
你了解如何用GAN做语义分割吗
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文主要推荐一篇使用GAN来做语义分割的论文。
论文名称: SemanticSegmentationusingAdversarialNetworks 、
论文链接: https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1611.08408.pdf
目前,对抗学习的方法生成图像已经有比较好的效果,在这篇论文中,作者提出了一种使用对抗训练方法来训练语义分割模型。同时训练卷积语义分割网络以及对抗网络,具体做法是在GAN的Generator中使用语义分割的网络,Generator输入原图,输出预测的分割图,Discriminator再对抗学习,区分GroundTruth和Generator生成的预测分割图。而使用GAN有什么意义呢?论文作者提出采用这样的方法可以检测和纠正分割预测图与GroundTruth的higher-order不一致性。
作者使用两个loss来监督。第一个是多个类别的交叉熵损失,这个loss主要是监督每个像素都能预测出正确的类别。第二个loss基于辅助对抗卷积网络,由于对抗卷积网络的视野要么是整个图像,要么是图像的很大一部分,因此higher-order label统计中的不匹配会受到对抗性损失的惩罚,这个是按照像素进行分类无法实现的(例如,用某类标记的像素区域的形状,或某类区域中的像素分数是否超过阈值)功能。
作者使用s(x)表示在给定大小为HxWx3的输入RGB图像x的情况下,分割模型生成的C个大小为HxWxC的类的类概率图。使用a(x,y)来表示输入是x时,对抗模型预测y是GroundTruth的概率,而不是由分割模型s( ·)预测的输出。给定N个训练图像xn的数据集和相应的标签yn,将损失定义为如下图:
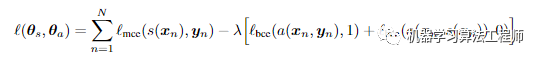
训练对抗模型主要是优化第二个损失,即下图的二进制分类损失:
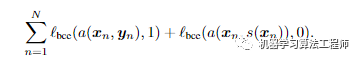
训练分割模型主要是减少多个类别的交叉熵损失,同时降低对抗模型的性能,使得分割模型生成的预测图对于Discriminator来说,很难将其与GroundTruth区分,相关的损失函数如下所示:
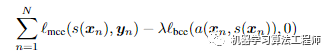

在下图,作者给出了使用和不使用对抗训练的情况下使用此网络生成的分割结果。对抗训练可以更好地加强类别标签之间的空间一致性。它可以改善和强化大面积类别的概率,例如概率图描绘了天空和草丛,但也锐化了阶级界限,并在小范围内删除了错误预测的类别标签。 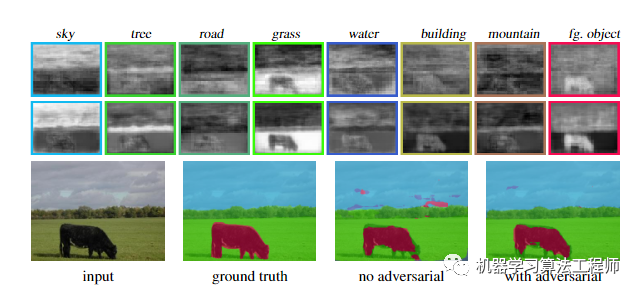
在两个数据集上的结果如下两表: 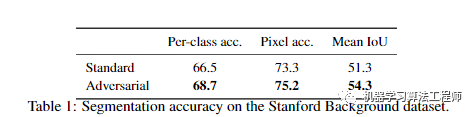


END
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~