
腾讯云EMR基于YARN针对云原生容器化的优化与实践

一、Hadoop Yarn on Kubernetes Pod 混合部署模式
当弹性规则被触发后,离在线部署模块获取当前在线TKE集群中可以提供的闲置算力的规格及数量,调用Kubernetes api创建对应数量的资源,ex-scheduler扩展调度器确保Pod被创建在剩余资源更多的节点上,该POD负责启动YARN的服务。

通过该方案,Yarn的NodeManager服务可以快速部署到POD节点中。但也Yarn原生调度没有考虑异构资源,由此引发了两个问题:
1. AM的POD被驱逐,导致APP失败
2. Yarn原生非独占分区资源共享局限性
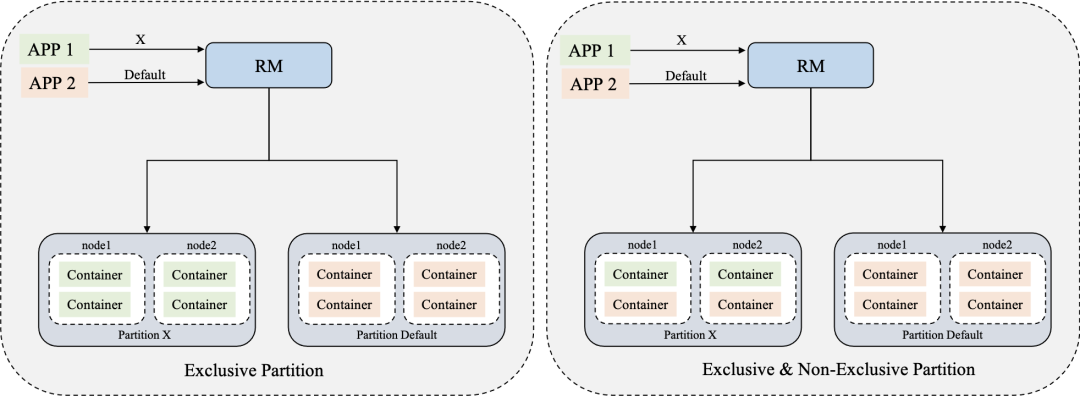
独占分区(Exclusive):例如指定独占分区x,Yarn的container只会分配到该x分区。
非独占分区(Non-exclusive):例如非独占分区x,x分区的资源可以共享给default分区。
只有当指定分区default时,default上运⾏的Application可以使⽤分区x的资源。
二、对Yarn改造带来的挑战
对上述feature的开发,除了需求技术本⾝的难度。还需要考虑到尽可能降低用户存量集群稳定性的影响,减少用户业务侧改造成本。
集群稳定性:Hadoop Yarn作为大数据系统中的基础调度组件,如果改动过多,引发的故障几率就会增大。同时引入的feature,必然需要升级存量集群的Haoop Yarn。升级操作要做到对存量业务集群无感知,不能影响到当天的业务。 业务侧使用成本:引入的新feature也必须符合原⽣yarn的使用习惯,方便业务侧用户理解,同时降低业务侧对代码的改造。
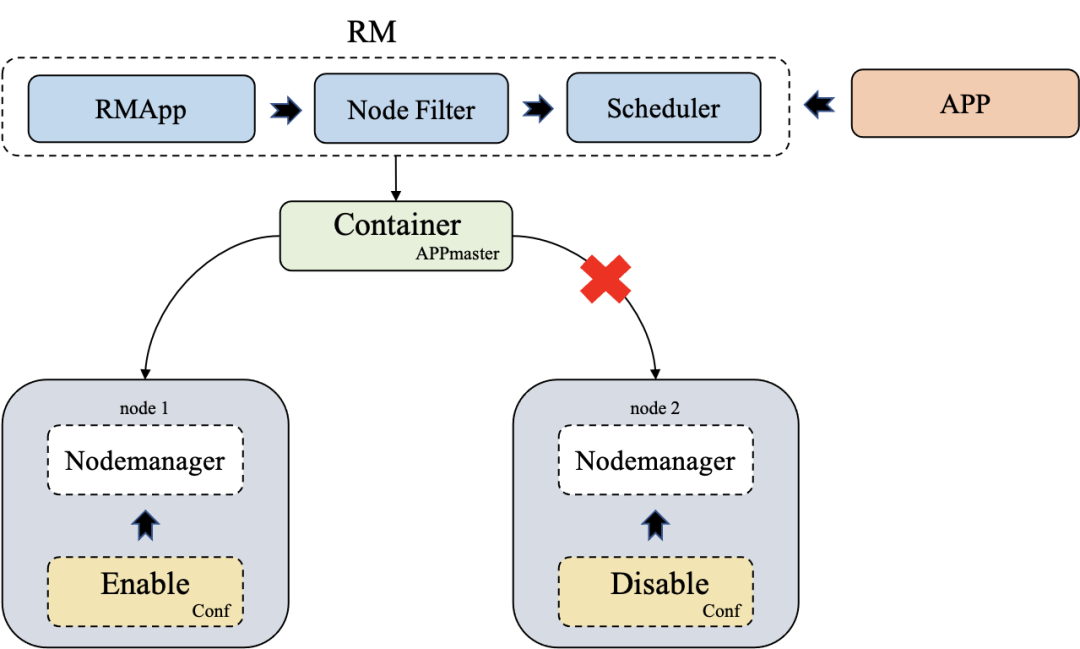
1. AM自主选择存储介质
去集中化:减少ResourceManager处理逻辑。否则,扩容资源时,还需将资源信息通过RPC/配置流入到ResourceManager中。如无必要,勿增实体,对ResourceManager的改造应该轻量化。 集群稳定性:存量业务集群对Yarn升级后,需要重启NodeManager, 只需要重启ResourceManager。Yare的高可用特性可保证升级过程对业务无影响。无需重启NodeManager 的原因是,NM默认将本机资源视为可分配。 简单易用:用户可以通过配置⾃由决定任务资源拥有分配AM的权利,不单单局限POD容器资源。
2. 多标签动态分配资源
资源隔离:分区A设置Non-exclusive后,资源被其他分区上的APP占用后,无法及时交换给分区A的App。
自由共享资源:只有default分区才有资格申请Non-exclusive分区资源。
动态选择分区资源:多分区资源共享时,无法根据分区剩余资源大小选择可用区,影响任务执行效率。

三、实操演练
队列设置:
<configuration><property><name>yarn.scheduler.capacity.root.queues</name><value>a,b</value></property><property><name>yarn.scheduler.capacity.root.accessible-node-labels.x.capacity</nam e><value>100</value></property><property><name>yarn.scheduler.capacity.root.accessible-node-labels.y.capacity</nam e><value>100</value></property><!-- configuration of queue-a --><property><name>yarn.scheduler.capacity.root.a.accessible-node-labels</name><value>x</value></property><property><name>yarn.scheduler.capacity.root.a.capacity</name><value>50</value></property><property><name>yarn.scheduler.capacity.root.a.accessible-node-labels.x.capacity</n ame><value>100</value></property><!-- configuration of queue-b --><property><name>yarn.scheduler.capacity.root.b.accessible-node-labels</name><value>y</value></property><property><name>yarn.scheduler.capacity.root.b.capacity</name><value>50</value></property><property><name>yarn.scheduler.capacity.root.b.accessible-node-labels.y.capacity</n ame><value>100</value></property></configuration>
yarn.nodemanager.am-alloc-disabled = true
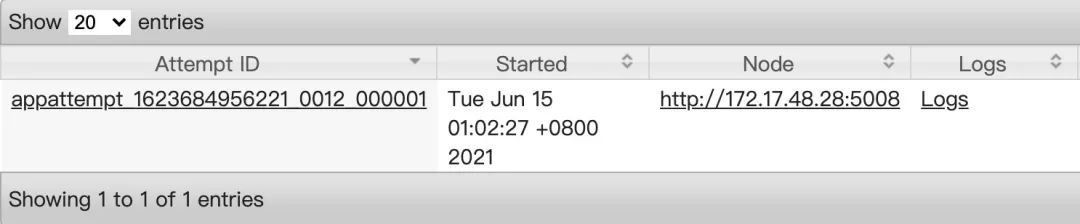

hadoop jar /usr/local/service/hadoop/share/hadoop/mapreduce/hadoop-mapredu ce-examples-3.1.2.jar pi -D mapreduce.job.queuename="a" -D mapreduce.job. node-label-expression="x||" 10 10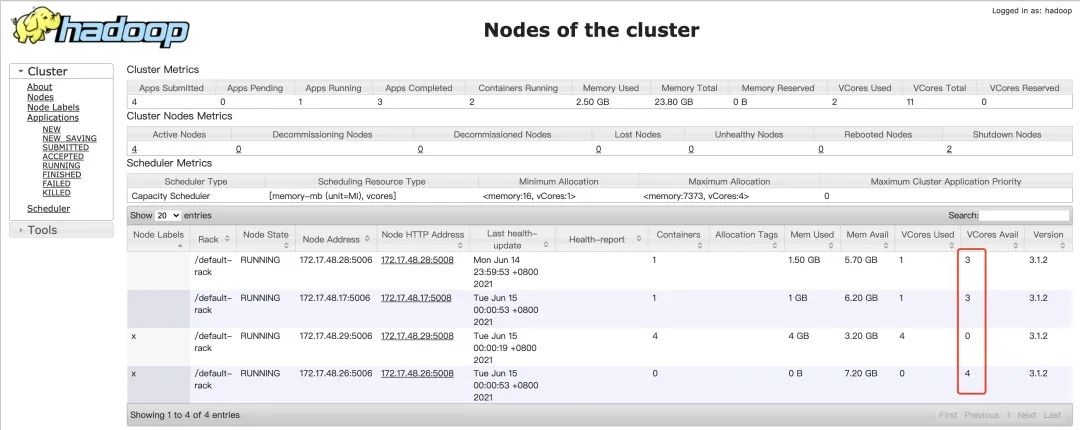
四、Hadoop Yarn on Kubernetes Pod 最佳实践
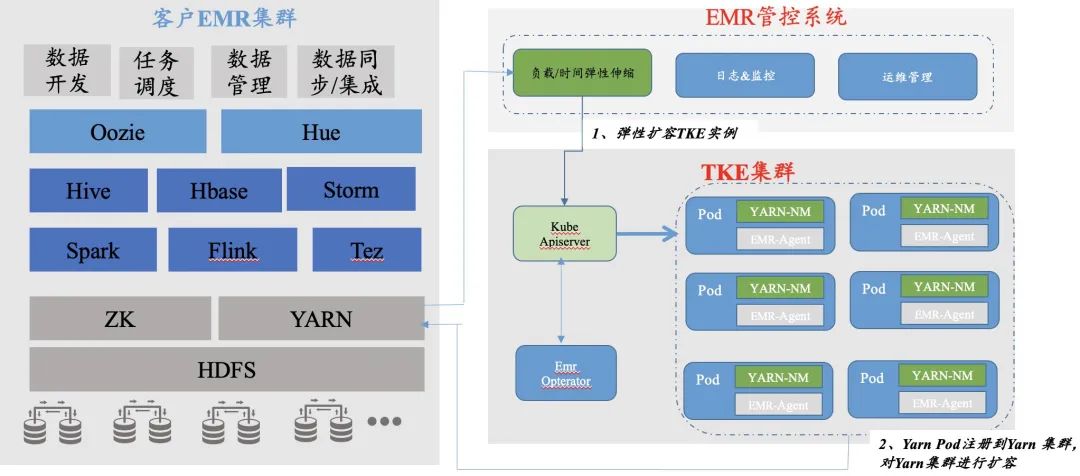
该客户大数据应用和存储跑在Yarn管理的大数据集群,在生产环境中,面临诸多问题,主要体现在大数据的算力不足和在线业务波谷时资源的浪费。如离线计算在算力不足时,数据准时性无法得到保证,尤其是当遇到随机紧急大数据查询任务,没有可用的计算资源,只能停掉已有的计算任务,或者等已有任务完成,⽆论哪种⽅式,总体任务执行的效率都会大打折扣。
基于Hadoop Yarn on Kubernetes Pod 方案,将离线任务自动扩容至云上集群,与TKE在线业务集群混合部署,充分利用云上波谷时段的闲置资源,提高离线业务的算力,并利用云上资源快速的弹性扩容能力,及时补充离线计算的算力。
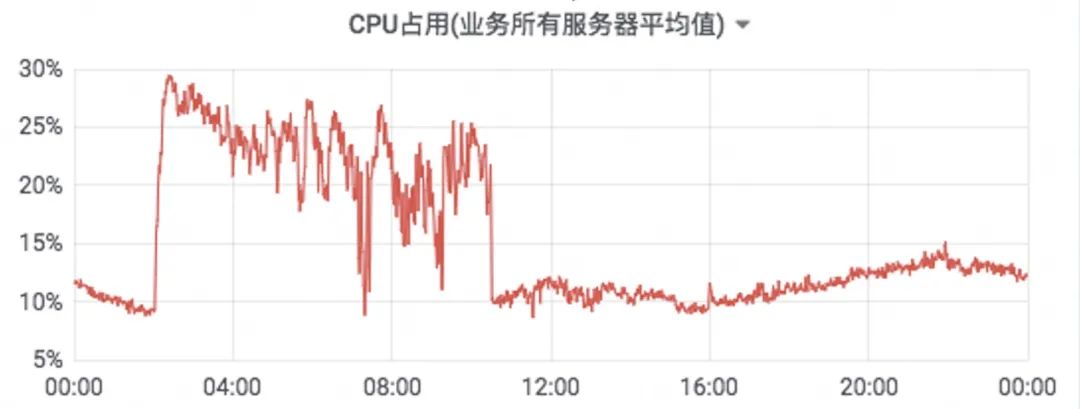
通过Hadoop Yarn on Kubernetes Pod ⽅案对客户的在线TKE集群资源使用进下优化后,集群闲时CPU使用率能提高500%。

五、总结
本文提出了基于YARN针对云原生容器化的优化与实践,在混合部署云原生环境中,极大地提高了任务运行的稳定性,高效性,有效提高了集群资源利用率,节约硬件成本。在未来,我们会探讨更多大数据云原生场景,为企业客户带来更多的实际效益。
作者简介
张翮,腾讯云高级工程师,目前主要负责腾讯云大数据产品弹性MapReduce的管控相关模块,和重要组件Hive的技术研发。向Apache Hive,Apache Calcite开源项目贡献过代码,毕业于电子科技大学。
