
数据湖 | 如何快速搭建云原生企业级数据湖架构及实践分享
内容框架:
背景介绍
如何使用 DLF数据湖
产品Demo
直播回看链接:
https://developer.aliyun.com/live/247227
什么是数据湖:
结构化数据( Orc 、Parquet )
半结构化数据 ( Json 、Xml )
非结构化数据(图像 、视频)
为什么需要数据湖:
1、数据规模进一步扩大
大数据存储需要治理
数据治理需要厘清数据依赖关系(血缘)
用户需要明确大数据整体成本(TCO)
2、数据来源多样化
事务数据(MySQL, SqlServer)
搜索数据 (SOLR)
批处理数据 (SPARK, HIVE)
3、数据格式多样化
Parquet / Orc / Avro / Csv / Json / Text
4、数据分析场景多样化
基于语义的搜索分析
随机/近实时 OLAP 分析
5、数据分析用户多元化
分析用户角色多元化 (开发/测试/数据/BI)
用户数据访问合规管控诉求
数据湖能做什么:
1、针对数据规模进一步扩大
数据湖提供 【数据血缘】服务
数据湖提供 【数据治理】服务
数据湖帮助用户明确大数据的整体成本
2、针对数据来源多样化
DLF 提供【统一元数据】服务
3、针对数据格式多样化
DLF 提供【数据入湖/元数据爬取】服务
• 支持 MYSQL/KAFKA 入湖,元数据爬取
• 支持离线/实时入湖, 满足不同业务时效要求
• 支持 DELTA/HUDI 等数据湖格式
4、针对数据分析场景多样化
DLF 提供【统一元数据服务】
• 可以切换不同引擎 MC/EMR/DDI
• 数据探索在不同引擎之间一致
5、针对数据分析用户多元化
数据湖提供【访问权限控制】服务
• 多引擎下的数据访问集中授权/避免反复授权
• 解决多用户数据访问合规问题
数据湖提供【访问日志审计】服务
• 解决用用户数据访问合规审查问题
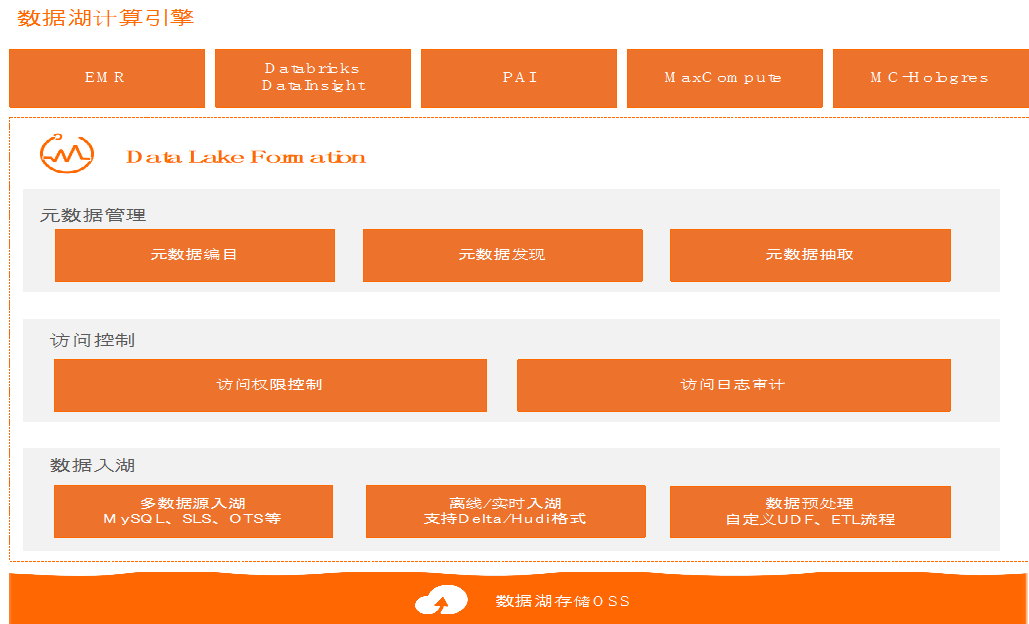
数据入湖:
1、大量异构外部数据源【数据入湖】服务
全量导入 :批量入湖一次导入
增量导入 :实时入湖流失增量导入

2、大量现存Hadoop生态数据 【元数据爬取】服务
将数据导入数据湖OSS进行存储
元数据爬取 提取原有数据schema

数据查询:
数据湖【统一元数据】服务支持多种引擎查询
使用数据探索(SPARK)对入湖数据进行探查
使用MAXCOMPUTE对数据进行深度复杂加工
使用Databricks DDI专用集群对数据进行探索
更多引擎支持中…
数据治理:
1、使用【权限访问控制】服务控制数据访问
进行 库/表/列 级别的访问权限设置
统一的元数据,只需要设置一次
2、使用【数据治理】服务明确大数据总成本
日/周/月 级别的存储使用情况 – 及时释放过时的大存储文件
日/周/月 级别的计算使用情况 – 及时识别数据上的异常计算
数据湖构建 DLF 体验链接:
https://dlf.console.aliyun.com/
点击文章下方阅读原文,直接观看直播视频回放,获取讲师实例讲解~
不错过每次直播信息、探讨更多数据湖相关技术问题,欢迎扫码加入钉钉交流群!