
Intel Xeon 144核处理器Sierra Forest和Granite Rapids架构介绍


在Hot Chips 2023上,英特尔首次公布了其未来144核至强Sierra Forest和Granite Rapids处理器的详细信息,前者由英特尔的新Sierra Glen e核组成,而后者采用了新的Redwood Cove p核。即将推出的下一代至强芯片将于明年上半年推出,采用全新的平铺式架构,在“Intel 7”工艺上采用双I/O小芯片,并在“Intel 3”工艺上蚀刻不同配置的计算核心。这种设计使英特尔能够在保持相同底层配置的同时,基于不同类型的核心制作多种产品。
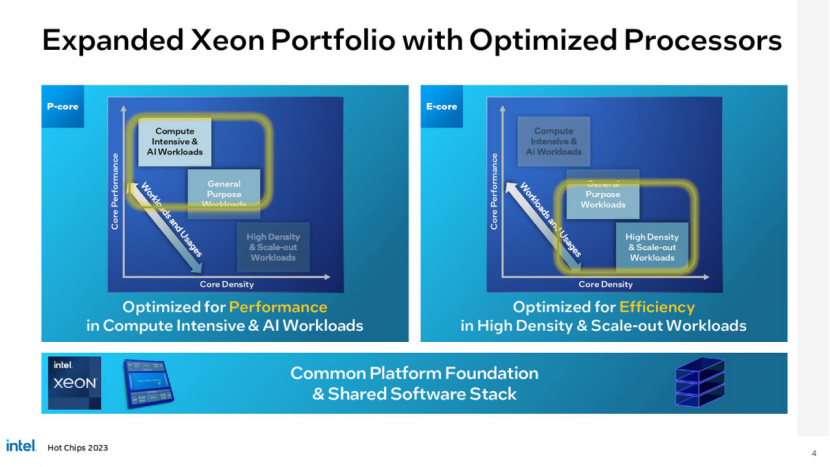
Sierra Forest和Granite Rapids加入了Birch Stream平台,具有插座、内存、固件和I/O兼容性,提供了简化的硬件验证过程。它们还可以与相同的软件堆栈进行互操作,从而允许客户根据自己的需要使用任意一种芯片。
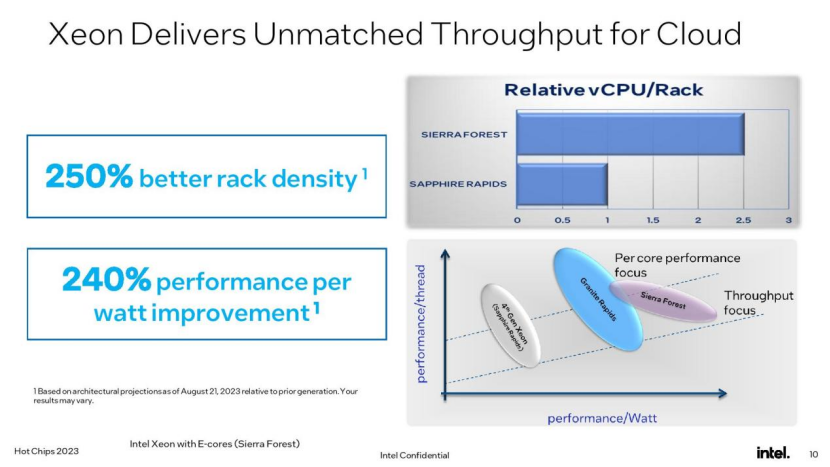
英特尔声称,下一代至强Sierra Forest基于e- core的设计将比其第四代至强芯片提供高达2.5倍的机架密度和2.4倍的每瓦性能,而P-Core驱动的Granite Rapids将在混合人工智能工作负载下提供2到3倍的性能,部分原因是内存带宽高达2.8倍。本文一起深入了解一下。
 Sierra Forest和Granite Rapids架构
Sierra Forest和Granite Rapids架构 
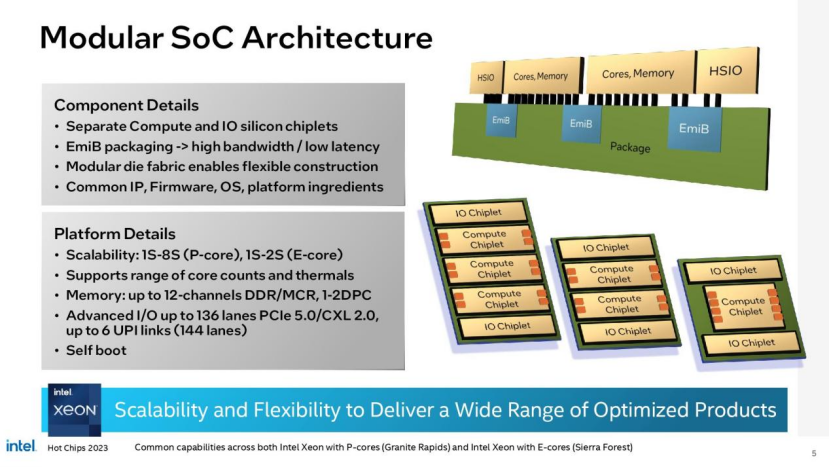

英特尔最初在其第四代Xeon Sapphire Rapids处理器上采用了基于磁片(芯片式)的架构,但Sierra Forest和Granite Rapids将这种方法推向了一个新的高度。
英特尔采用了Sapphire Rapids的四芯片设计,每个芯片包含一部分相关的I/O功能,如内存和PCIe控制器。新处理器将一些I/O功能完全分解为两个独立的hio芯片,这些芯片蚀刻在Intel 7进程上,这为I/O提供了成本、功率和性能的最佳平衡,而CPU核心和内存控制器则驻留在它们自己的专用计算芯片上。
两个HSIO芯片放置在芯片封装的顶部和底部,中间有一到三个计算芯片,所有芯片都与基片内融合的EMIB(嵌入式多模互连桥)互连连接在一起,并连接到桥的每一端的模对模互连。
计算模块将为Granite Rapids使用Redwood Cove p核(Performance核),或为Sierra Forest使用Sierra Glen e核——英特尔不会在同一包中提供两种核的模型。计算芯片配备了支持euv的Intel 3进程,该进程具有Intel 4进程不包含的高密度库。英特尔最初将Granite Rapids xeon从2023年推迟到2024年,原因是将设计从“Intel 4”改为“Intel 3”,但这些芯片仍按计划将在2024年上半年推出。
Granite Rapids是一个传统的Xeon数据中心处理器。这些型号仅配备P核,可以提供英特尔最快架构的全部性能。每个P核均配有2MB的L2缓存和4MB的L3。英特尔尚未透露Granite Rapids的核心数量,但透露该平台在单个服务器中支持一到八个插槽。
与此同时,Sierra Forest的E-core(效率核心)阵容由只有较小效率核心的芯片组成,就像我们在英特尔的Alder和Raptor Lake芯片中看到的那样,这使它们能够很好地与在数据中心日益流行的Arm处理器竞争。e核被安排在两核或四核集群中,这些集群共享4MB的L2缓存片和3MB的L3缓存。配备e- core的处理器拥有多达144个内核,并针对最高的功率效率、面积效率和性能密度进行了优化。对于高核数模型,每个e核计算芯片拥有48个核。Sierra Forest可以插入单插座和双插座系统,TDP低至200W。
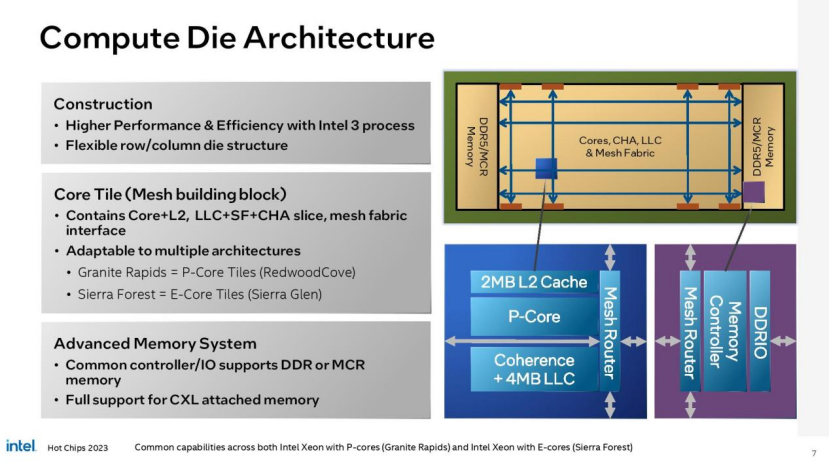
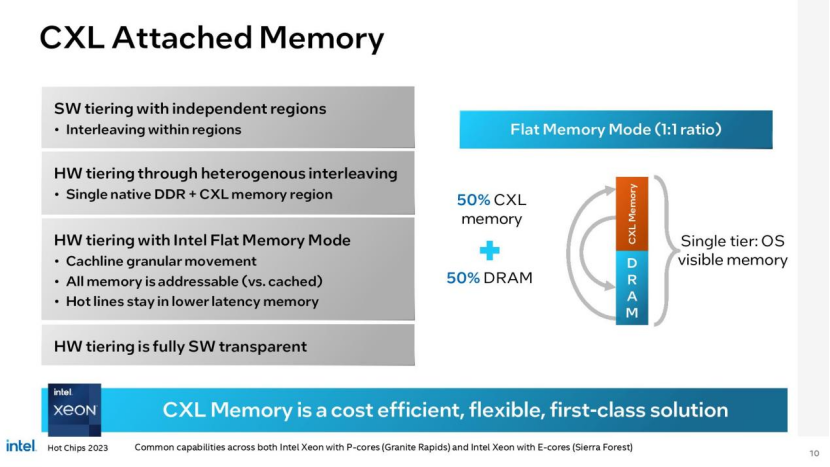
无论内核类型如何,每个计算模块都包含内核、L2和L3缓存以及fabric和缓存主代理(CHA)。它们还在芯片的两端安装了DDR5-6400内存控制器,总共有多达12个通道(1DPC或2DPC)的标准DDR内存,或提供比标准dimm多30-40%内存带宽的新MCR内存。
正如您在上面看到的那样,计算芯片将根据模型有不同的尺寸,单计算芯片产品将带有更大的计算集群。英特尔还将改变每个计算芯片的内存通道数量——这里我们看到一个计算芯片上有三个内存控制器,而两个或更多计算芯片的设计每个有两个内存控制器。英特尔决定将其内存控制器紧密集成到计算芯片中,与AMD的EPYC设计相比,在某些工作负载下,英特尔的内存性能应该会更好。AMD的EPYC设计在一个中央I/O芯片上使用了所有内存控制器,从而增加了延迟。
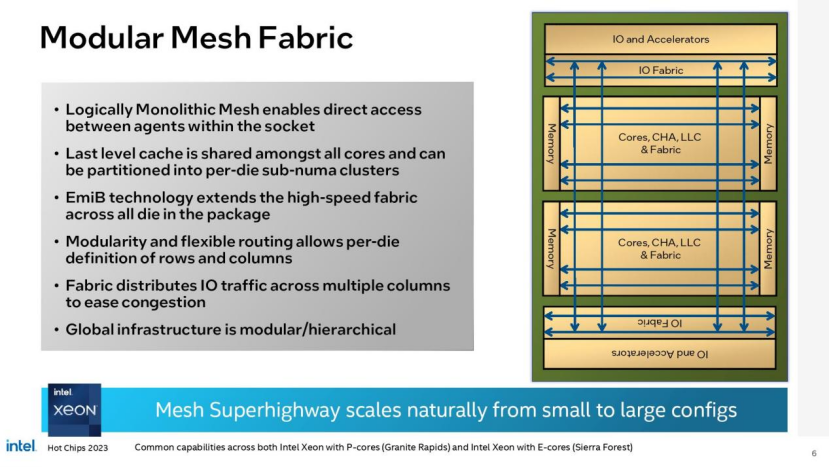
计算模块与所有其他内核共享L3缓存,英特尔将其称为“逻辑单片网格”,但它们也可以划分为sub-NUMA集群,以优化某些工作负载的延迟。网格将L3缓存片连接在一起,形成一个统一的共享缓存,总容量超过0.5 gb,几乎是Sapphire Rapids的5倍。每个模具边界支持超过TB/s的带宽之间的模具。
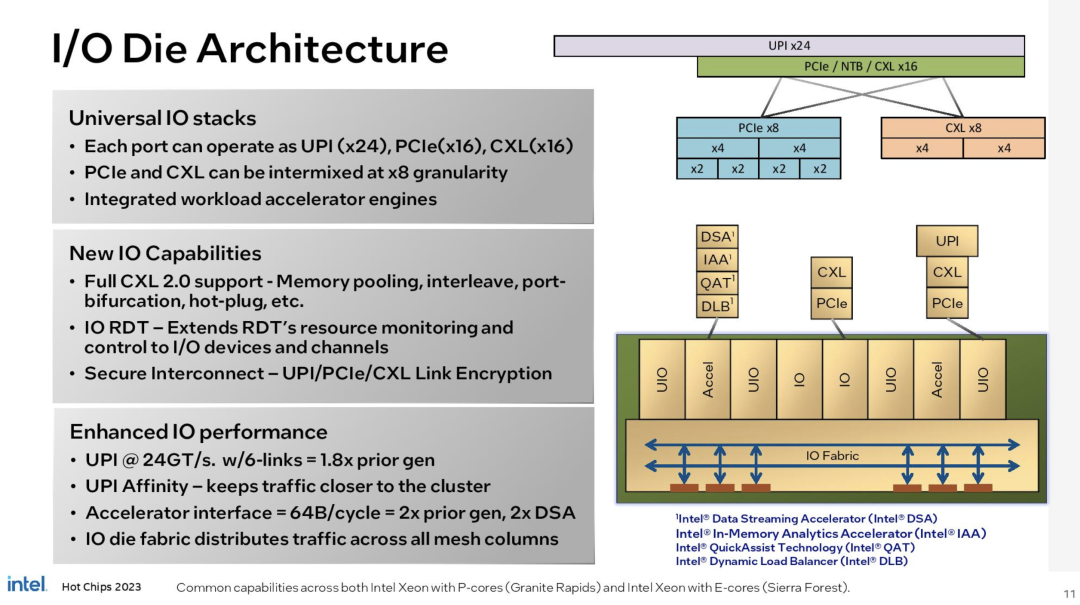
结合起来,两个HSIO芯片支持多达136个PCIe 5.0/CXL 2.0通道(类型1,2和3设备),多达6个UPI链路(144通道),以及类似于Sapphire Rapids加速引擎的压缩,加密和数据流加速器。每个HSIO芯片还包括管理计算芯片的电源控制电路,尽管每个计算芯片也有自己的电源控制,可以在需要时独立运行。英特尔现在已经取消了对芯片组(PCH)的要求,从而允许处理器自动启动,就像AMD的EPYC处理器一样。
英特尔Sierra Glen E-Core微架构 Sierra Glen微架构针对标量吞吐量工作负载(如横向扩展、云原生和容器化环境)的最佳效率进行了优化。该架构具有两核或四核集群,允许英特尔提供具有更高每核二级缓存容量和更高每核性能的某些型号(通过双核模块更高的功率传输)。每个核心集群驻留在相同的时钟和电压域中。E-core集群共享4MB的L2缓存片和3MB的共享L3缓存。
与前几代一样,每个E-core都是单线程的。英特尔还将L1缓存增加了一倍,达到64KB,并采用了一个6宽解码引擎(双3宽解码引擎可以改善延迟和功耗)、5宽分配和8-wide retire。Sierra Glen内核不支持AMX或AVX-512,而是依赖于AVX10,但英特尔确实增加了对BF16, FP16, AVX-IFMA和AVX-DOT-PROD-INT8的支持。
英特尔Redwood Cove P核微架构 

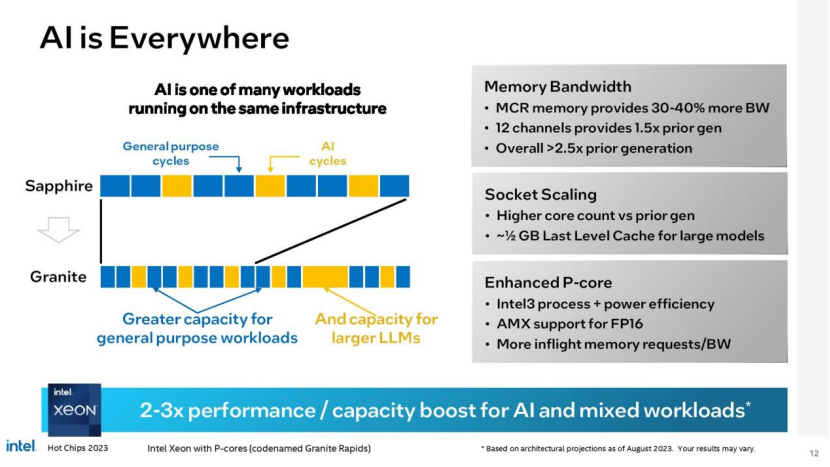


P核的Redwood Cove架构现在支持带有FP16加速的AMX,这是一个关键的补充,将提高AI推理工作负载的性能。英特尔还将L1指令缓存容量增加了一倍,达到64 KB,以更好地处理代码繁重的数据中心工作负载。Redwood Cove还采用了软件优化的预取和增强的分支预测引擎和错误恢复。英特尔还提高了浮点运算的性能,从4周期和5周期的FP操作提高到3周期,从而提高了IPC。
英特尔至强路线图 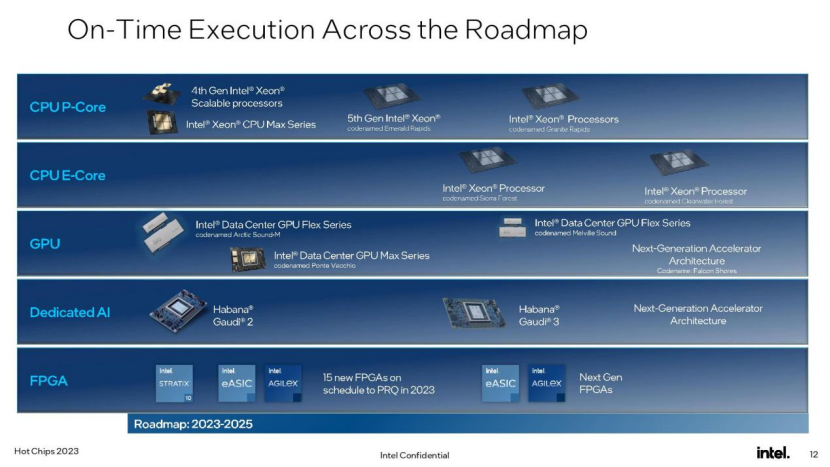
对于英特尔来说,好消息是,该公司的数据中心路线图仍在正轨上。Sierra Forest将于2024年上半年上市,Granite Rapids紧随其后。

在这里,我们可以看到英特尔的路线图与AMD的数据中心路线图的对比。目前,AMD去年推出的EPYC Genoa和英特尔今年年初推出的Sapphire Rapids之间的高性能之战正在激烈进行。英特尔将在今年第四季度推出Emerald Rapids新一代产品,该公司表示,这一代产品将配备更多内核和更快的时钟速率,并且已经发布了内置hbm的Xeon Max cpu。AMD最近发布了其5nm EPYC Genoa产品。明年,英特尔的下一代“Granite Rapids”将与AMD的“Turin”展开竞争。
在效率方面,AMD的Bergamo采用了与Sierra Forest非常相似的重核方法,利用了AMD密集的Zen 4c内核。Bergamo已经上市,而英特尔的Sierra Forrest要到2024年上半年才会上市。AMD的第五代EPYC Turin芯片将于2024年底前推出,但该公司尚未公布其第二代Zen 4c芯片。英特尔现在已经将其第二代e核驱动的Clearwater Forest列入了2025年的路线图。
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
