
高并发存储优化篇:诸多策略,缓存为王

Part1缓存是什么
1.1存储宕机的致命代价[1]
1.2结构化数据库性能为什么会下降
1.3缓存的类型
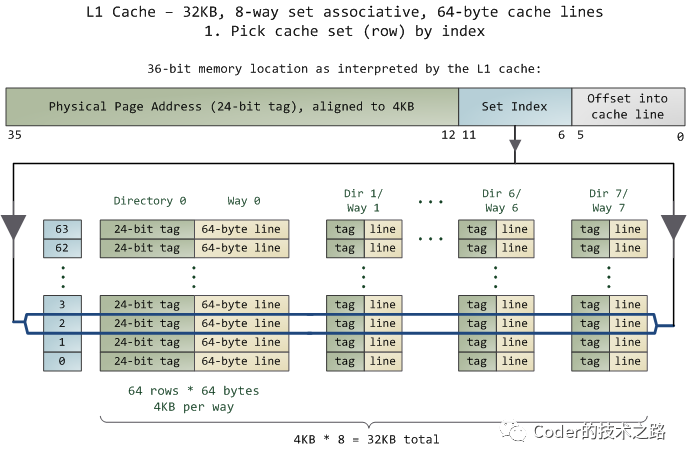
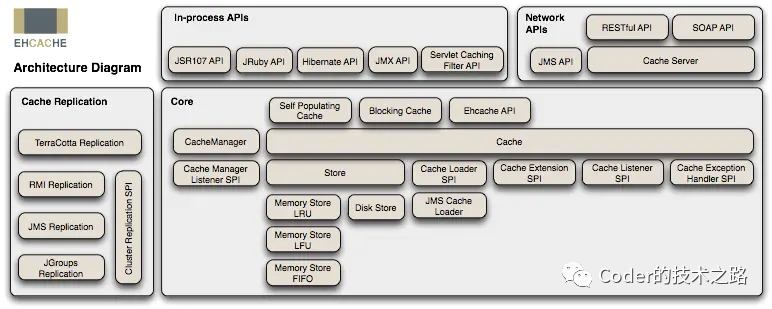

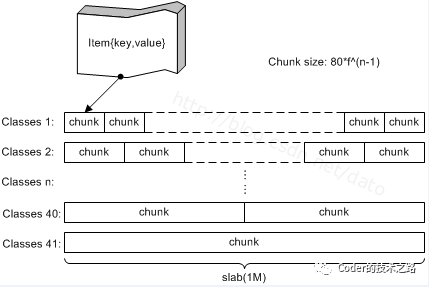
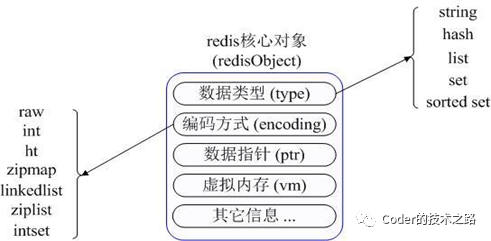

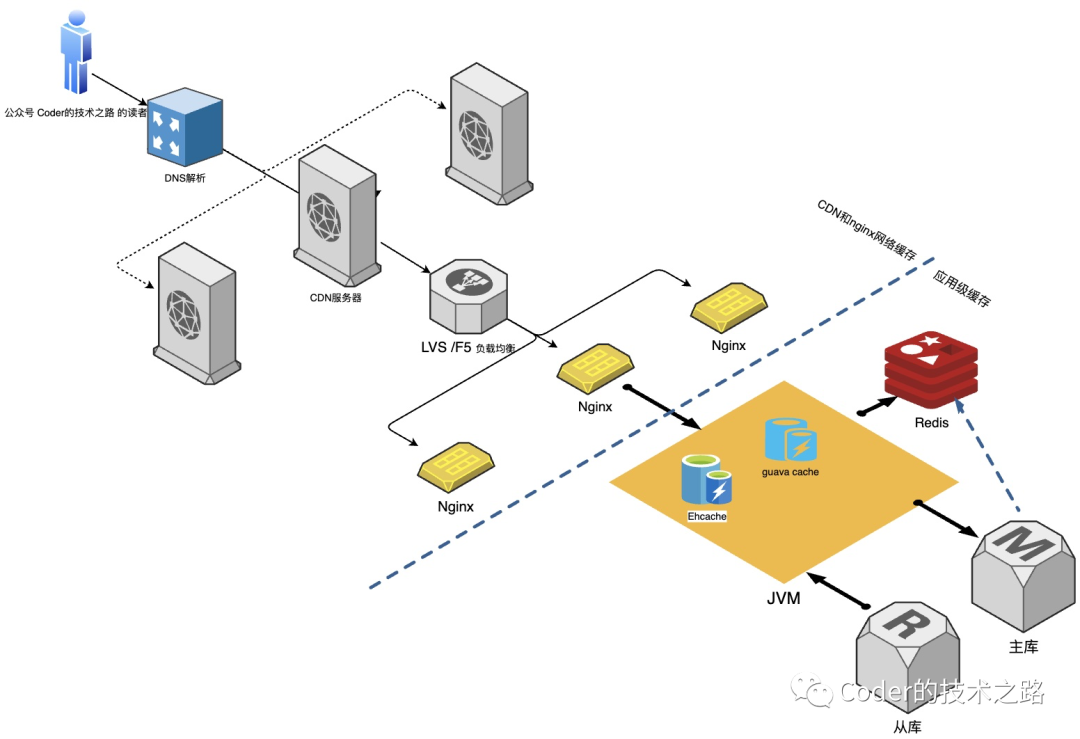
Part2一线研发最头疼的缓存问题
2.1缓存穿透
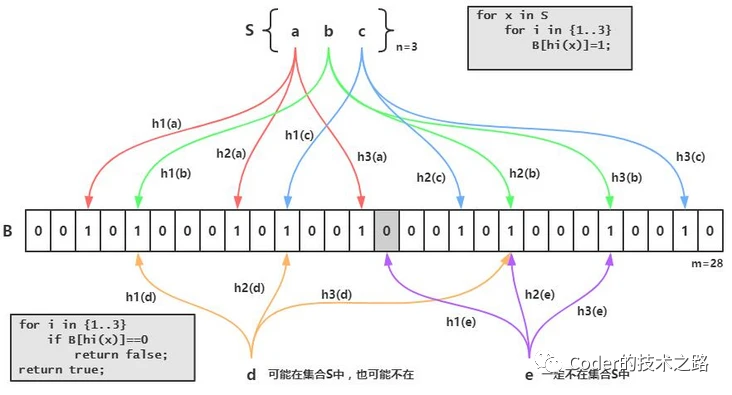
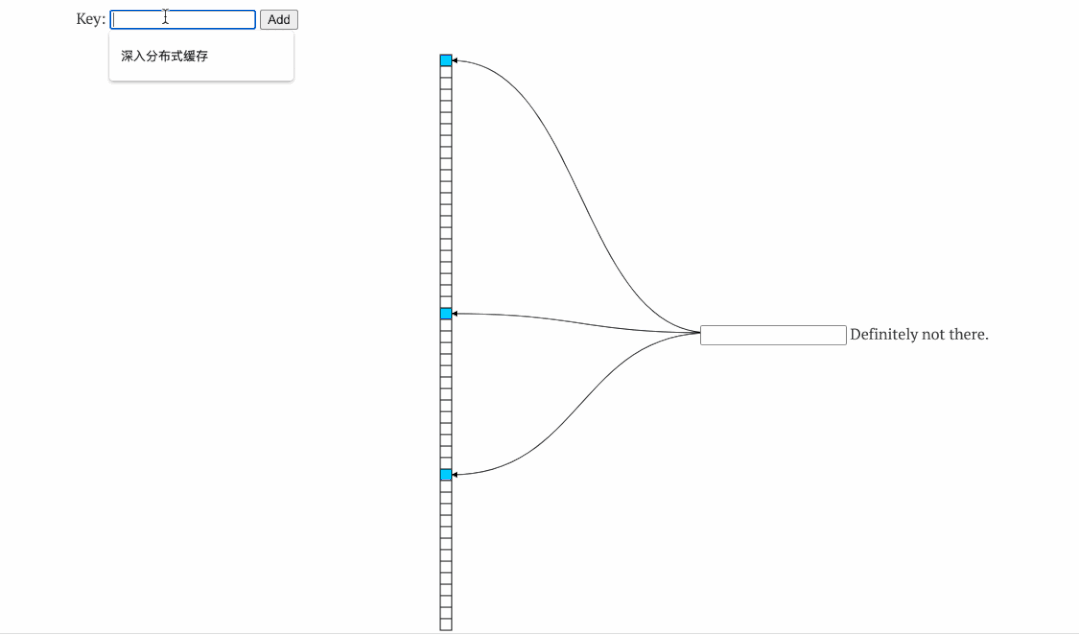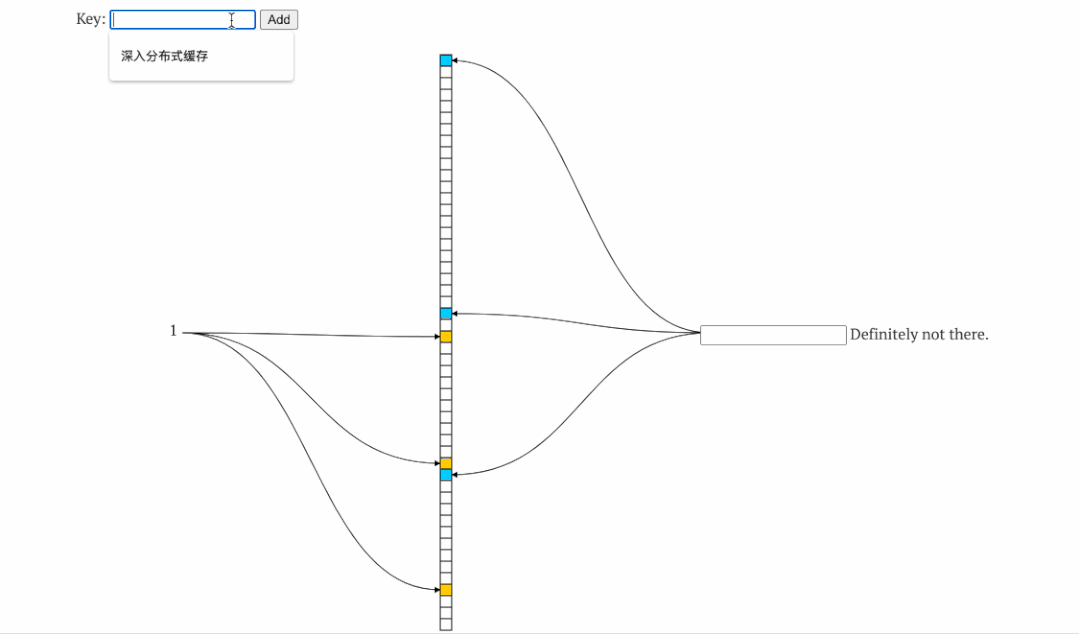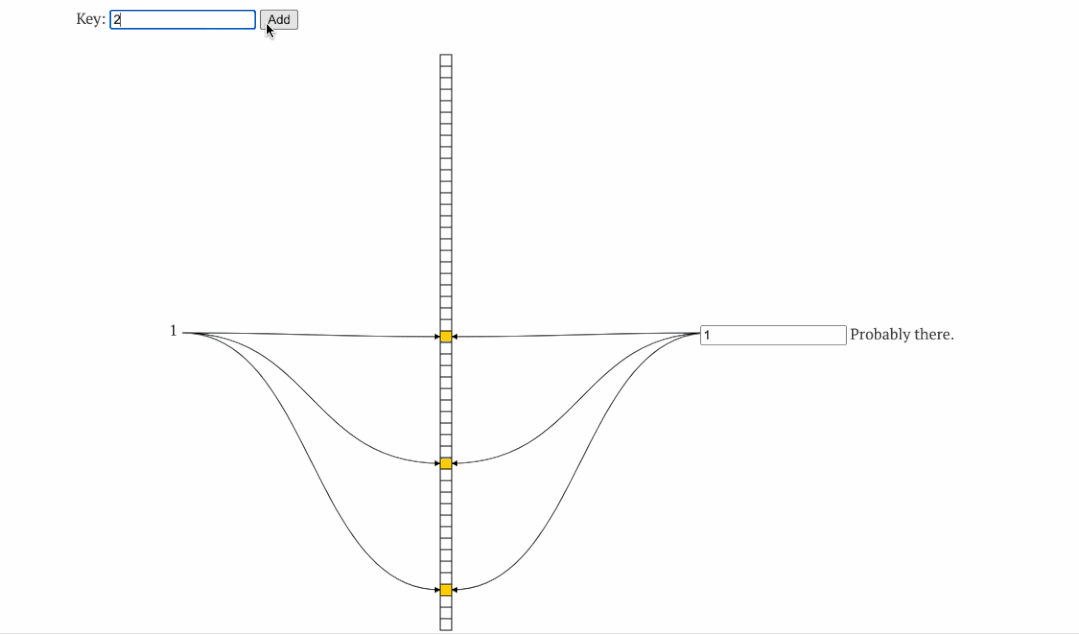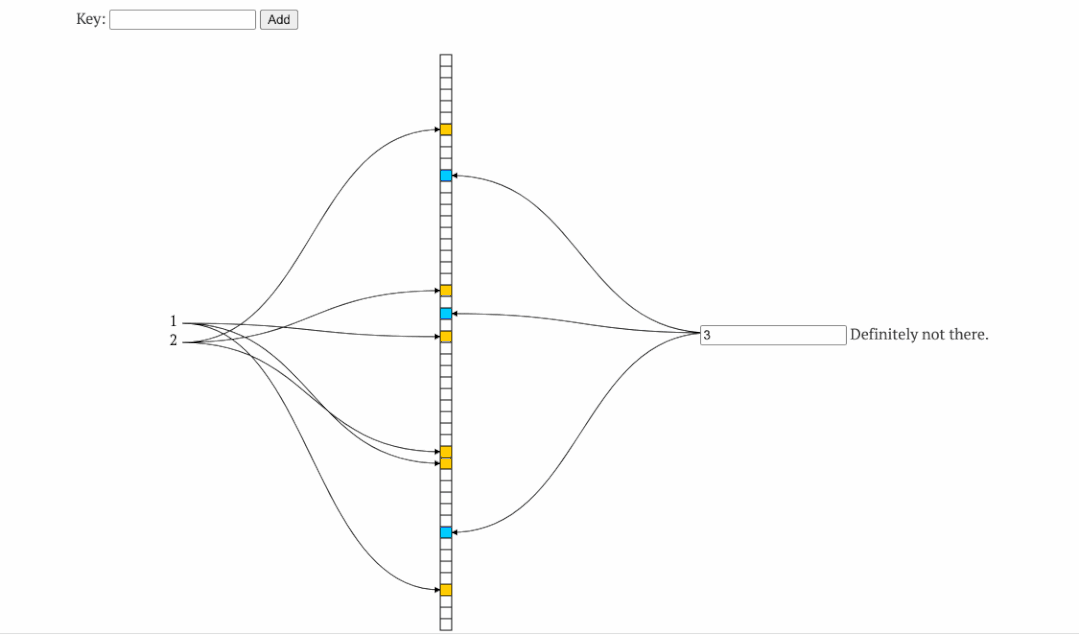
2.2缓存击穿
2.3缓存雪崩
2.4数据漂移
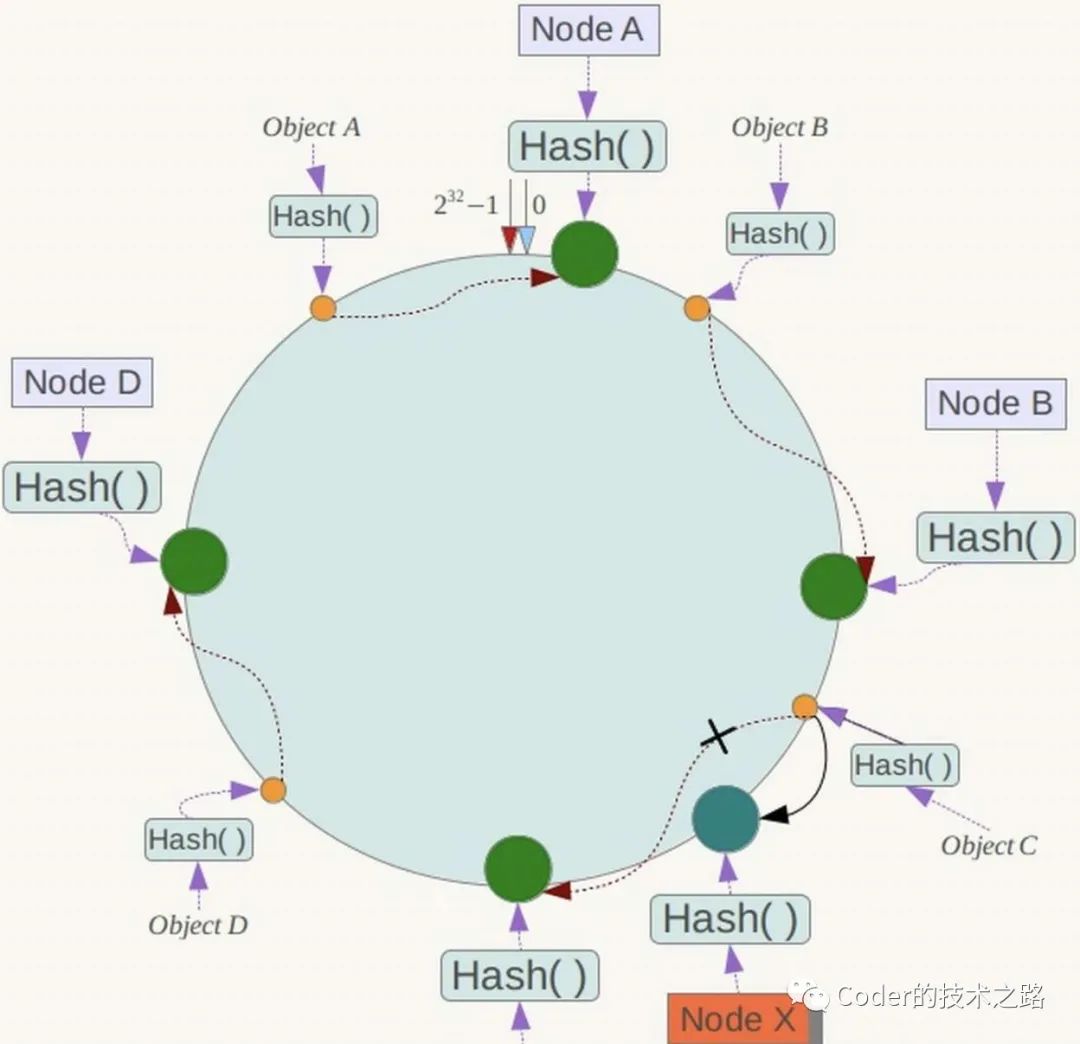
2.5缓存踩踏[6]
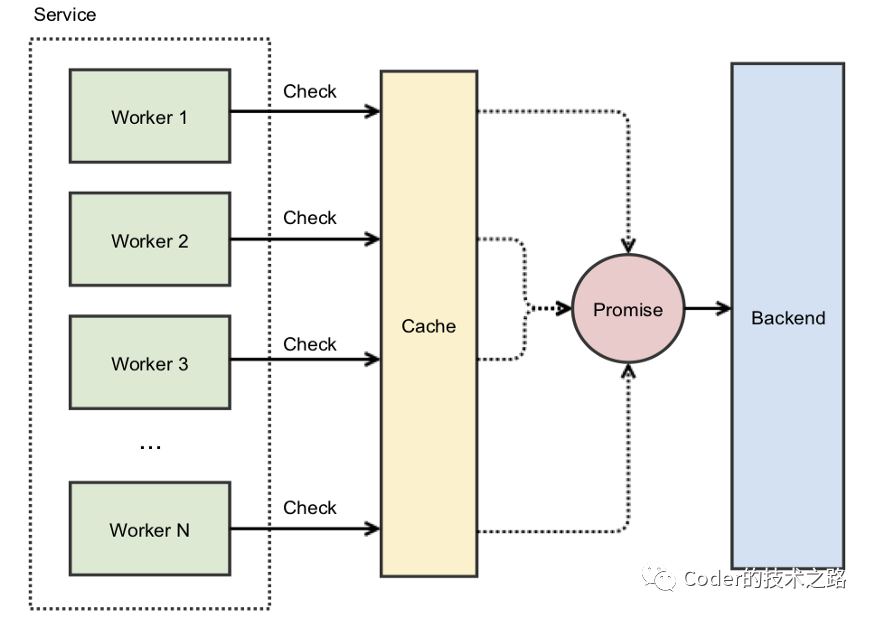
2.6缓存污染
2.7热点key
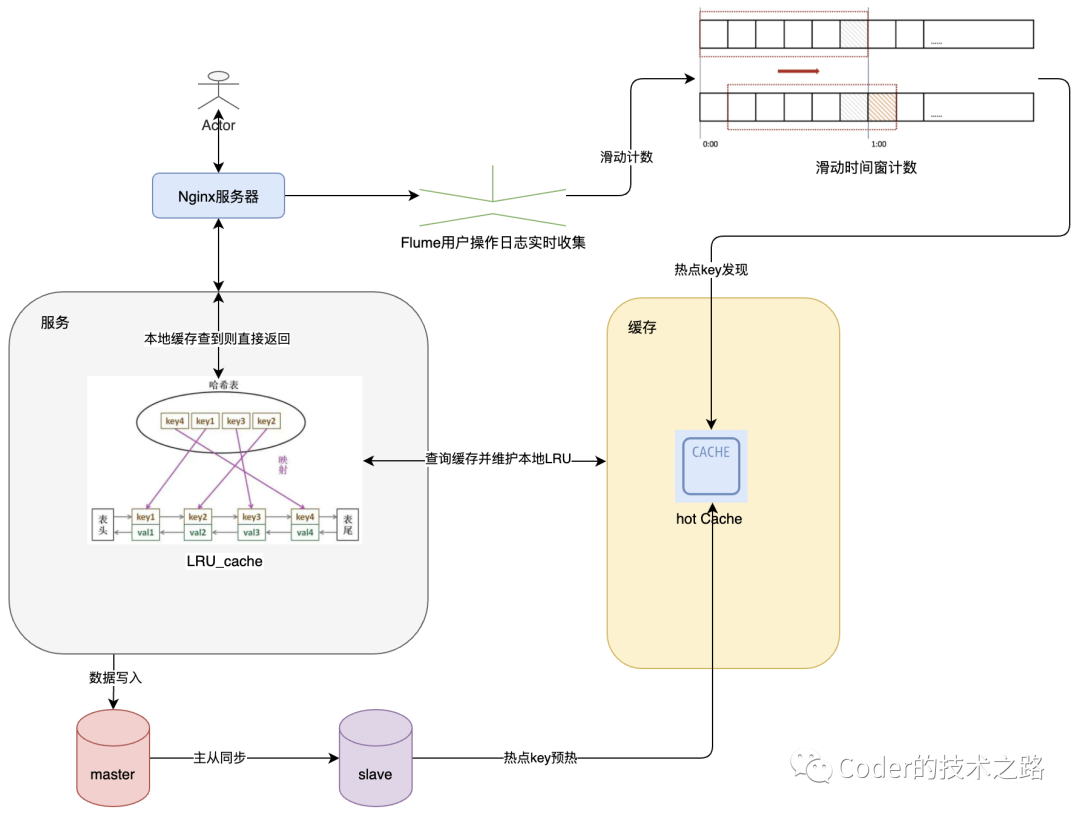
Part3顶级缓存架构一览
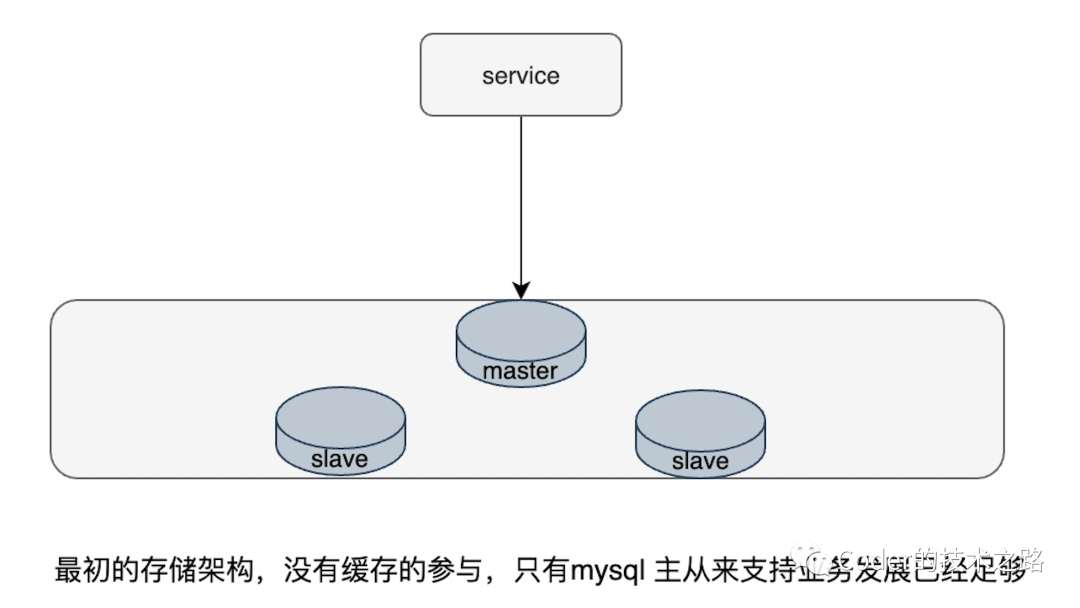
3.1微博缓存架构演进
缓存的架构演进[7]
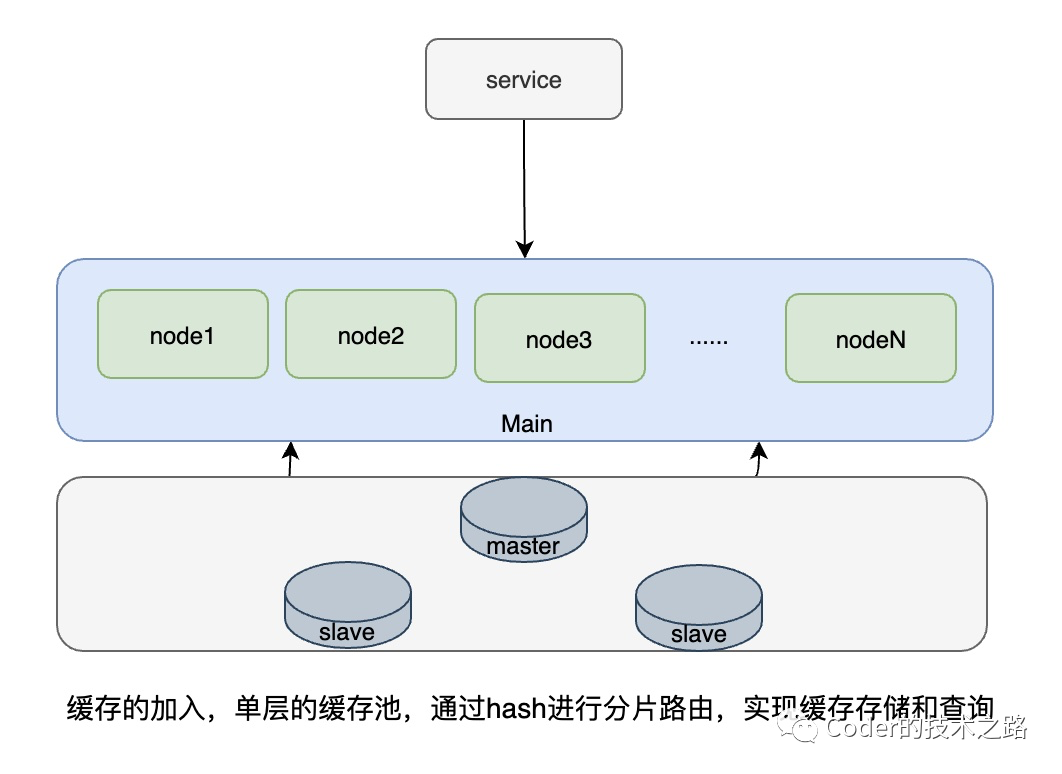
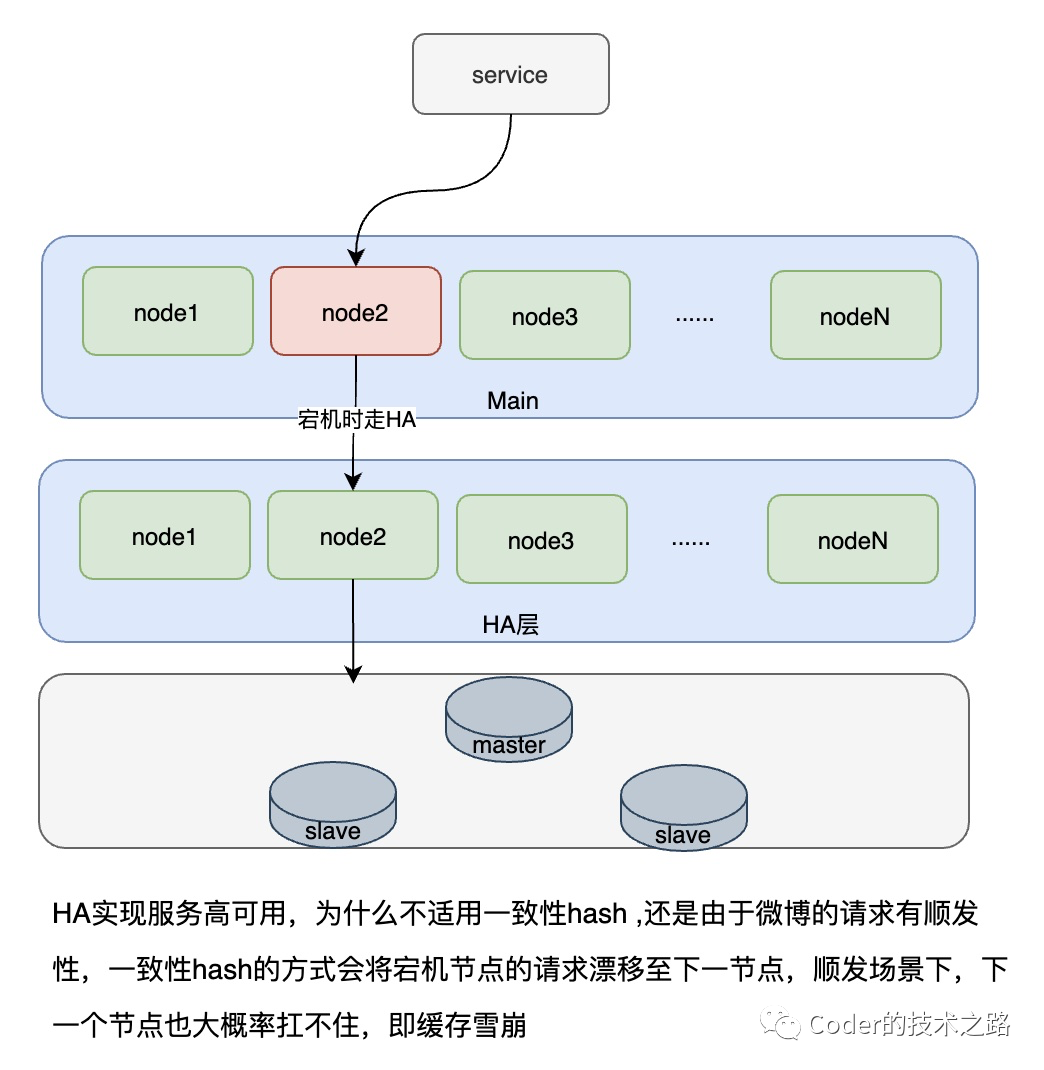
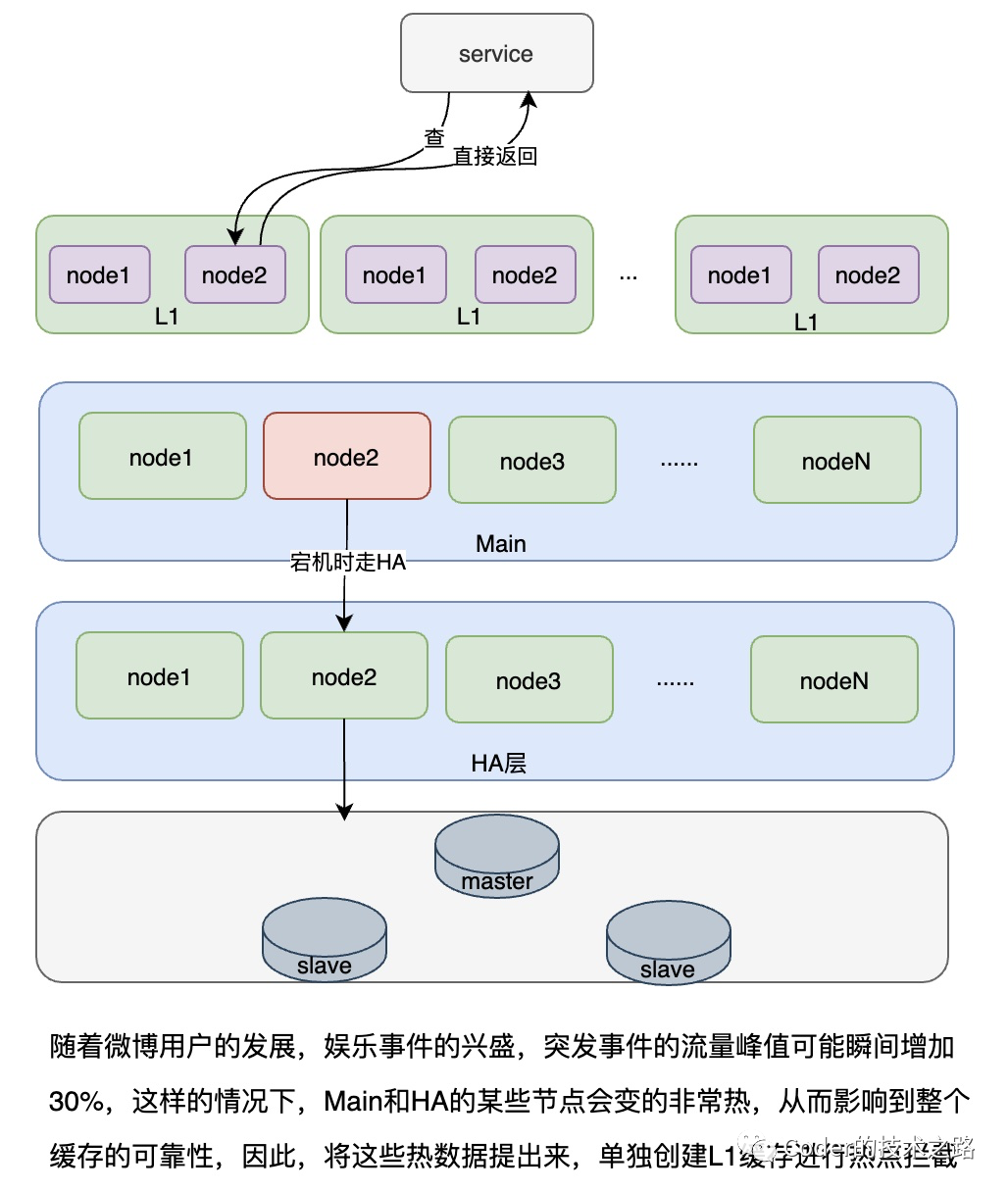
某组资源请求量过大导致需要过多的节点 Cache 的伸缩容和节点的替换动静太大 过多资源带来的运维问题 Cache的易用性问题
CacheService缓存服务[8]
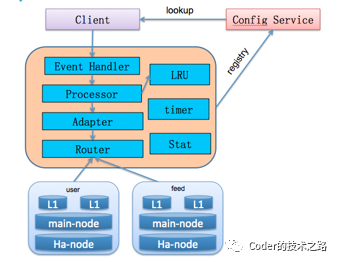
Redis在微博的极致运用[9][10]
$ 单线程下bgsave重操作卡顿问题
从主线程中独立出来Bio thread,专门执行Bgsave等操作,避免干扰; 在Redis中内置Cronsave功能,控制备份时间; 放弃bgaofrewrite。
$ redis完全替代mysql实现存储落地
修改了AOF机制,增加原本不存在的POS位; 修改了Replication机制,实现基于AOF+POS位置的数据同步 修改落地机制,改为RDB+AOF滚动机制,保障数据持久化存储。
$ longset定制化数据结构
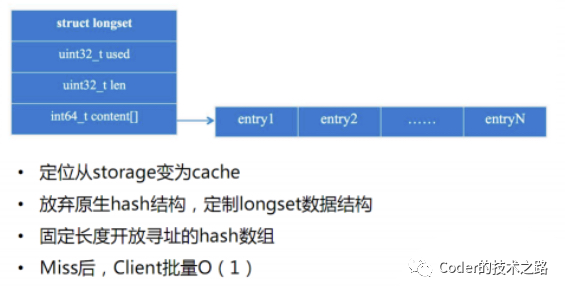
$ 计数功能优化
3.2知乎首页已读过滤缓存设计[11]
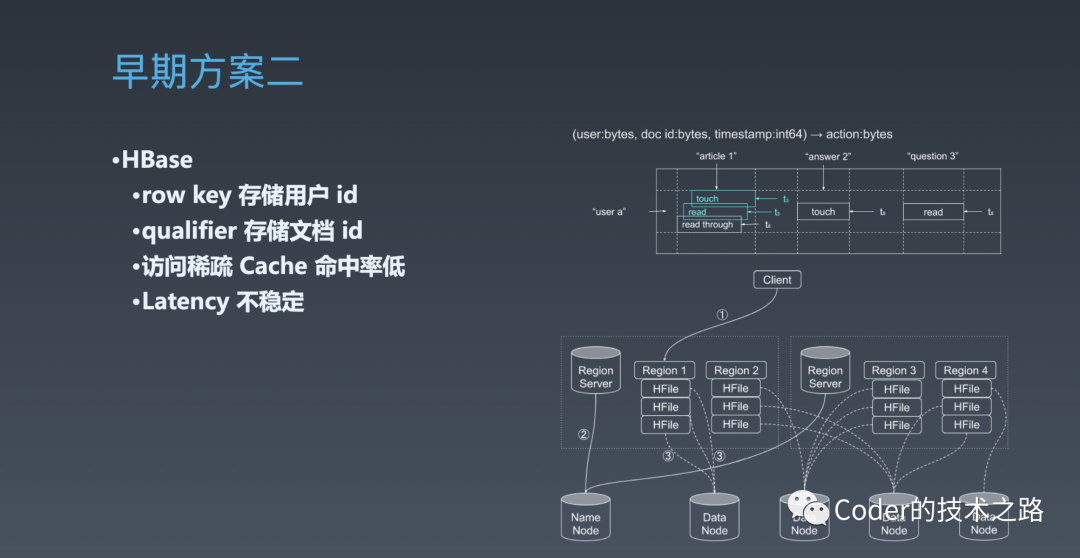
$ 早期方案
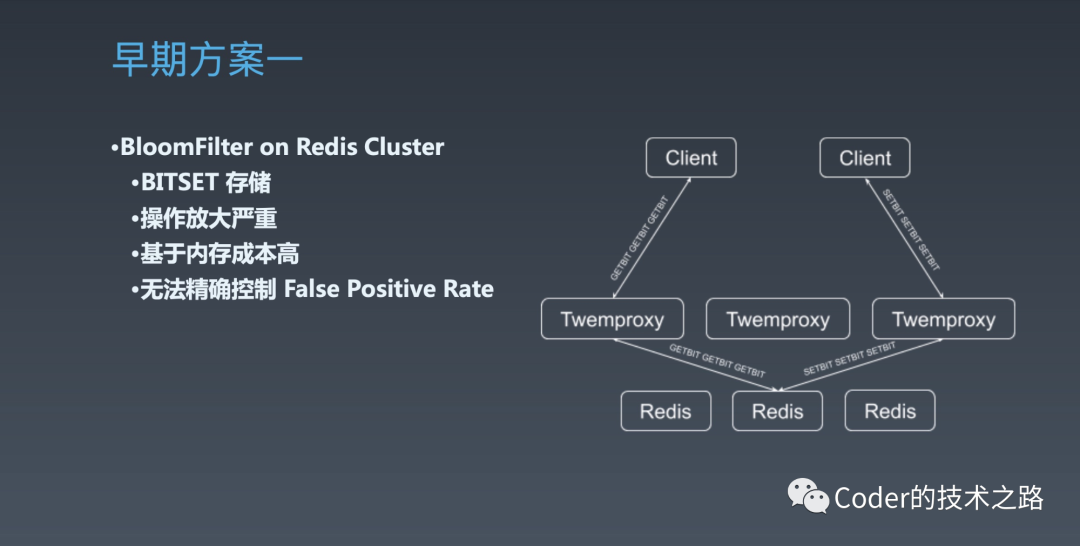
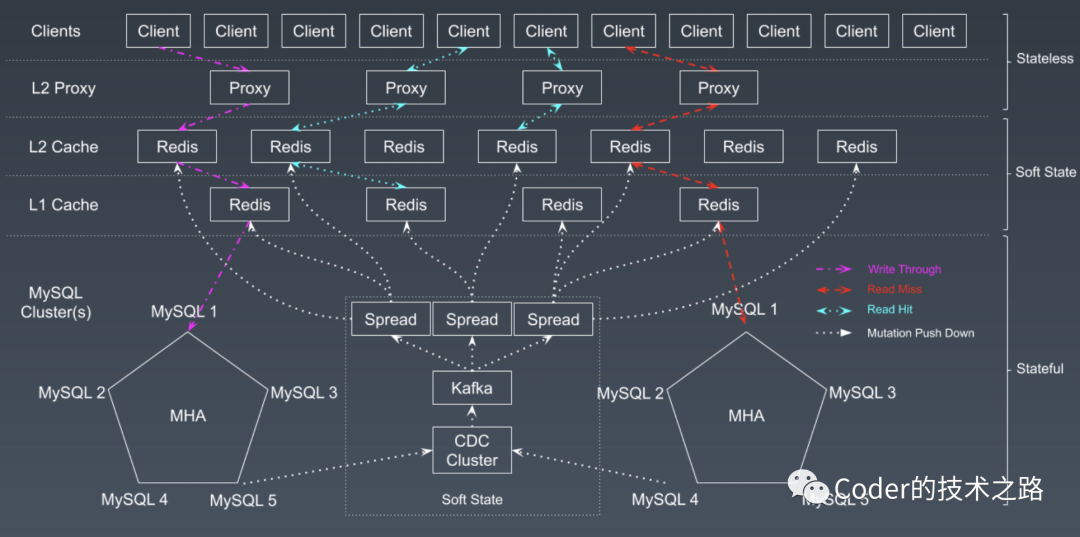
$ 优化方案
Part4总结
高并发系列历史文章微信链接文档
垂直性能提升
1.1. 架构优化:集群部署,负载均衡
1.2. 万亿流量下负载均衡的实现
1.3. 架构优化:消息中间件的妙用
1.4. 架构优化:用消息队列实现存储降级
1.5. 存储优化:mysql的索引原理和优化
1.6. 存储优化:explain索引优化实战
1.7. 存储优化:详解分库分表
1.8. 本篇:存储优化:缓存为王
好文推荐
Red jujube


面试 Google, 我失败了 | Google 面经分享

新垣结衣嫁了个“非典型性”程序员

二本学历北漂女程序员:我被大厂淘汰的时候,同事们笑出了鹅叫

一键三连「分享」、「点赞」和「在看」
技术干货与你天天见~
评论