
数据湖YYDS! Flink+IceBerg实时数据湖实践
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜

数据湖的前世今生
互联网技术发展的当下,数据是各大公司最宝贵的资源之一已经是不争的事实。收据的收集、存储和分析已经成为科技公司最重要的技术组成部分。大数据领域经过近十年的高速发展,无论是实时计算还是离线计算、无论是数据仓库还是数据中台,都已经深入各大公司的各个业务。
"数据湖"这个概念从 2020 年中期开始频繁走入大众视野。然而对于数据湖的定义上确没有统一的标准。但是我们从维基百科、AWS、阿里云的官网描述中可以找到一些共同点:
多计算引擎支持
数据湖需要支持大数据领域的常见的计算引擎,包括Flink、Spark、Hive等,同时支持流处理和批处理;
支持多种存储引擎
存储引擎应包含常见的结构化存储:MySQL、Hbase、OLAP 数据库;也应该支持常见的非结构化存储:HDFS、小文件存储引擎等;
支持数据更新和事务(ACID)
需要方便的对数据进行更新,并且需要满足事务特性;
元数据管理和数据质量保障
数据湖应提供统一的元数据管理和企业级的权限体系。数据湖相比于传统的数据仓库最核心的能力之一在于支持各种各样的非结构化数据,基于这样的背景,诞生了类似Hudi、IceBerg之类的数据湖存储技术。
各大云厂商的数据湖架构
这部分我们用国内外主流的云服务商的产品来做介绍,看看各大厂商的技术架构设计有什么区别和共同点。
阿里云
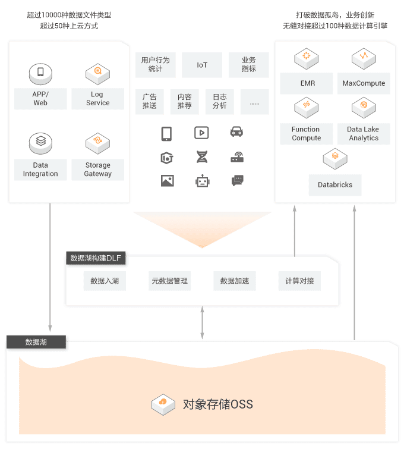
在阿里云官网上给出了云原生企业级数据湖解决方案,该方案的四个显著的优势是:
海量弹性: 计算存储分离,存储规模弹性扩容 生态开放:对Hadoop生态友好,且无缝对接阿里云各计算平台 高性价比:统一存储池,避免重复拷贝,多种类型冷热分层 更易管理:加密、授权、生命周期、跨区复制等统一管理
并且,阿里云给出了利用开源生态构建数据湖的方案:
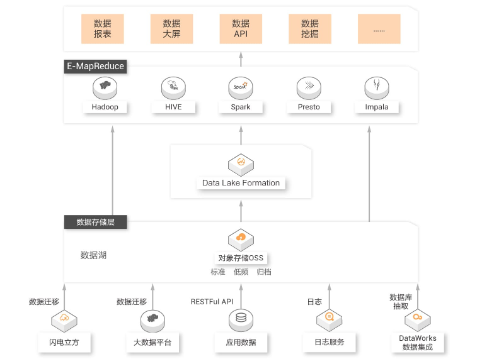
在这个开源场景的架构下,几大关键的技术点:
支撑 EB 规模的数据湖,支持多种数据通道,全面覆盖日志、消息、数据库、HDFS 各种数据源 无缝对接 Hive、Spark、Presto、Impala 等大数据处理引擎,消除数据孤岛 Data Lake Formation 提供数据湖元数据管理、数据湖加速等服务
AWS
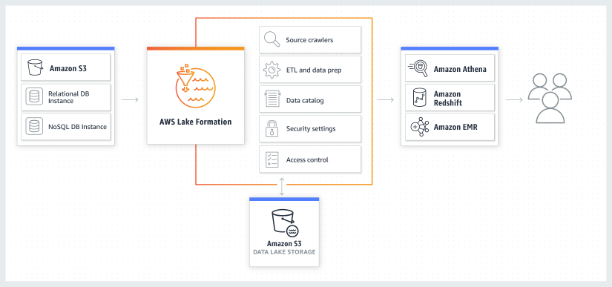
AWS 在 2018 年推出了 AWS Lake Formation,它的上游是 S3 存储以及 NoSQL 存储,AWS Lake Formation 承担了元数据定义的功能,写入 S3 中的数据包括爬虫数据、ETL 数据、日志数据等等,并且 AWS 提供了完整的权限体系。
华为云
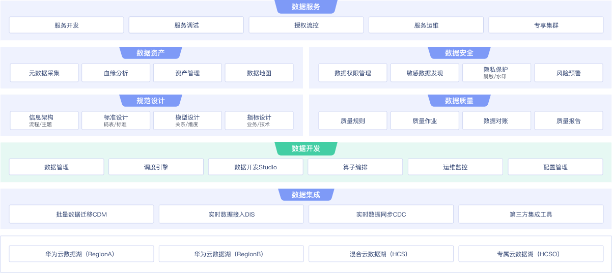
华为数据湖治理中心完全兼容了Spark、Flink的生态,提供一站式的流处理、批处理、交互式分析的Serverless融合处理分析服务。用户不需要管理任何服务器,即开即用。支持标准SQL/Spark SQL/Flink SQL,支持多种接入方式,并兼容主流数据格式。数据无需复杂的抽取、转换、加载,使用SQL或程序就可以对云上数据库以及线下数据库的异构数据进行探索。
看了国内外主流云厂商的数据湖解决方案,我个人认为数据湖的出现并不是一项创新的技术,更像是一种数据理念的发展。数据湖不是一个简单的技术,实现数据湖的方式多种多样,我们评价一个数据湖解决方案的成熟与否,关键在于其提供的数据治理、元数据管理、数据计算、权限管理的成熟程度。
湖仓一体才是未来?
在数据湖的发展过程中,Data Lakehouse(湖仓一体)数据架构被推上了风口浪尖。湖仓一体架构的出现结合了传统数据仓库和数据湖的优势。Lakehouse的概念最早是由 Databricks 所提出的:《What is a Lakehouse?》,Databricks的出现使得数据的存储变得更加廉价和具有弹性。并且在提升数据质量上游长足的进步。Data Lakehouse有一些关键特性:
事务支持 Schema支持 端到端的流式支持 计算存储分离
Lakehouse通常会使用Iceberg,Hudi,Delta Lake等开源组件,将最底层的数据存储格式进行统一。并且Lakehouse支持不同的语言进行直接查询。湖仓一体的架构将数据仓库和数据湖进行了打通,兼具灵活存储的同时极大地降低了数据管理、计算和存储成本。
Flink+Iceberg构建数据湖实战
2.1 数据湖三剑客
在数据湖解决方案中有非常重要的一环,那就是数据存储和数据计算之间的格式适配。大数据领域发展至今,各个领域已经非常成熟,无论是实时计算引擎 Flink 和 Spark,海量消息中间件 Kafka,各式各样的数据存储OLAP等已经形成了足够完善的数据解决方案体系。但是不同数据计算引擎在计算时需要读取数据,数据格式需要根据不同的计算引擎进行适配。
这是一个非常棘手的问题,这个中间层不单单是数据存储的格式问题,更是一种元数据的组织方式。正是这样一种解决方案:介于上层计算引擎和底层存储格式。成为数据湖解决方案中的关键一环。
目前的开源领域出现了 Delta、Apache Iceberg 和 Apache Hudi 三种比较成熟的解决方案。网上已经有很多的文章来介绍三者的区别,因为篇幅的原因我这里不再展开了。
但是我想说的是,这三种方案并没有明显的优劣之分,需要用户结合自己的业务情况进行选择。
2.2 Flink+IceBerg开发实战案例
Apache Iceberg 的官网对 IceBerg 的能力和定位做了以下阐述:
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Trino and Spark that use a high-performance format that works just like a SQL table.
Iceberg是一个为大规模数据集设计的通用的表格形式。并且适配Trino(原PrestoSQL)和Spark,提供SQL化解决方案。
根据官方文档的提示,IceBerg有一系列的特性如下:
模式演化,支持添加,删除,更新或重命名,并且没有副作用
隐藏分区,可以防止导致错误提示或非常慢查询的用户错误
分区布局演变,可以随着数据量或查询模式的变化而更新表的布局
快照控制,可实现使用完全相同的表快照的可重复查询,或者使用户轻松检查更改
版本回滚,使用户可以通过将表重置为良好状态来快速纠正问题
快速扫描数据,无需使用分布式SQL引擎即可读取表或查找文件
数据修剪优化,使用表元数据使用分区和列级统计信息修剪数据文件
兼容性好,可以存储在任意的云存储系统和HDFS中
支持事务,序列化隔离 表更改是原子性的,读者永远不会看到部分更改或未提交的更改
高并发,高并发写入器使用乐观并发,即使写入冲突,也会重试以确保兼容更新成功
其中的几个特性精准的命中了用户的痛点,包括:
ACID和多版本支持 支持批/流读写 多种分析引擎的支持
Apache Iceberg的社区非常活跃,积极拥抱 Flink 社区的实时计算体系,提供了非常友好和连接器,大大降低了开发门槛。截止小编发稿前为止,Apache IceBerg 已经更新到了 0.12.0 版本,并且仍在高速迭代中。
https://uploader.shimowendang.com/f/aMECh654lRQPVZxd.png!thumbnail?accessToken=eyJhbGciOiJIUzI1NiIsImtpZCI6ImRlZmF1bHQiLCJ0eXAiOiJKV1QifQ.eyJhdWQiOiJhY2Nlc3NfcmVzb3VyY2UiLCJleHAiOjE2MzM5NzI0MjcsImciOiJrV0tXNmdRcnI4Z0pSUXRKIiwiaWF0IjoxNjMzOTcyMTI3LCJ1c2VySWQiOjE4NTAyMDc1fQ.-s9-0vlGqhwfssky9IAAJ2ByuzEkBlPUyZZrdiUuRqw
2.3 Flink 整合 IceBerg
我们这里采用经典的 Iamda 架构,实时链路通过 Flink 消费 Kafka 并且通过操作 IceBerg 将数据同步到数据湖内。
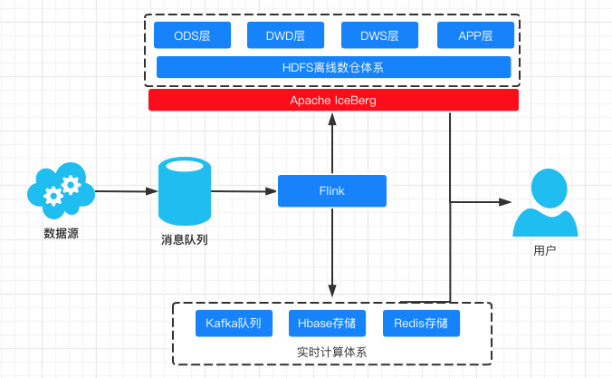
Flink 整合 IceBerg
目前 IceBerg 同时支持 Flink DataStream 和 SQL 两种方式,目前 IceBerg 对 Flink 的支持为 Flink 1.11.x 版本(Flink 1.12.x 版本没有经过详细测试),详细的兼容情况如下:
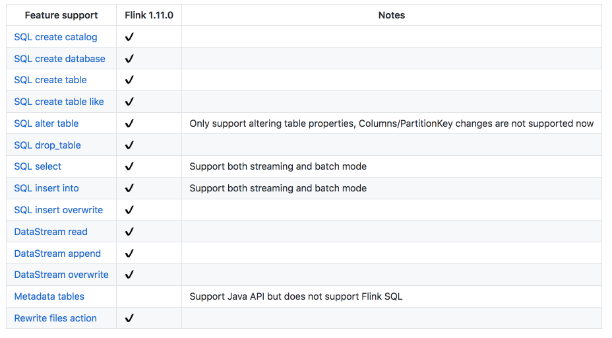
首先我们需要添加依赖,根据官方文档我们需要添加的依赖如下:
org.apache.iceberg
iceberg-flink-runtime
0.11.1
首先我们需要创建 CataLog,CataLog 是保存了 IceBerg 和 HDFS 的目录的映射关系:
CREATE CATALOG iceberg_catalog WITH (
'type'='iceberg',
'catalog-type'='hive'," +
'warehouse'='hdfs://localhost/user/hive/warehouse',
'uri'='thrift://localhost:9083'
)
然后我们需要在 iceberg_catalog 中创建表:
CREATE TABLE iceberg_catalog.iceberg_hadoop_db.iceberg_table (
user_id STRING,
amount DOUBLE,
time_stamp STRING)
PARTITIONED BY (time_stamp)
WITH ('connector'='iceberg','write.format.default'='orc')
此时我们就可以通过 Flink 将 Kafka 中的数据通过 IceBerg 写入 HDFS 中了,这里一定要注意,在 Flink 中一定要开启 CheckPoint:
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.enableCheckpointing(300 * 1000);
env.getCheckpointConfig().setCheckpointTimeout(60000);
然后我们需要使用 Hive CataLog 创建一张 Kafka Source 表,读取 Kafka 中的数据:
String HIVE_CATALOG = "hive_catalog";
String DEFAULT_DATABASE = "tmp";
String HIVE_CONF_DIR = "/xx/resources";
Catalog catalog = new HiveCatalog("hive_catalog", "hive_catalog_database", "/user/hive/resources");
tenv.registerCatalog("hive_catalog", catalog);
tenv.useCatalog("hive_catalog");
// create kafka stream table
tenv.executeSql("DROP TABLE IF EXISTS kafka_source_iceberg");
tenv.executeSql(
"CREATE TABLE kafka_source_iceberg (\n" +
" user_id STRING,\n" +
" amount DOUBLE,\n" +
" time_stamp STRING\n" +
") WITH (\n" +
" 'connector'='kafka',\n" +
" 'topic'='kafka_topic',\n" +
" 'scan.startup.mode'='latest-offset',\n" +
" 'properties.bootstrap.servers'='localhost:9092',\n" +
" 'properties.group.id' = 'iceberg_group',\n" +
" 'format'='json'\n" +
")");
然后我们就可以消费 Kafka Source 表中的数据,并且写入 IceBerg 中了:
tenv.executeSql(
"INSERT INTO iceberg_catalog.iceberg_hadoop_db.iceberg_table" +
" SELECT user_id, amount, time_stamp FROM hive_catalog.hive_catalog_database.kafka_source_iceberg");
到此,我们就完成了整个实时数据的入湖过程。
总结
数据湖的发展方兴未艾,开源社区仍然在高速迭代中,但是可以预见的是,数据湖或者湖仓一体的数据架构未来一定会成为主流,是每个数据开发人员都需要掌握的知识。

Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
4万字长文 | ClickHouse基础&实践&调优全视角解析
你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。