时。
优化前,1000笔明细转账数据,先落地DB数据库,返回处理中给用户,再异步转账。如图:
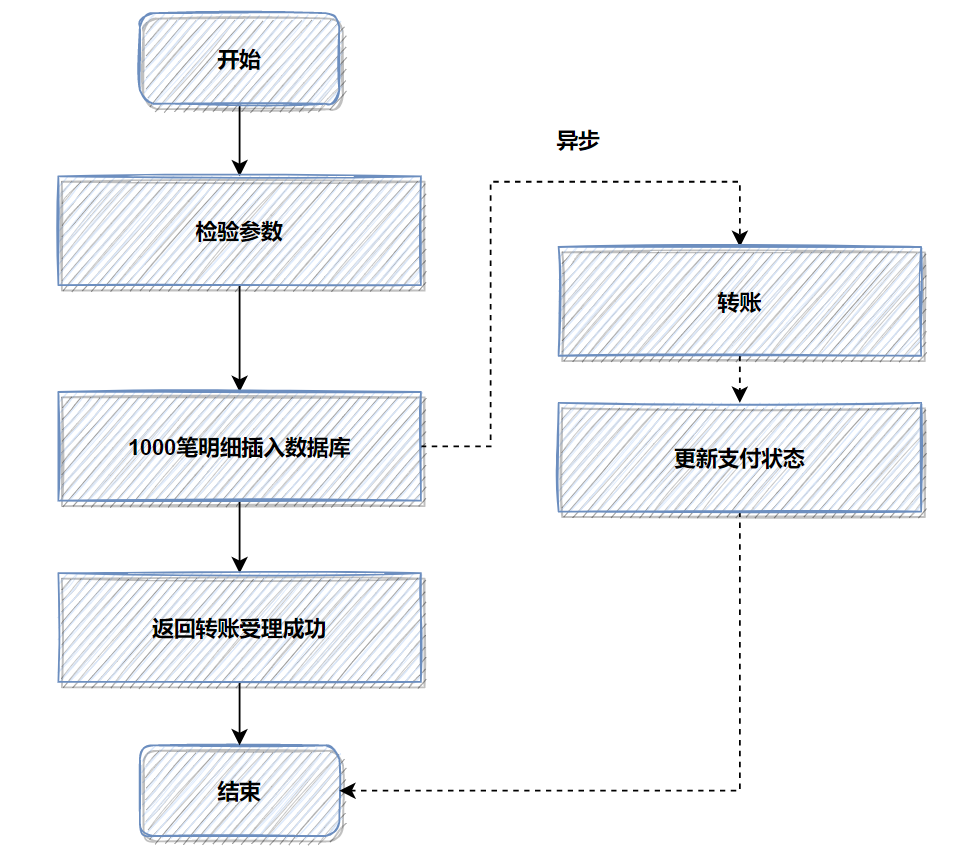
记得当时压测的时候,高并发情况,这1000笔明细入库,耗时都比较大。所以我转换了一下思路,把批量的明细转账记录保存的文件服务器,然后记录一笔转账总记录到数据库即可。接着异步再把明细下载下来,进行转账和明细入库。最后优化后,性能提升了十几倍。
优化后,流程图如下:
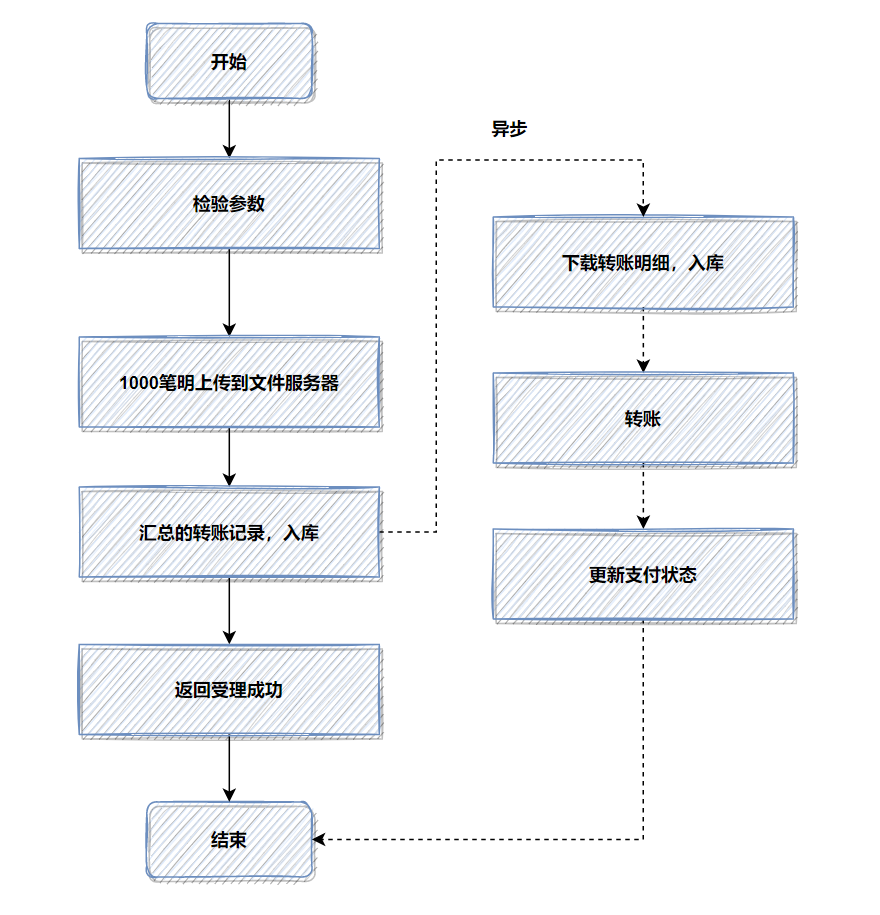
如果你的接口耗时瓶颈就在数据库插入操作这里,用来批量操作等,还是效果还不理想,就可以考虑用文件或者MQ等暂存。有时候批量数据放到文件,会比插入数据库效率更高。
10. 索引
提到接口优化,很多小伙伴都会想到添加索引。没错,添加索引是成本最小的优化,而且一般优化效果都很不错。
索引优化这块的话,一般从这几个维度去思考:
你的SQL加索引了没? 你的索引是否真的生效? 你的索引建立是否合理?
10.1 SQL没加索引
我们开发的时候,容易疏忽而忘记给SQL添加索引。所以我们在写完SQL的时候,就顺手查看一下 explain执行计划。
explain select * from user_info where userId like '%123';
你也可以通过命令show create table ,整张表的索引情况。
show create table user_info;
如果某个表忘记添加某个索引,可以通过alter table add index命令添加索引
alter table user_info add index idx_name (name);
一般就是:SQL的where条件的字段,或者是order by 、group by后面的字段需需要添加索引。
10.2 索引不生效
有时候,即使你添加了索引,但是索引会失效的。田螺哥整理了索引失效的常见原因:
10.3 索引设计不合理
我们的索引不是越多越好,需要合理设计。比如:
删除冗余和重复索引。 索引一般不能超过 5个索引不适合建在有大量重复数据的字段上、如性别字段 适当使用覆盖索引 如果需要使用 force index强制走某个索引,那就需要思考你的索引设计是否真的合理了
11. 优化SQL
处了索引优化,其实SQL还有很多其他有优化的空间。比如这些:
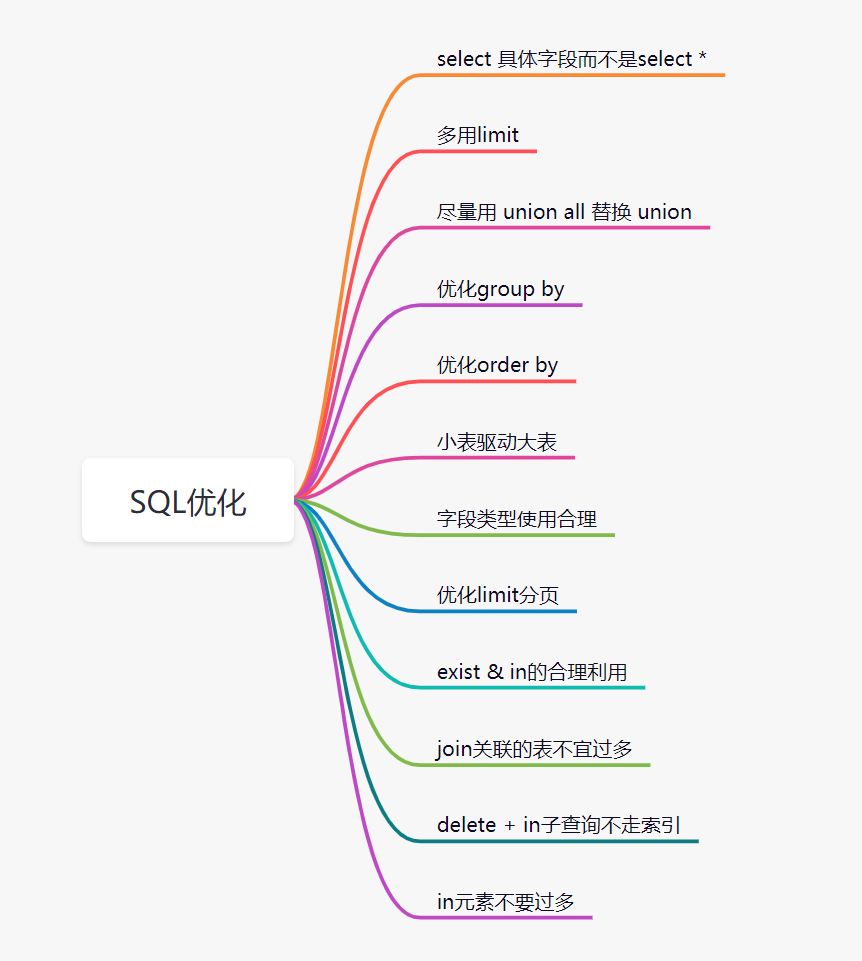
12.避免大事务问题
为了保证数据库数据的一致性,在涉及到多个数据库修改操作时,我们经常需要用到事务。而使用spring声明式事务,又非常简单,只需要用一个注解就行@Transactional,如下面的例子:
@Transactional
public int createUser(User user){
//保存用户信息
userDao.save(user);
passCertDao.updateFlag(user.getPassId());
return user.getUserId();
}
这块代码主要逻辑就是创建个用户,然后更新一个通行证pass的标记。如果现在新增一个需求,创建完用户,调用远程接口发送一个email消息通知,很多小伙伴会这么写:
@Transactional
public int createUser(User user){
//保存用户信息
userDao.save(user);
passCertDao.updateFlag(user.getPassId());
sendEmailRpc(user.getEmail());
return user.getUserId();
}
这样实现可能会有坑,事务中嵌套RPC远程调用,即事务嵌套了一些非DB操作。如果这些非DB操作耗时比较大的话,可能会出现大事务问题。
所谓大事务问题就是,就是运行时间长的事务。由于事务一致不提交,就会导致数据库连接被占用,即并发场景下,数据库连接池被占满,影响到别的请求访问数据库,影响别的接口性能。
大事务引发的问题主要有:接口超时、死锁、主从延迟等等。因此,为了优化接口,我们要规避大事务问题。我们可以通过这些方案来规避大事务:
RPC远程调用不要放到事务里面 一些查询相关的操作,尽量放到事务之外 事务中避免处理太多数据
13. 深分页问题
在以前公司分析过几个接口耗时长的问题,最终结论都是因为深分页问题。
深分页问题,为什么会慢?我们看下这个SQL
select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;
limit 100000,10意味着会扫描100010行,丢弃掉前100000行,最后返回10行。即使create_time,也会回表很多次。
我们可以通过标签记录法和延迟关联法来优化深分页问题。
13.1 标签记录法
就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到啦。
假设上一次记录到100000,则SQL可以修改为:
select id,name,balance FROM account where id > 100000 limit 10;
这样的话,后面无论翻多少页,性能都会不错的,因为命中了id主键索引。但是这种方式有局限性:需要一种类似连续自增的字段。
13.2 延迟关联法
延迟关联法,就是把条件转移到主键索引树,然后减少回表。优化后的SQL如下:
select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 on acct1.id= acct2.id;
优化思路就是,先通过idx_create_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。
14. 优化程序结构
优化程序逻辑、程序代码,是可以节省耗时的。比如,你的程序创建多不必要的对象、或者程序逻辑混乱,多次重复查数据库、又或者你的实现逻辑算法不是最高效的,等等。
我举个简单的例子:复杂的逻辑条件,有时候调整一下顺序,就能让你的程序更加高效。
假设业务需求是这样:如果用户是会员,第一次登陆时,需要发一条感谢短信。如果没有经过思考,代码直接这样写了
if(isUserVip && isFirstLogin){
sendSmsMsg();
}
假设有5个请求过来,isUserVip判断通过的有3个请求,isFirstLogin通过的只有1个请求。那么以上代码,isUserVip执行的次数为5次,isFirstLogin执行的次数也是3次,如下:

如果调整一下isUserVip和isFirstLogin的顺序:
if(isFirstLogin && isUserVip ){
sendMsg();
}
isFirstLogin执行的次数是5次,isUserVip执行的次数是1次:

酱紫程序是不是变得更高效了呢?
15. 压缩传输内容
压缩传输内容,传输报文变得更小,因此传输会更快啦。10M带宽,传输10k的报文,一般比传输1M的会快呀。
打个比喻,一匹千里马,它驮着100斤的货跑得快,还是驮着10斤的货物跑得快呢?
再举个视频网站的例子:
如果不对视频做任何压缩编码,因为带宽又是有限的。巨大的数据量在网络传输的耗时会比编码压缩后,慢好多倍。
16. 海量数据处理,考虑NoSQL
之前看过几个慢SQL,都是跟深分页问题有关的。发现用来标签记录法和延迟关联法,效果不是很明显,原因是要统计和模糊搜索,并且统计的数据是真的大。最后跟组长对齐方案,就把数据同步到Elasticsearch,然后这些模糊搜索需求,都走Elasticsearch去查询了。
我想表达的就是,如果数据量过大,一定要用关系型数据库存储的话,就可以分库分表。但是有时候,我们也可以使用NoSQL,如Elasticsearch、Hbase等。
17. 线程池设计要合理
我们使用线程池,就是让任务并行处理,更高效地完成任务。但是有时候,如果线程池设计不合理,接口执行效率则不太理想。
一般我们需要关注线程池的这几个参数:核心线程、最大线程数量、阻塞队列。
如果核心线程过小,则达不到很好的并行效果。 如果阻塞队列不合理,不仅仅是阻塞的问题,甚至可能会 OOM如果线程池不区分业务隔离,有可能核心业务被边缘业务拖垮。
大家可以看下我之前两篇有关于线程池的文章:
18.机器问题 (fullGC、线程打满、太多IO资源没关闭等等)。
有时候,我们的接口慢,就是机器处理问题。主要有fullGC、线程打满、太多IO资源没关闭等等。
之前排查过一个 fullGC问题:运营小姐姐导出60多万的excel的时候,说卡死了,接着我们就收到监控告警。后面排查得出,我们老代码是Apache POI生成的excel,导出excel数据量很大时,当时JVM内存吃紧会直接Full GC了。如果线程打满了,也会导致接口都在等待了。所以。如果是高并发场景,我们需要接入限流,把多余的请求拒绝掉。 如果IO资源没关闭,也会导致耗时增加。这个大家可以看下,平时你的电脑一直打开很多很多文件,是不是会觉得很卡。