
高并发存储优化篇:诸多策略,缓存为王
本文内容概述
缓存是什么
1.1. 存储宕机的致命代价
1.2. 数据库性能为什么会下降
1.3. 缓存的类型一线研发最头疼的缓存问题
2.1. 缓存穿透
2.2. 缓存击穿
2.3. 缓存雪崩
2.4. 数据漂移
2.5. 缓存踩踏
2.6. 缓存污染
2.7. 热点key顶级缓存架构一览
3.1. 微博缓存架构演进
3.2. 知乎首页已读过滤缓存设计总结
Part1缓存是什么
1.1存储宕机的致命代价[1]
2015年5月28号,携程网站和APP全面瘫痪持续12小时,数据库被物理删除的消息在朋友圈风传。
按上季度财报估算,此次宕机直接影响携程营收大约1200w美元,携程股价也大跌11%。这还只是发生在互联网刚刚普及的2015年。如果发生在现在。。。据公司公告是由于员工操作失误导致。
虽然这不在我们想讨论的性能原因导致异常的范围内,但不妨碍我们得出结论,数据库宕机对一个系统的影响是灾难性的。
1.2结构化数据库性能为什么会下降
以Mysql为例,我们知道,为了调和CPU和磁盘的速度不匹配,MySQL 用buffer pool来加载磁盘数据到一段连续的内存中,供读写使用。一般情况下,如果缓冲池足够大,能够放下所有数据页,那mysql操作基本不会产生读IO,而写IO是异步的,不会影响读写操作。
Buffer pool 不够大,数据页不在里面该怎么办?
去磁盘中读取,将磁盘文件中的数据页加载到buffer pool中,那么就需要等待物理IO的同步读操作完成,如果此时IO没有及时响应,则会被堵塞。因为读写操作需要数据页在buffer中才能进行,所以必须等待操作系统完成IO,否则该线程无法继续后续的步骤。
热点数据,当新的会话线程也需要去访问相同的数据页怎么办?
会等待上面的线程将这个数据页读入到缓存中buffer pool。如果第一个请求该数据页的线程因为磁盘IO瓶颈,迟迟没有将物理数据页读入buffer pool, 这个时间区间拖得越长,则造成等待该数据块的用户线程就越多。对高并发的系统来说,将造成大量的等待。
高并发,大量请求的访问行为被阻塞,会造成什么后果?
对于服务来说,大量超时会使服务器处于不可用的状态。该台机器会触发熔断。熔断触发后,该机器的流量会打到其他机器,其他机器发生类似的情况的可能性会提高,极端情况会引起所有服务宕机,曲线掉底。
上面是由于磁盘IO导致服务异常的分析逻辑,也是我们生产中最常遇到的一种数据库性能异常的场景。除此之外,还有锁竞争缓存命中率等异常场景也会导致服务异常。
如果单库单表的极限存在,分库分表等优化策略也只能缓解,不会根除
为了避免上述情况,缓存的使用就非常有必要了。
1.3缓存的类型
缓存的存在,是为了调和差异。
差异有多种,比如处理器和存储之间的速度差异、用户对产品的使用体验和服务处理效率的差异等等。
1.3.1 客户端缓存
离用户最近的web页面缓存&app缓存。web页面因为技术成熟所以问题不是太多,但app因为设备的限制,在使用缓存时要多加注意。
之前经历的某个业务,因为客户端缓存出现问题,发生两次请求订单号串单,导致业务异常。串单呐,猜是因为缓存发生了混乱,至今比较奇怪会发生这种情况,需要对客户端相关加深认识了。
1.3.2 单机缓存
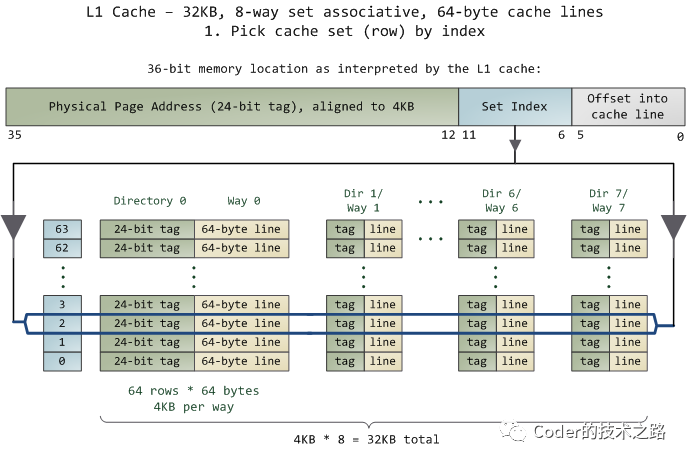
CPU缓存[2]。为了调和CPU和内存之间巨大的速度差异,设置了L1/L2/L3三级缓存,离CPU越近,速度越快。后面章节中介绍的知乎首页已读过滤的缓存架构,其灵感就是来源于此。
Ehcache[3]。是最流行了Java缓存框架之一。因为其开源属性,在spring/Hibernate等框架上被广泛使用。支持磁盘持久化和堆外内存。缓存功能齐全。
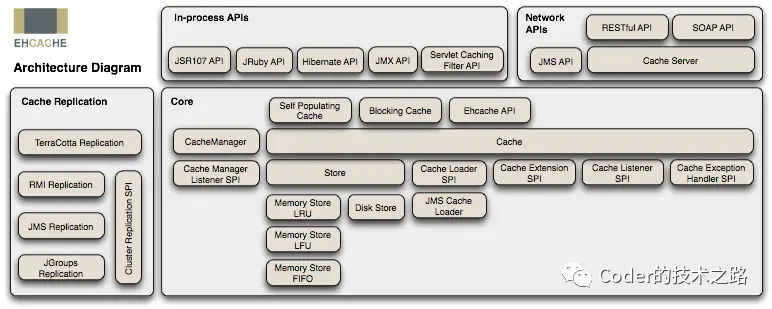
值得一说的是ehcache具备堆外缓存的能力,因为堆外缓存不受JVM限制,所以不会引发更多的GC停顿,对某些场景下的GC停顿调优有不小的意义。但是需要注意的是堆外内存需要用byte来操作,要实现序列化和反序列化,并且在速度上,也要比堆内存要慢不少,所以,如果不是GC停顿有较大问题,且对业务影响较大,没必要非用不可。
Guava cache。灵感来源于ConcurrentHashMap,但具有更丰富的元素失效策略,功能没有ehcache齐全,如只支持jvm内存,但比较轻量简洁。之前曾用guava cache来缓存网关的一些配置信息,定时过期自动加载的功能还比较方便。
1.3.3 数据库缓存
Query cache即将查询的结果缓存起来,开启后生效。其可以降低查询的执行时间,对需要消耗大量资源的查询效果明显。

1.3.4 分布式缓存
memcached。[5] memcached是一个高效的分布式内存cache,搭建与操作使用都比较简单,整个缓存都是基于内存的,因此响应时间很快,但是没有持久化的能力。
Redis。 Redis以优秀的性能和丰富的数据结构,以及稳定性和数据一致性的支持,被业内越来越普遍的使用。
在使用redis的都有谁?

看到了那个熟悉的公司--微博。微博算是redis的重度用户,相传redis的新特性好多都是为了微博定制的。有关微博的存储架构在后面章节另做详述。
本文后续的大部分内容也会基于Redis来叙述。
1.3.5 网络缓存
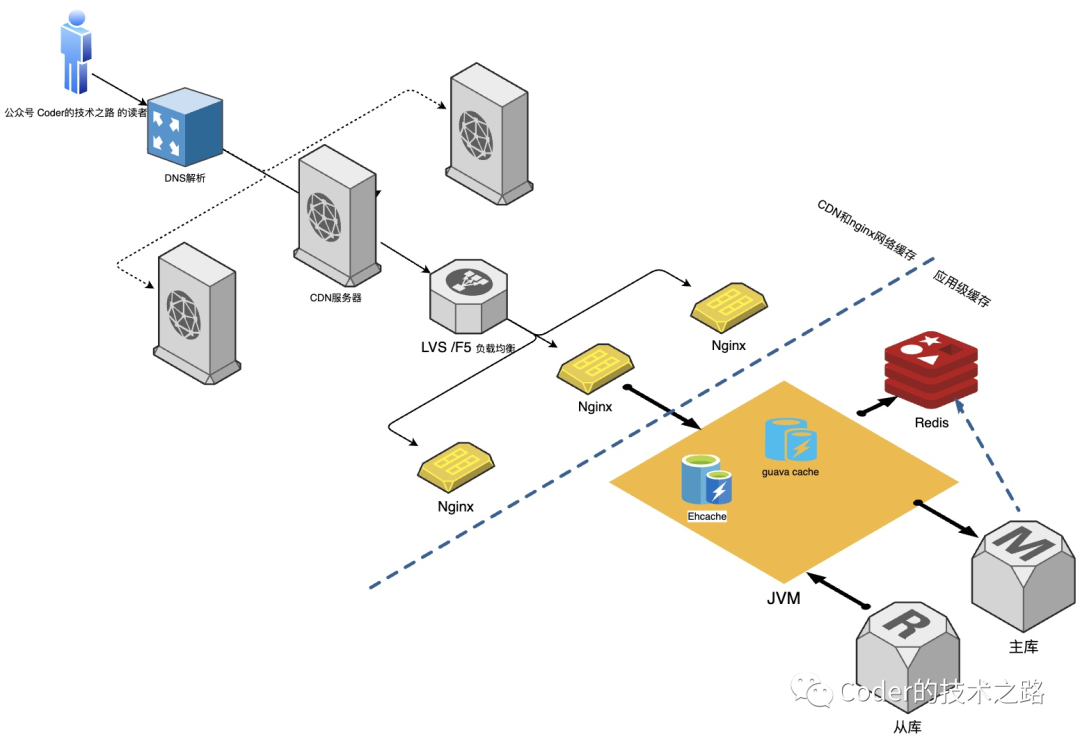
CDN服务器是建立在网络上的内容分发网络。布置在各地的边缘服务器,用户可以经过中央渠道的负载平衡、内容分发、调度等功用模块获取附近所需的内容,减少网络拥塞,提高响应速度和命中率。
Nginx基于Proxy Store实现,使用Nginx的http_proxy模块可以实现类似于squid的缓存功能。当启用缓存时,Nginx会将相应数据保存在磁盘缓存中,只要缓存数据尚未过期,就会使用缓存数据来响应客户端的请求。
Part2一线研发最头疼的缓存问题
下面这些问题其实大家在很多地方都应该见过了,不过为了内容的完整,还是罗列说明一下。
2.1缓存穿透
查询的是数据库中不存在的数据,没有命中缓存而数据库查询为空,也不会更新缓存。导致每次都查库,如果不加处理,遇到恶意攻击,会导致数据库承受巨大压力,直至崩溃。
解决方案有两种:一种是遇到查询为空的,就缓存一个空值到缓存,不至于每次都进数据库。二是布隆过滤器,提前判断是否是数据库中存在的数据,若不在则拦截。
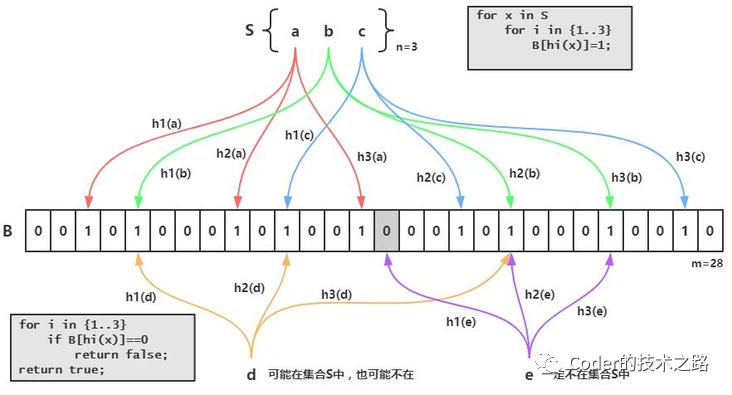
布隆过滤器利用多个hash函数标识数据是否存在,该方法让较小的空间容纳较多的数据,且冲突可控。其工作原则是,过滤器判断不存在的数据则一定不存在。
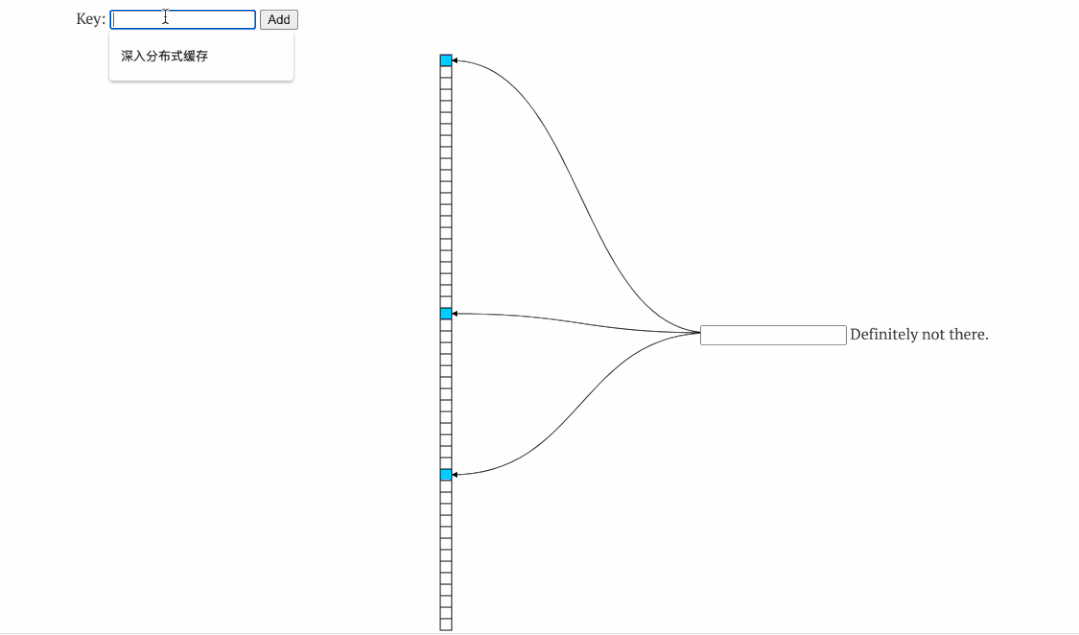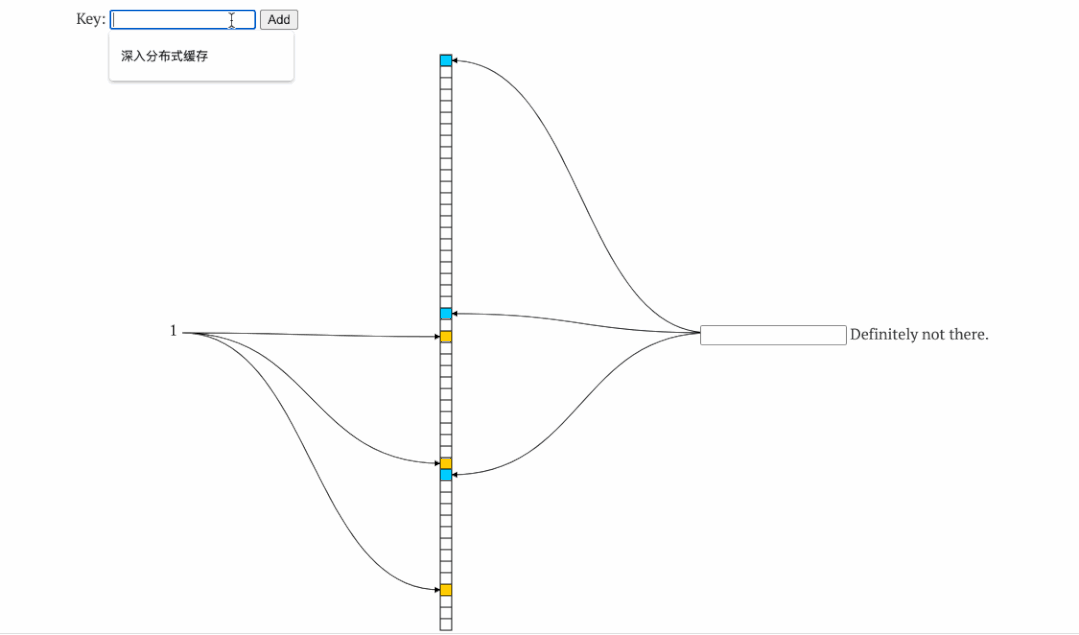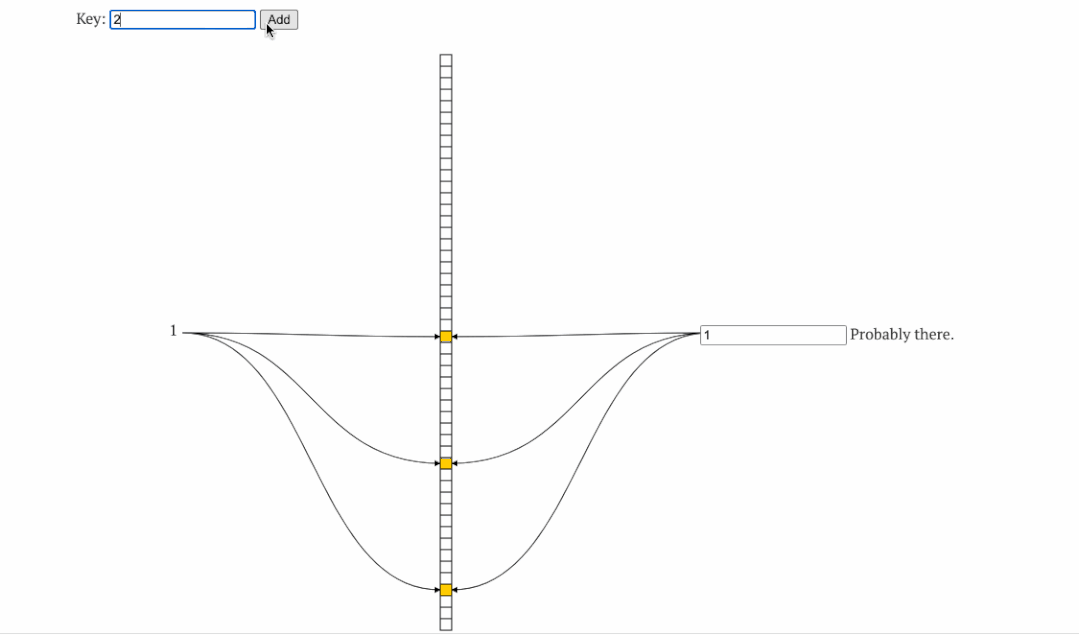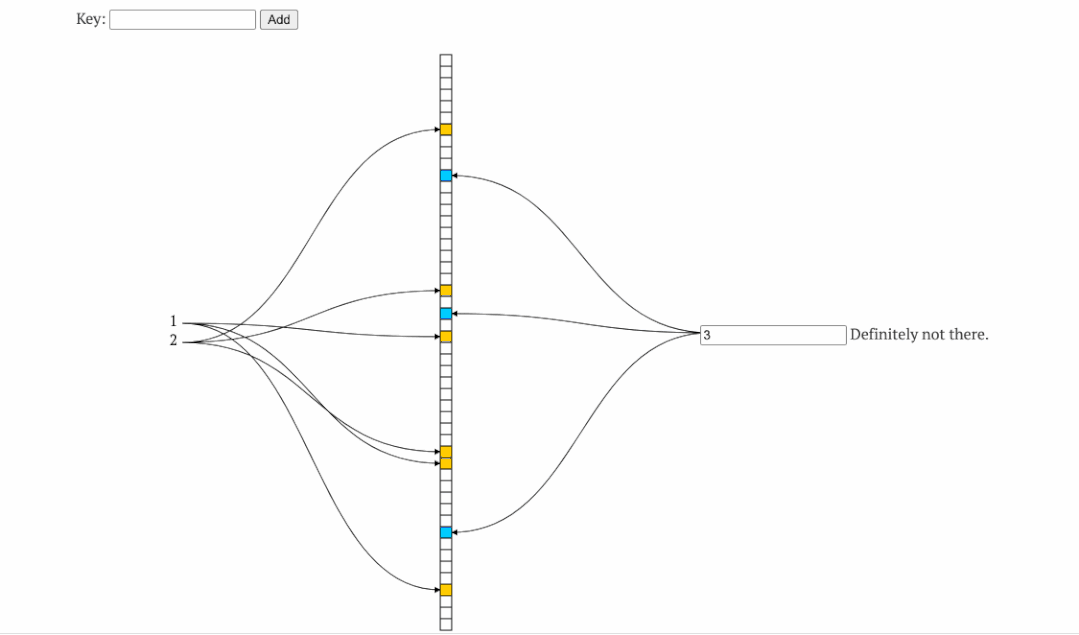
如上图,左侧为添加元素时的hash槽变化,右边为判断某数据是否存在时校验的hash槽,可以看到,添加了1、2 后hash槽位某些被占用,判断2 、3 是否存在时,校验对应hash槽即可。
2.2缓存击穿
从字面意思看,缓存起初时起作用的。发生的场景是某些热点key的缓存失效导致大量热点请求打到数据库,导致数据库压力陡增,甚至宕机。
解决方案有两种:
一种是热点key不过期。有的同学在这里提出了逻辑过期的方案,即物理上不设置过期时间,将期望的过期时间存在value中,在查询到value时,通过异步线程进行缓存重建。
第二种是从执行逻辑上进行限制,比如,起一个单一线程的线程池让热点key排队访问底层存储,以损失系统吞吐量的代价来维护系统稳定。
2.3缓存雪崩
鉴于缓存的作用,一般在数据存入时,会设置一个失效时间,如果插入操作是和用户操作同步进行,则该问题出现的可能性不大,因为用户的操作天然就是散列均匀的。
而另一些例如缓存预热的情况,依赖离线任务,定时批量的进行数据更新或存储,过期时间问题则要特别关注。
因为离线任务会在短时间内将大批数据操作完成,如果过期时间设置的一样,会在同一时间过期失效,后果则是上游请求会在同一时间将大量失效请求打到下游数据库,从而造成底层存储压力。同样的情况还发生在缓存宕机的时候。
解决方案:
一是考虑热点数据不过期获取用上一节提到的逻辑过期。
二是让过期时间离散化,如,在固定的过期时间上额外增加一个随机数,这样会让缓存失效的时间分散在不同时间点,底层存储不至于瞬间飙升。
三是用集群主从的方式,保障缓存服务的高可用。防止全面崩溃。当然也要有相应的熔断和限流机制来应对可能的缓存宕机。
2.4数据漂移
数据漂移多发生在分布式缓存使用一致性hash集群模式下,当某一节点宕机,原本路由在此节点的数据,将被映射到下一个节点。
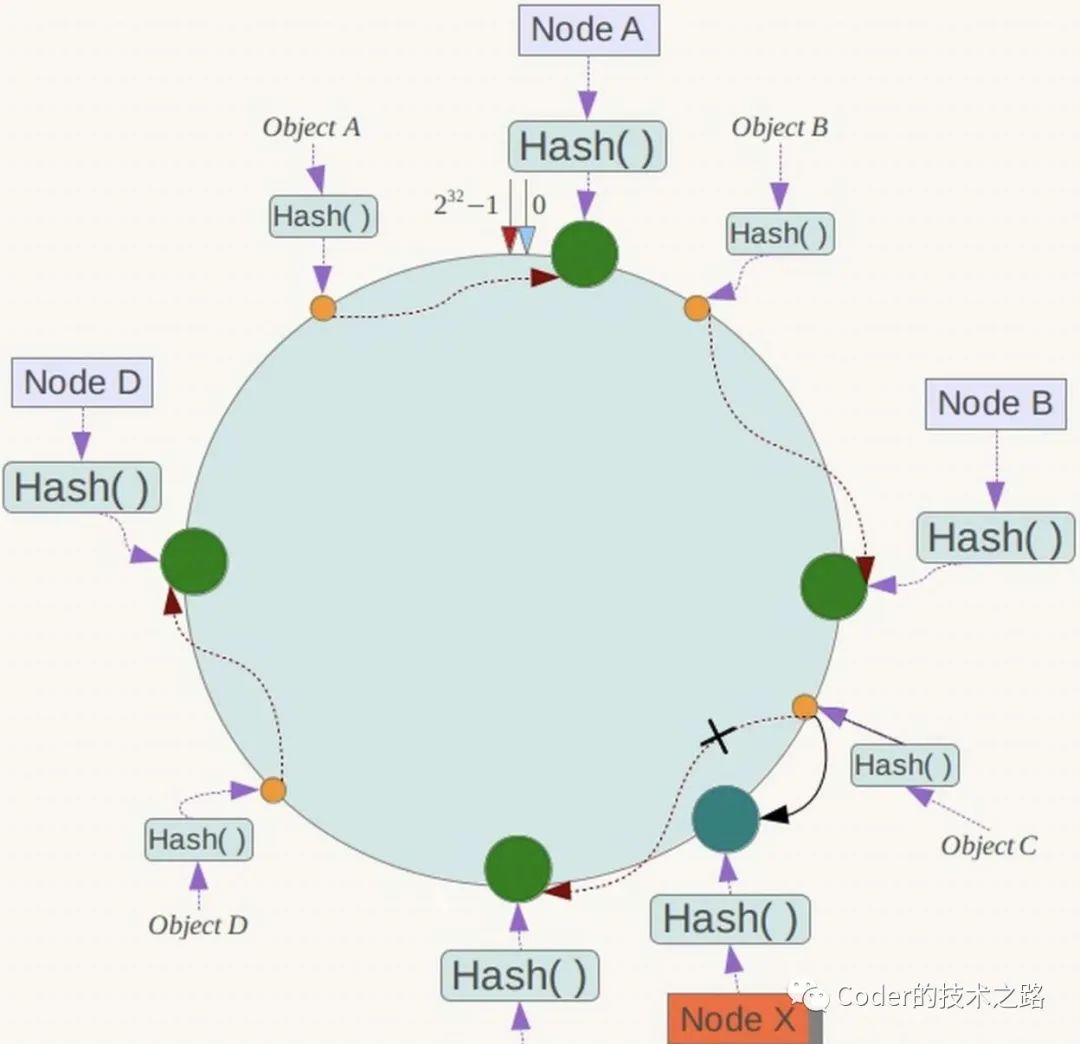
但是,当宕机的节点恢复之后,刚才原本从新hash到下一个节点的数据,就全部失效,因为hash路由已经恢复到了此节点上,所以,下一个节点的数据变成冗余数据,且,请求当前节点发现数据不存在,则会增加底层存储调用。
这个问题,是我们使用一致性hash来保证缓存集群机器宕机时不会造成缓存大量失效方案带来的一些附加问题。因此需要保证一致性hash尽量的均匀(一致性hash虚拟节点的运用),防止数据倾斜的节点的宕机和恢复对其他节点造成冲击。
2.5缓存踩踏[6]
缓存踩踏其实只是一种缓存失效场景的提法,底层原因是缓存为空或还未生效。关键是因为上游调用超时后唤起重试,引发恶性循环。
比如,当某一名人新发布了图片,而他们粉丝都会收到通知,大量的粉丝争先抢后的想去看发布了什么,但是,因为是新发布的图片,服务端还没有进行缓存,就会发生大量请求被打到底层存储,超过服务处理能力导致超时后,粉丝又会不停的刷新,造成恶性循环。
解决方案:锁 和 Promise。
发生这种踩踏的底层原因是对缓存这类公共资源拼抢,那么,就把公共资源加锁,消除并发拼抢。
但是,加锁在解决公共资源拼抢的同时,引发了另一个问题,即没有抢占到锁的线程会阻塞等待唤醒,当锁被释放时,所有线程被一同唤醒,大量线程的阻塞和唤醒是对服务器资源极大的消耗和浪费,即惊群效应。
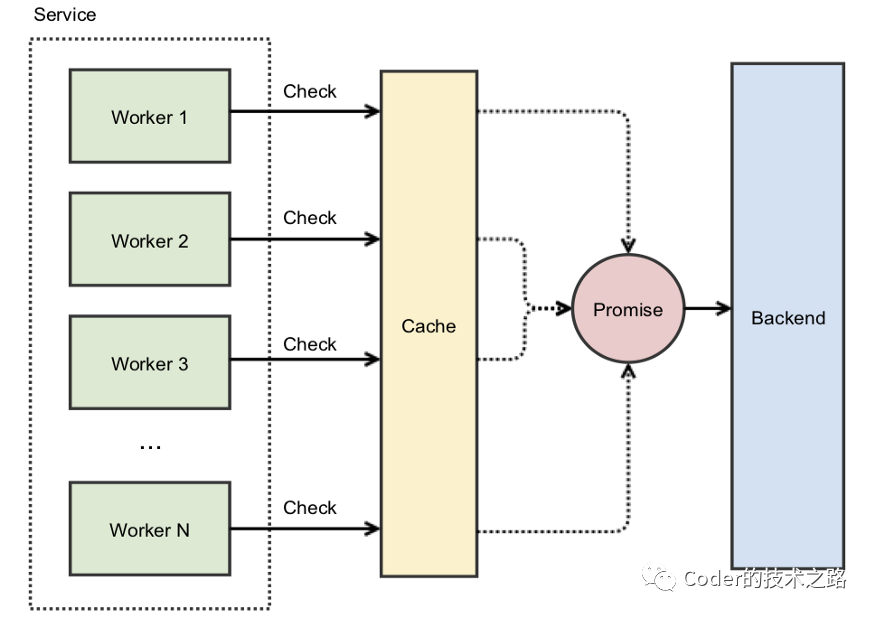
promise的原理其实是一种代理模式,实际的缓存值被promise代替,所有的线程获取promise 并等待promise返回给他们结果 , 而promise负责去底层存储获取数据,通过异步通知方式,最终将结果返回给各工作线程。
这样,就不会发生大量并发请求同时操作底层存储的情况。
2.6缓存污染
缓存污染的主要表现是,正常的缓存数据总是被其他非主线操作影响,导致被替换失效。
解决缓存污染的基本出发点,是要拆解不同消费速度的任务(实时消费/定时消费)、或不同的数据生产来源(主流程/follower),分而治之的思路避免相互间缓存的影响。
2.7热点key
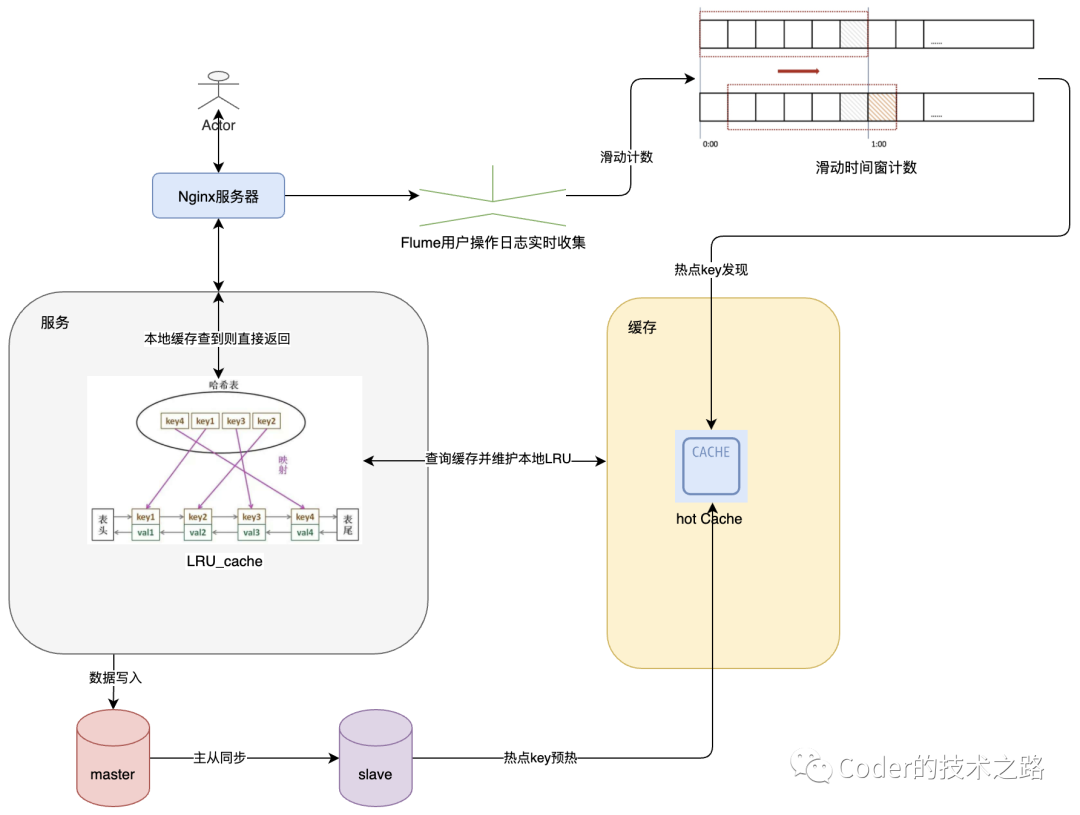
热点key的影响不再叙述,而解决热点key的方法,主要在热点key的发现和应对上:
可以通过监控nginx日志对用户请求进行时间窗计数、建立多级缓存、服务器本地利用LRU缓存热点key、根据业务预估热点key提前预热等等;
可以通过分散存储来降低单个缓存节点应对热点的压力。
Part3顶级缓存架构一览
3.1微博缓存架构演进
微博有100T+存储,1000+台物理机,10000+Redis实例,那他的缓存方案是怎么演变发展到可以抗N个明星同时离婚的呢?
缓存的架构演进[7]
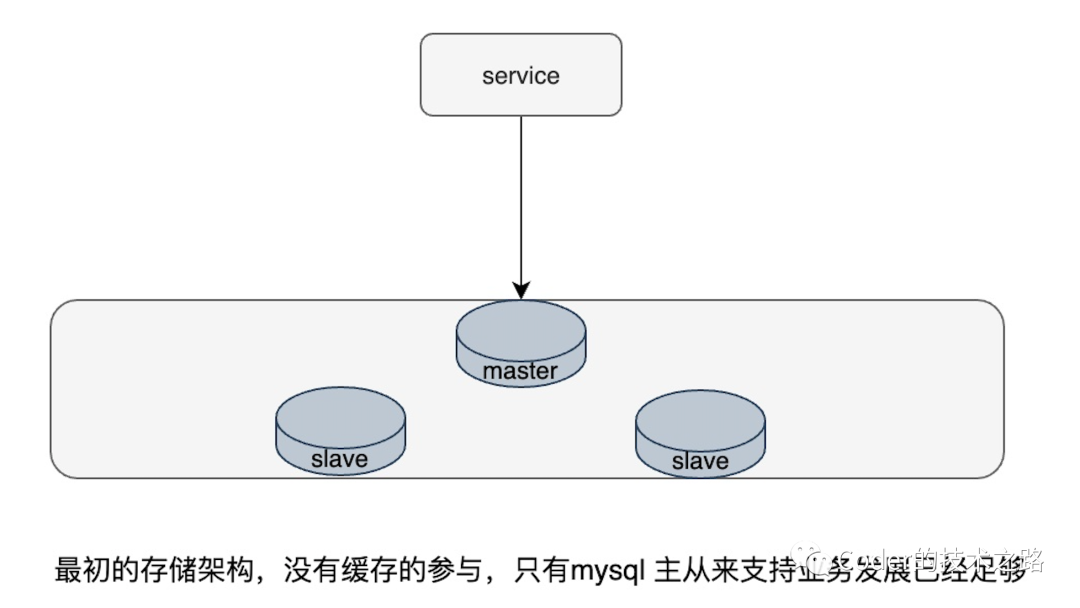
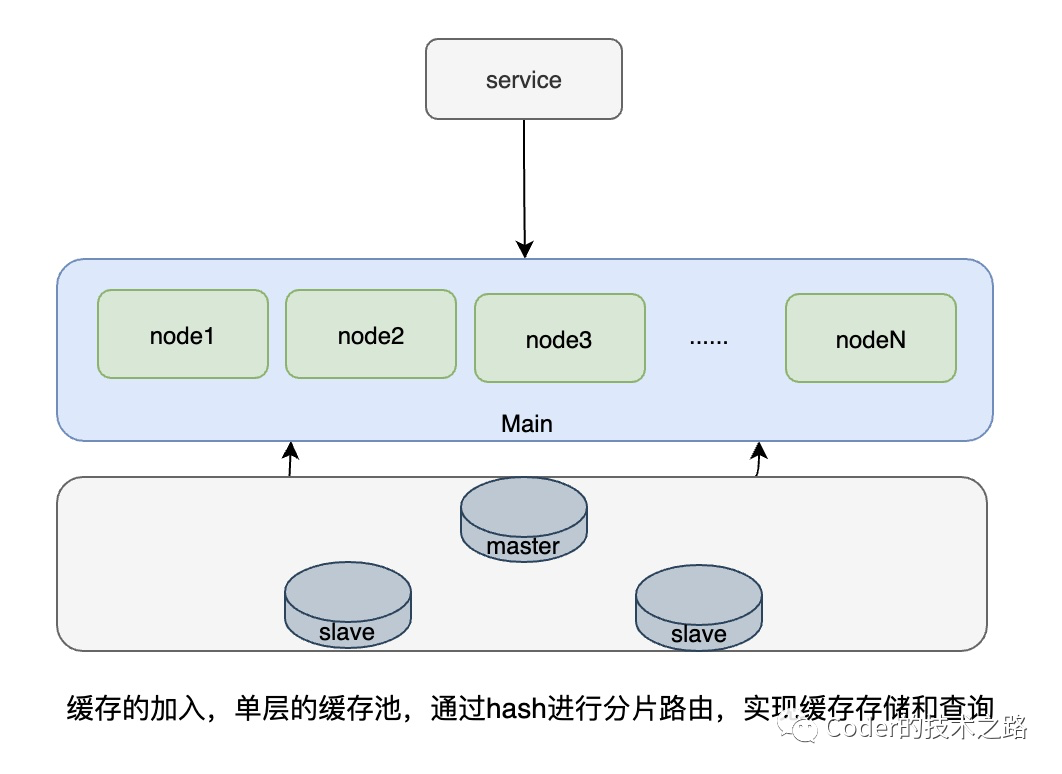
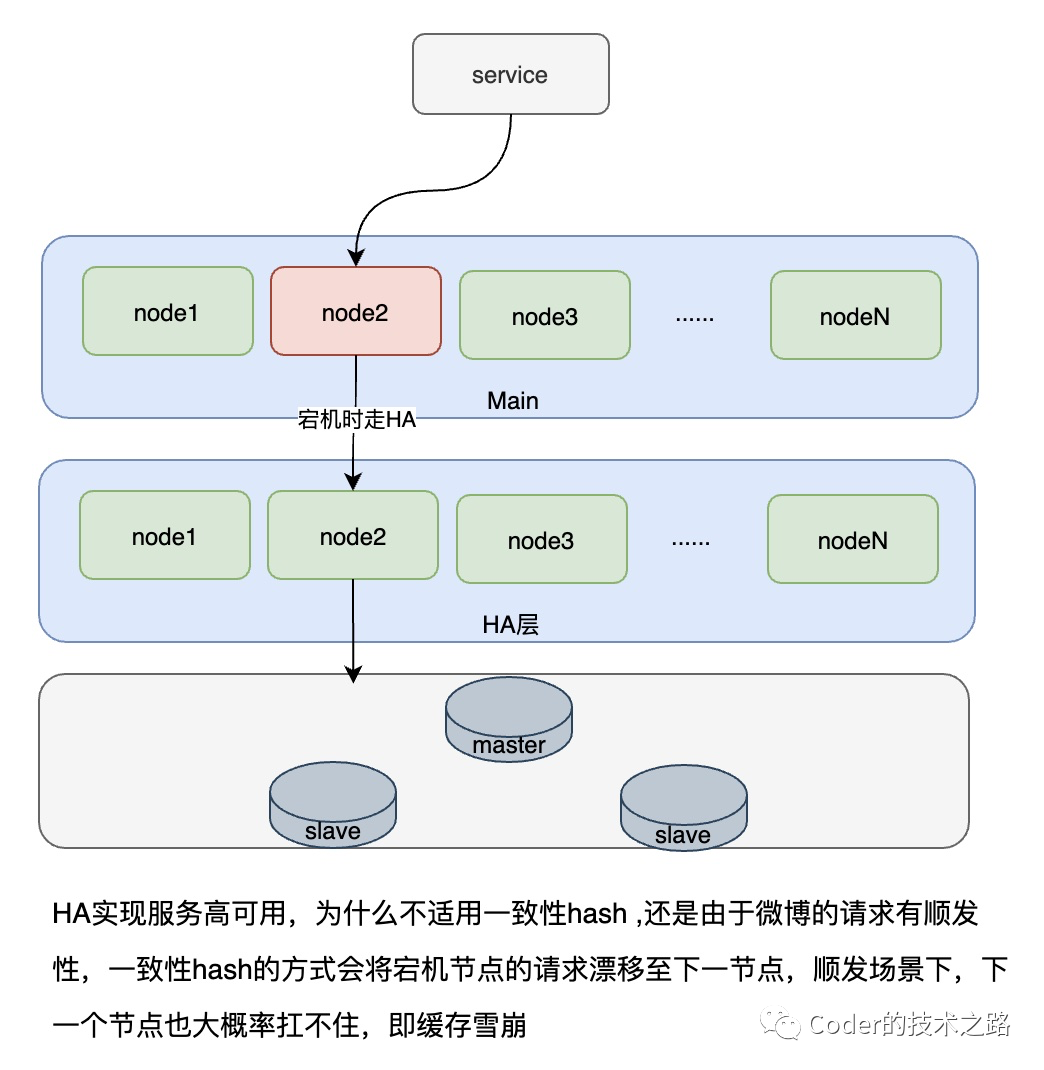
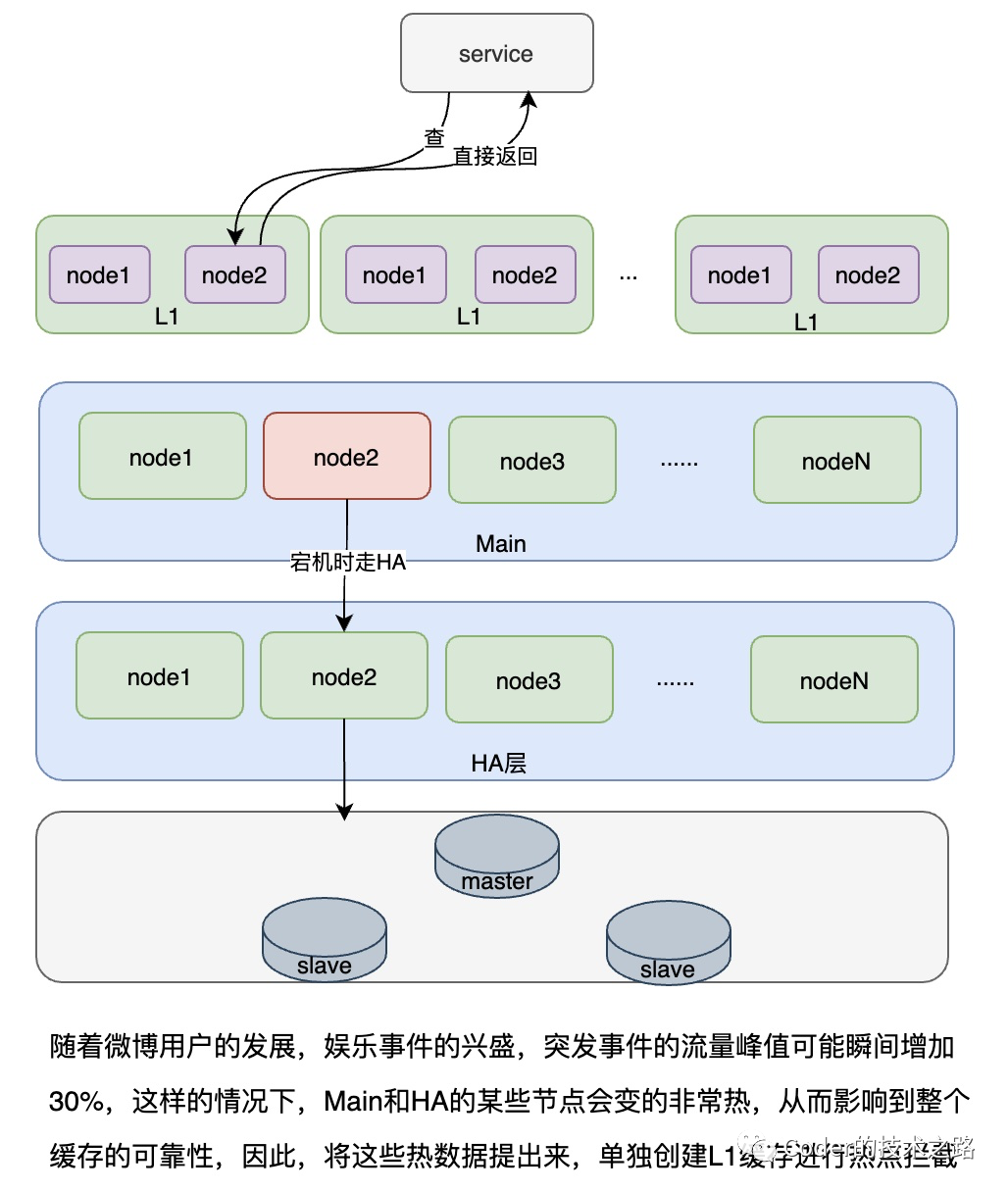
<<< 左右滑动见更多 >>>
从上面的几张缓存演进的架构图中可以看到,微博的缓存架构其实大部分都是在应对热点数据,比如,用HA层而不用一致性hash,是因为微博有典型的跟随者踩踏效应,一致性hash在踩踏效应下某节点的宕机,会引发下游一系列节点的异常。在比如L1缓存的引入,则是因为微博的流量在时间上存在一些衰减规律,越新的一段越热,所以,用小的热点分片来挡住发生的少但流量大的情况。
只是上面这些还不够,一些系统化的问题不容忽视:
某组资源请求量过大导致需要过多的节点 Cache 的伸缩容和节点的替换动静太大 过多资源带来的运维问题 Cache的易用性问题
CacheService缓存服务[8]
为了解决上述问题资源微博对缓存进行了服务化,提供一个分布式的 CacheService 架构,简化业务开发方的使用,实现系统的动态伸缩容、容灾、多层 Cache 等相关功能。
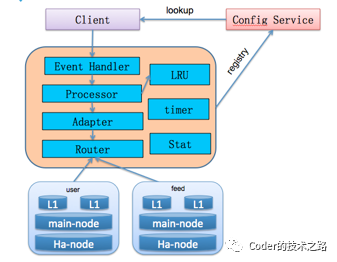
可以看到,在cache池上层,被封装了一层proxy逻辑,包括异步事件处理器用来管理数据连接、接收数据请求,processer用来进行数据解析,Adapter用来适配底层存储协议,Router用来路由请求到对应的资源分片,LRU_cache用来优化性能、缓解proxy性能损耗,Timer用来进行健康状态探测。
某次机缘巧合和微博架构组的总监简单聊了几句了解到,现在的整个cacheService服务的易用性已经非常高,服务器节点的弹性伸缩依赖检测体系全部自动进行,极大的减少了运维和维护成本,可能微博同学们曾经哪些加班吃瓜的欢乐日子已经一去不复返了。
Redis在微博的极致运用[9][10]
从2010年引入redis,至今已有十多个年头。有非常多的使用经验和定制化需求,不然也不会被redis官网列在使用者名单前三的位置。
$ 单线程下bgsave重操作卡顿问题
bgsave因为是非常重的操作,发生时会出现明显的卡顿,造成业务波动;在故障宕机后恢复时主从速度慢,经常出现带宽洪峰
从主线程中独立出来Bio thread,专门执行Bgsave等操作,避免干扰; 在Redis中内置Cronsave功能,控制备份时间; 放弃bgaofrewrite。
$ redis完全替代mysql实现存储落地
在Redis替代MySQL存储落地的过程中,微博对Redis也进行很多定制化改造:
修改了AOF机制,增加原本不存在的POS位; 修改了Replication机制,实现基于AOF+POS位置的数据同步 修改落地机制,改为RDB+AOF滚动机制,保障数据持久化存储。
$ longset定制化数据结构
针对千亿级别的关系类存储,为了减少成本,放弃了原生的Hash结构(比较占内存),内存降为原来的1/10。
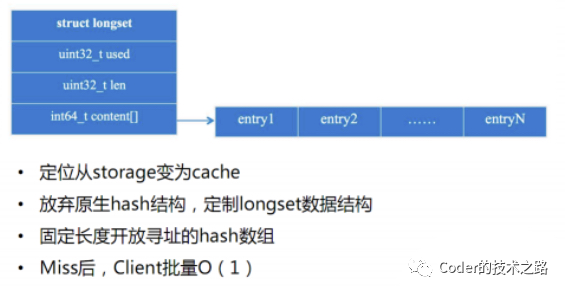
$ 计数功能优化
为了方便计数,将redis的KV改成了定长的KV ,通过预先分配内存,知道了总数,会极大的降低计数的操作开销。
10年的深度依赖,微博在redis的使用上积累了大量的经验和技巧,值得我们学习参考。
3.2知乎首页已读过滤缓存设计[11]
知乎社区拥有2.2亿用户、38万的话题量、2800万问题、1.3亿回答,而个性化的首页,需要过滤已读并长期存储以展示丰富的内容,对系统的性能和稳定性有着极高的要求。
$ 早期方案
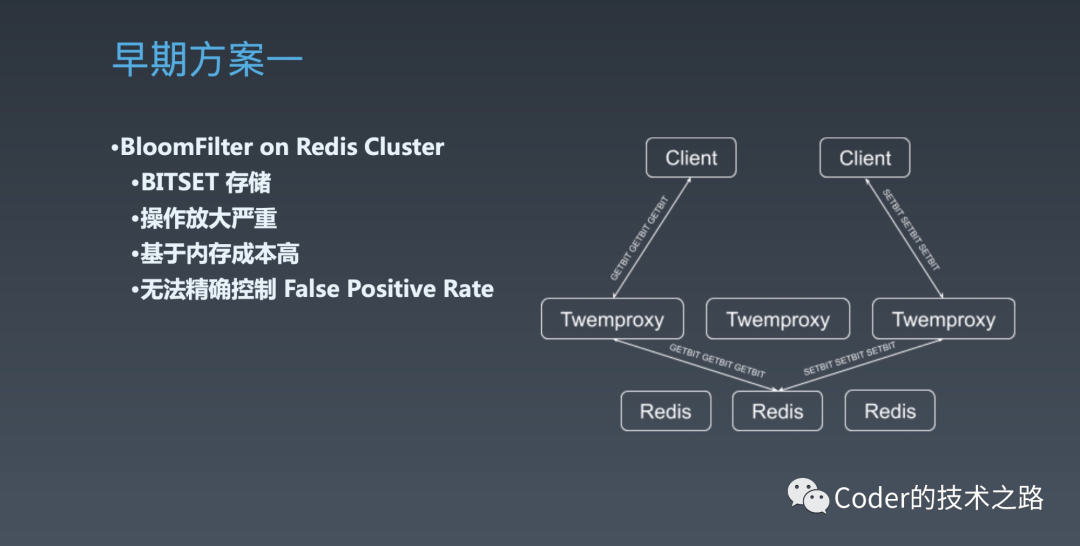
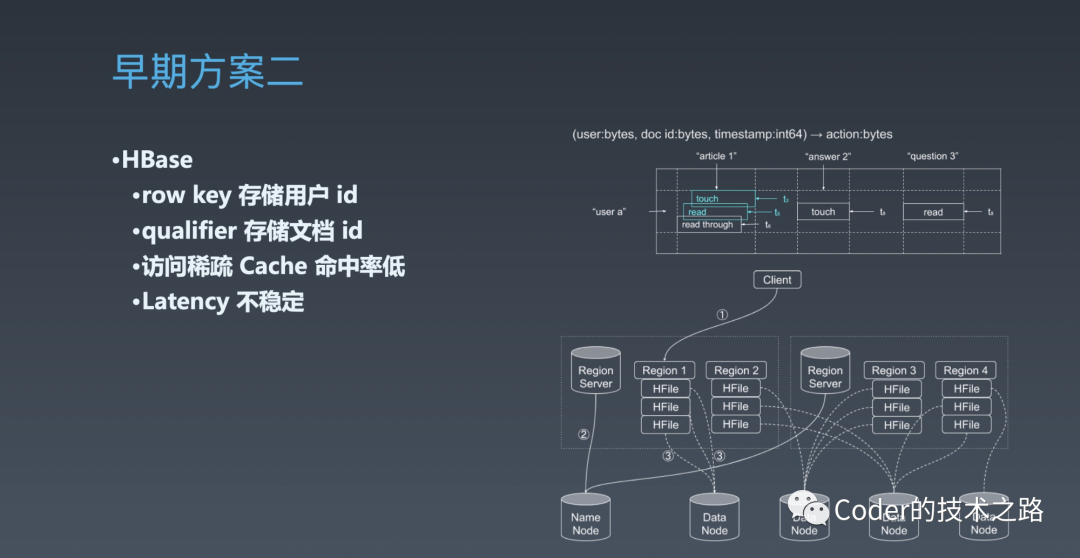
<<< 左右滑动见更多 >>>
$ 优化方案
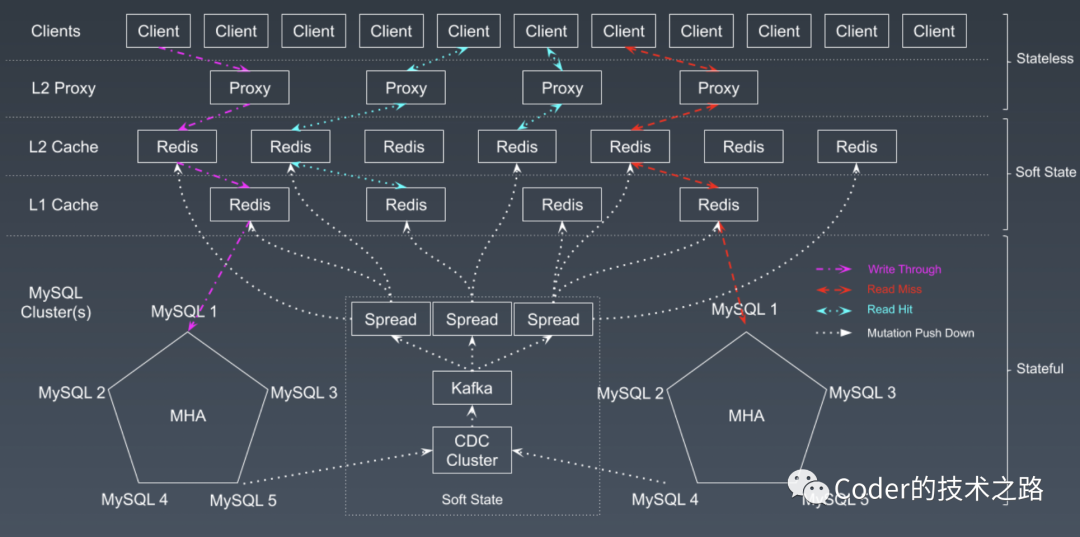
大家有没有发现这个架构思路很熟,是的,就是CPU的多级缓存架构。通过缓存拦截、副本扩展、压缩降压的方式,其实基本都是对前面章节叙述的缓存问题的整体应对,以达到低延迟且稳定的缓存服务效果。
Part4总结
本篇文章,通过底层存储的极限理论,论证了缓存存在的必要性;对缓存场景的一些典型问题做了分析了阐述,最后,用微博和知乎两个顶级的缓存架构实例,对上面的内容进行了呼应。原创不易,如有感觉有所帮助,欢迎读者朋友的帮助转发分享,毕竟,汇仁牌肾宝,大家好才是真的好~
参考资料
环球旅讯: https://www.traveldaily.cn/article/92559
[2]cpu缓存: https://manybutfinite.com/post/intel-cpu-caches/
[3]ehcache官网: https://www.ehcache.org/
[4]深入分布式缓存: 机械工业出版社
[5]memcached官网: https://memcached.org/
[6]Facebook 史上最严重的宕机事件分析: https://www.infoq.cn/article/Bb2YC0yHVSz4qVwdgZmO
[7]百亿级日访问量的应用如何做缓存架构设计: https://my.oschina.net/JKOPERA/blog/1921089
[8]微博 CacheService 架构浅析: https://www.infoq.cn/article/weibo-cacheservice-architecture
[9]万亿级日访问量下Redis在微博的9年优化历程: https://cloud.tencent.com/developer/news/462944
[10]微博Redis定制化之路: https://developer.aliyun.com/article/62598
[11]知乎首页已读数据万亿规模下的查询系统架构设计: Qcon大会分享