云原生时代的Java应用优化实践
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」

导语
Java从诞生至今已经走过了26年,在这26年的时间里,Java应用从未停下脚步,从最开始的单机版到web应用再到现在的微服务应用,依靠其强大的生态,它仍然占据着当今语言之争的“天下第一”的宝座。但在如今的云原生serverless时代,Java应用却遭遇到了前所未有的挑战。
在云原生时代,云原生技术利用各种公有云、私有云和混合云等新型动态环境,构建和运行可弹性扩展的应用。而我们应用也越来越呈现出以下特点:
基于容器镜像构建
Java诞生之初,靠着“一次编译,到处运行”的口号,以语言层虚拟化的方式,在那个操作系统平台尚不统一的年代,建立起了优势。但如今步入云原生时代,以Docker为首的容器技术同样提出了“一次构建,到处运行”的口号,通过操作系统虚拟化的方式,为应用程序提供了环境兼容性和平台无关性。因此,在云原生时代的今天,Java“一次编译,到处运行”的优势,已经被容器技术大幅度地削弱,不再是大多数服务端开发者技术选型的主要考虑因素了。此外,因为是基于镜像,云原生时代对镜像大小可以说是十分敏感,而包含了JDK的Java应用动辄几百兆的镜像大小,无疑是越来越不符合时代的要求。
生命周期缩短,并经常需要弹性扩缩容
灵活和弹性可以说是云原生应用的一个显著特性,而这也意味着应用需要具备更短的冷启动时间,以应对灵活弹性的要求。Java应用往往面向长时间大规模程序而设计,JVM的JIT和分层编译优化技术,会使得Java应用在不断的运行中进行自我优化,并在一段时间后达到性能顶峰。但与运行性能相反,Java应用往往有着缓慢的启动时间。流行的框架(例如Spring)中大量的类加载、字节码增强和初始化逻辑,更是加重了这一问题。这无疑是与云原生时代的理念是相悖的。
对计算资源用量敏感
进入公有云时代,应用往往是按用量付费,这意味着应用所需要的计算资源就变的十分重要。Java应用固有的内存占用多的劣势,在云原生时代被放大,相对于其他语言,使用起来变得更加“昂贵”。
由此可见,在云原生时代,Java应用的优势正在不断被蚕食,而劣势却在不断的被放大。因此,如何让我们的应用更加顺应时代的发展,使Java语言能在云原生时代发挥更大的价值,就成了一个值得探讨的话题。为此,笔者将尝试跳出语言对比的固有思路,为大家从一个更全局的角度,来看看在云原生应用发布的全流程中,我们都能够做哪些优化。
镜像构建优化
Dockerfile
从Dockerfile说起是因为它是最基础的,也是最简单的优化,它可以简单的加快我们的应用构建镜像和拉取镜像的时间。
以一个Springboot应用为例,我们通常会看到这种样子的Dockerfile:
FROM openjdk:8-jdk-alpineCOPY app.jar /ENTRYPOINT ["java","-jar","/app.jar"]
足够简单清晰,但很显然,这并不是一个很好的Dockerfile,因为它没有利用到Image layer去进行效率更高的缓存。
我们都知道,Docker拥有足够高效的缓存机制,但如果不好好的应用这一特性,而是简单的将Jar包打成单一layer镜像,就会导致,即使应用只改动一行代码,我们也需要重新构建整个Springboot Jar包,而这其中Spring的庞大依赖类库其实都没有发生过更改,这无疑是一种得不偿失的做法。因此,将应用的所有依赖库作为一个单独的layer显然是一个更好的方案。
因此,一个更合理的Dockerfile应该长这个样子:
FROM openjdk:8-jdk-alpineARG DEPENDENCY=target/dependencyCOPY ${DEPENDENCY}/BOOT-INF/lib /app/libCOPY ${DEPENDENCY}/META-INF /app/META-INFCOPY ${DEPENDENCY}/BOOT-INF/classes /appENTRYPOINT ["java","-cp","app:app/lib/*","HelloApplication"]
这样,我们就可以充分利用Image layer cache来加快构建镜像和拉取镜像的时间。
构建组件
在Docker占有镜像构建的绝对话语权的今天,我们在实际开发过程中,往往会忽视构建组件的选择,但事实上,选择一个高效的构建组件,往往能使我们的构建效率事半功倍。
传统的“docker build”存在哪些问题?
在Docker v18.06之前的`docker build`会存在一些问题:
改变Dockerfile中的任意一行,就会使之后的所有行的缓存失效
# 假设只改变此Dockerfile中的EXPOSE端口号# 那么接下来的RUN命令的缓存就会失效FROM debianEXPOSE 80RUN apt update && apt install –y HEAVY-PACKAGES
多阶段并行构建效率不佳
# 即使stage0和stage1之间并没有依赖# docker也无法并行构建,而是选择串行FROM openjdk:8-jdk AS stage0RUN ./gradlew clean buildFROM openjdk:8-jdk AS stage1RUN ./gradlew clean buildFROM openjdk:8-jdk-alpineCOPY --from=stage0 /app-0.jar /=stage1 /app-1.jar /
无法提供编译历史缓存
# 单纯的RUN命令无法提供编译历史缓存# 而RUN --mount的新语法在旧版本docker下无法支持RUN ./gradlew build# since Docker v18.06# syntax = docker/dockerfile:1.1-experimental=type=cache,target=/.cache ./gradlew build
镜像push和pull的过程中存在压缩和解压的固有耗时
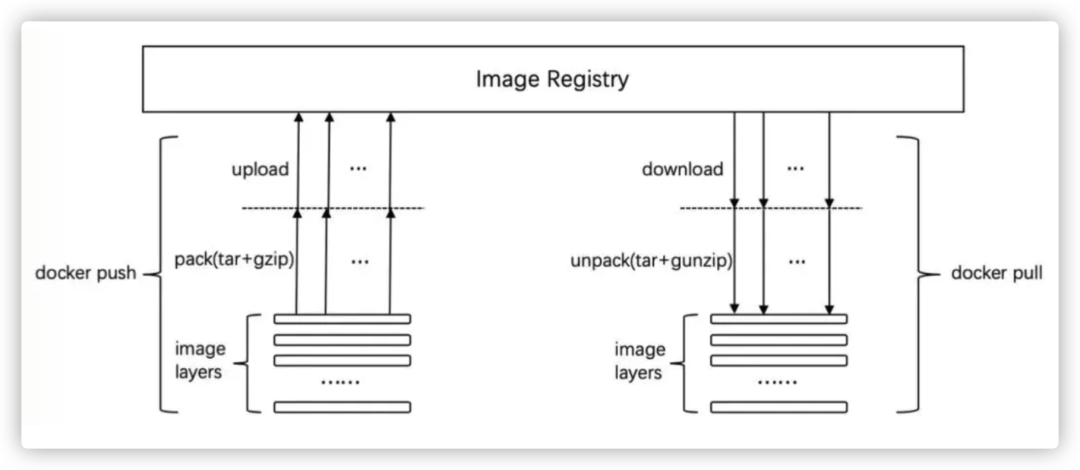
如上图所示,在传统的docker pull push阶段,存在着pack和unpack的耗时,而这一部分并非必须的。针对这些固有的弊病,业界也一直在积极的探讨,并诞生了一些可以顺应新时代的构建工具。
新一代构建组件:

在最佳的新一代构建工具选择上,是一个没有银弹的话题,但通过一些简单的对比,我们仍能选出一个最适合的构建工具,我们认为,一个适合云原生平台的构建工具应该至少具备以下几个特点:
能够支持完整的Dockerfile语法,以便应用平顺迁移;
能够弥补上述传统Docker构建的缺点;
能够在非root privilege模式下执行(在基于Kubernetes的CICD环境中显得尤为重要)。
因此,Buildkit就脱颖而出,这个由Docker公司开发,目前由社区和Docker公司合理维护的“含着金钥匙出生”的新一代构建工具,拥有良好的扩展性、极大地提高了构建速度,并提供了更好的安全性。Buildkit支持全部的Dockerfile语法,能更高效的命中构建缓存,增量的转发build context,多并发直接推送镜像层至镜像仓库。
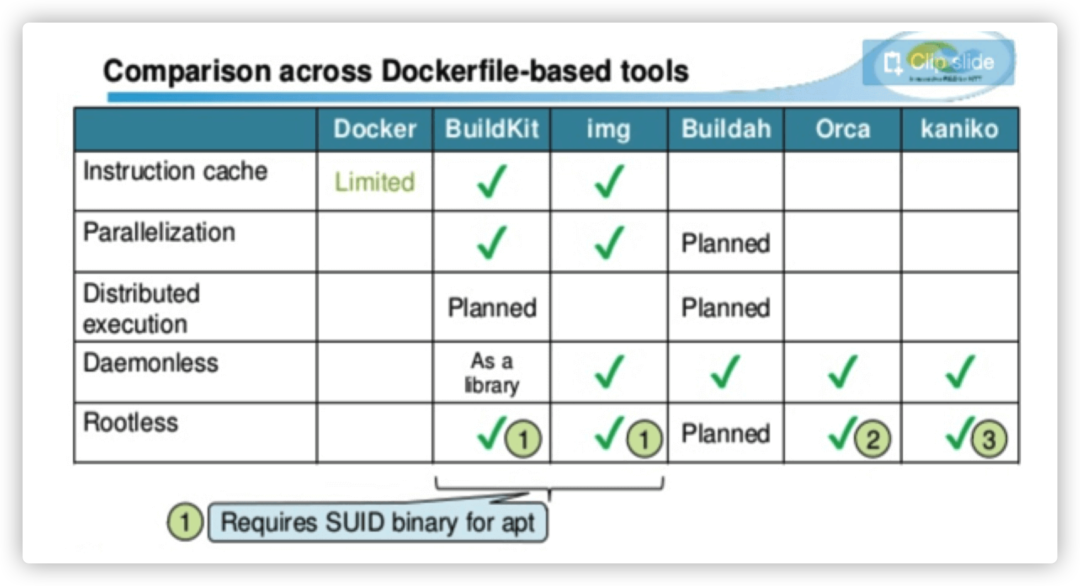
Buildkit与其他构建组件的对比

Buildkit的构建效率
镜像大小
为了在拉取和推送镜像过程中更高的控制耗时,我们通常会尽可能的减少镜像的大小。
Alpine Linux是许多Docker容器首选的基础镜像,因为它只有5 MB大小,比起其他Cent OS、Debain 等动辄一百多MB的发行版来说,更适合用于容器环境。不过Alpine Linux为了尽量瘦身,默认是用musl作为C标准库的,而非传统的glibc(GNU C library),因此要以Alpine Linux为基础制作OpenJDK镜像,必须先安装glibc,此时基础镜像大约有12 MB。
在【JEP 386】(http://openjdk.java.net/jeps/386)中,OpenJDK将上游代码移植到musl,并通过兼容性测试。这一特性已经在Java 16中发布。这样制作出来的镜像仅有41MB,不仅远低于Cent OS的OpenJDK(大约 396 MB),也要比官方的slim版(约200MB)要小得多。
应用启动加速
让我们首先来看一下,一个Java应用在启动过程中,会有哪些阶段。
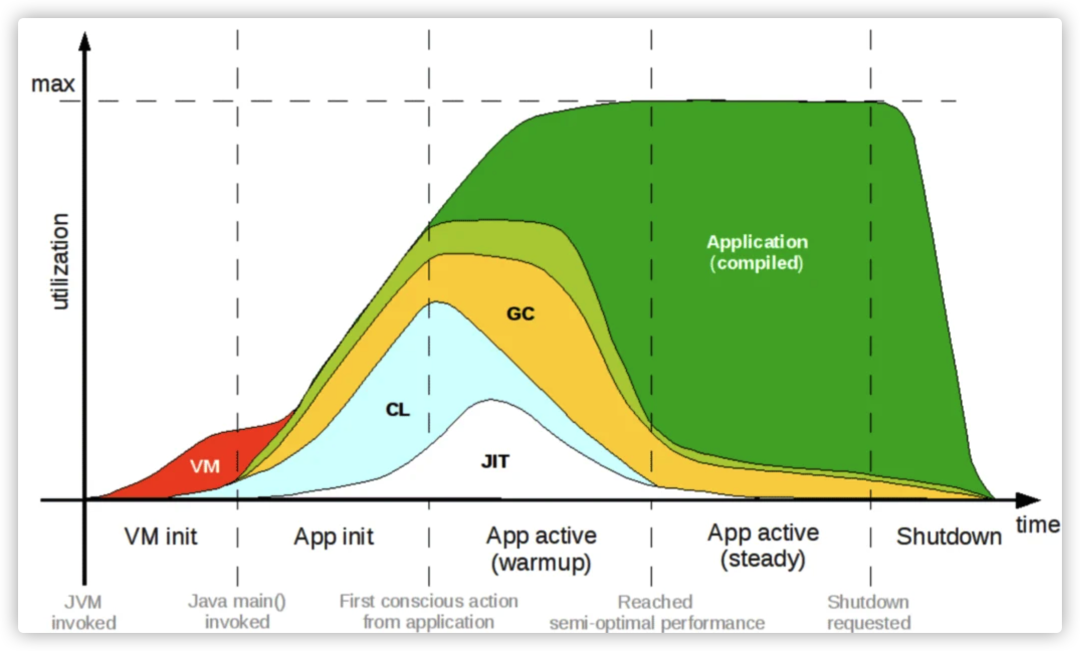
这个图代表了Java运行时各个阶段的生命周期,可以看到它要经过五个阶段,首先是VM init虚拟机的初始化阶段,然后是App init应用的初始化阶段,再经过App active(warmup)的应用预热时期,在预热一段时间后进入App active(steady)达到性能巅峰期,最后应用结束完成整个生命周期。
使用AppCDS
从上面的图中,我们不难发现,蓝色的CL(ClassLoad)部分,实际长占用了Java应用启动的阶段的一大部分时间。而Java也一直在致力于减少应用启动的ClassLoad时间。
从JDK 1.5开始,HotSpot就提供了CDS(Class Data Sharing)功能,很长一段时间以来,它的功能都非常有限,并且只有部分商业化。早期的CDS致力于,在同一主机上的JVM实例之间“共享”同样需要加载一次的类,但是遗憾的是早期的CDS不能处理由AppClassloader加载的类,这使得它在实际开发实践中,显得比较“鸡肋”。
但在从OpenJDK 10 (2018) 开始,AppCDS【JEP 310】(https://openjdk.java.net/jeps/310)在CDS的基础上,加入了对AppClassloader的适配,它的出现,使得CDS技术变得广泛可用并且更加适用。尤其是对于动辄需要加载数千个类的Spring Boot程序,因为JVM不需要在每个实例的每次启动时加载(解析和验证)这些类,因此,启动应该变得更快并且内存占用应该更小。看起来,AppCDS的一切都很美好,但实际使用也确实如此吗?

当我们试图使用AppCDS时,它应该包含以下几个步骤:
使用`-XX:DumpLoadedClassList`参数来获取我们希望在应用程序实例之间共享的类;
使用`-Xshare:dump`参数将类存储到适合内存映射的存档(.jsa文件)中;
使用`-Xshare:on`参数在启动时将存档附加到每个应用程序实例。
乍一看,使用AppCDS似乎很容易,只需3个简单的步骤。但是,在实际使用过程中,你会发现每一步都可能变成一次带有特定JVM Options的应用启动,我们无法简单的通过一次启动来获得可重复使用的类加载存档文件。尽管在JDK 13中,提供了新的动态CDS【JEP 350】(https://openjdk.java.net/jeps/350),来将上述步骤1和步骤2合并为一步。但在目前流行的JDK 11中,我们仍然逃不开上述三个步骤(三次启动)。因此,使用AppCDS往往意味着对应用的启动过程进行复杂的改造,并伴随着更为漫长的首次编译和启动时间。
同时需要注意的是,在使用AppCDS时,许多应用的类路径将会变得更加混乱:它们既位于原来的位置(JAR包)中,同时又位于新的共享存档(.jsa文件)中。在我们应用开发的过程中,我们会不断更改、删除原来的类,而JVM会从新的类中进行解析。这种情况所带来的危险是显而易见的:如果类归档文件保持不变,那么类不匹配是迟早的事,我们会遇到典型的“Classpath Hell”问题。
JVM无法阻止类的变化,但它至少应该能够在适当的时候检测到类不匹配。然而,在JVM的实现中,并没有检测每一个单独的类,而是选择去比较整个类路径,因此,在AppCDS的官方描述中,我们可以找到这样一句话:
The classpath used with -Xshare:dump must be the same as, or be a prefix of, the classpath used with -Xshare:on. Otherwise, the JVM will print an error message
即第二部步归档文件创建时使用的类路径必须与运行时使用的类路径相同(或前者是后者的前缀)。
但这是一个相当含糊的陈述,因为类路径可能以几种不同的方式形成,例如:
从带有Jar包的目录中直接加载.class文件,例如`java com.example.Main`;
使用通配符,扫描带有Jar包的目录,例如`java -cp mydir/* com.example.Main`;
使用明确的Jar包路径,例如`java -cp lib1.jar:lib2.jar com.example.Main`。
在这些方式中,AppCDS唯一支持的方式只有第三种,即是显式列出Jar包路径。这使得那些使用了大规模Jar包依赖的应用的启动语句变得十分繁琐。
同时,我们也要必须注意到,这种显式列出Jar包路径的方式并不会进行递归查找,即它只会在包含所有class文件的FatJar中生效。这意味着使用SpringBoot框架的嵌套Jar包结构,将很难利用AppCDS技术所带来的便利。
因此,SpringBoot如果想在云原生环境中使用AppCDS,就必须进行应用侵入性的改造,不去使用SpringBoot默认的嵌套Jar启动结构,而是用类似【maven shade plugin】(https://maven.apache.org/plugins/maven-shade-plugin/)重新打FatJar,并在程序中显示的声明能让程序自然关闭的接口或参数,通过Volume挂载或者Dockerfile改造的方式,来存储和加载类的归档文件。这里给出一个改造过的Dockerfile的示例:
# 这里假设我们已经做过FatJar改造,并且Jar包中包含应用运行所需的全部class文件FROM eclipse-temurin:11-jre as APPCDSCOPY target/helloworld.jar /helloworld.jar# 运行应用,同时设置一个'--appcds'参数使程序在运行后能够停止RUN java -XX:DumpLoadedClassList=classes.lst -jar helloworld.jar --appcds=true# 使用上一步得到的class列表来生成类归档文件RUN java -Xshare:dump -XX:SharedClassListFile=classes.lst -XX:SharedArchiveFile=appcds.jsa --class-path helloworld.jarFROM eclipse-temurin:11-jre# 同时复制Jar包和类归档文件COPY --from=APPCDS /helloworld.jar /helloworld.jarCOPY --from=APPCDS /appcds.jsa /appcds.jsa# 使用-Xshare:on参数来启动应用:on -XX:SharedArchiveFile=appcds.jsa -jar helloworld.jar
由此可见,使用AppCDS还是要付出相当多的学习和改造成本的,并且许多改造都会对我们的应用产生入侵。
JVM优化
除了构建阶段和启动阶段,我们还可以从JVM本身入手,根据云原生环境的特点,进行针对性的优化。
使用可以感知容器内存资源的JDK
在虚拟机和物理机中,对于 CPU 和内存分配,JVM会从常见位置(例如,Linux 中的`/proc/cpuinfo`和`/proc/meminfo`)查找其可以使用的CPU和内存。但是,在容器中运行时,CPU和内存限制条件存储在`/proc/cgroups/...`中。较旧版本的JDK会继续在`/proc`(而不是`/proc/cgroups`)中查找,这可能会导致CPU和内存用量超出分配的上限,并因此引发多种严重的问题:
线程过多,因为线程池大小由`Runtime.availableProcessors()`配置;
JVM的对内存使用超出容器内存上限。并导致容器被OOMKilled。
JDK 8u131首先实现了`UseCGroupMemoryLimitForHeap`的参数。但这个参数存在缺陷,为应用添加`UnlockExperimentalVMOptions`和`UseCGroupMemoryLimitForHeap`参数后,JVM确实可以感知到容器内存,并控制应用的实际堆大小。但是这并没有充分利用我们为容器分配的内存。
因此JVM提供`-XX:MaxRAMFraction`标志来帮助更好的计算堆大小,`MaxRAMFraction`默认值是4(即除以4),但它是一个分数,而不是一个百分比,因此很难设置一个能有效利用可用内存的值。
JDK 10附带了对容器环境的更好支持。如果在Linux容器中运行Java应用程序,JVM将使用`UseContainerSupport`选项自动检测内存限制。然后,通过`InitialRAMPercentage`、`MaxRAMPercentage`和`MinRAMPercentage`来进行对内存控制。这时,我们使用的是百分比而不是分数,这将更加准确。
默认情况下,`UseContainerSupport`参数是激活的,`MaxRAMPercentage`是25%,`MinRAMPercentage`是50%。
需要注意的是,这里`MinRAMPercentage`并不是用来设置堆大小的最小值,而是仅当物理服务器(或容器)中的总可用内存小于250MB时,JVM将用此参数来限制堆的大小。
同理,`MaxRAMPercentage`是当物理服务器(或容器)中的总可用内存大小超过250MB时,JVM将用此参数来限制堆的大小。
这几个参数已经向下移植到JDK 8u191。UseContainerSupport默认情况下是激活的。我们可以设置`-XX:InitialRAMPercentage=50.0 -XX:MaxRAMPercentage=80.0`来JVM感知并充分利用容器的可用内存。需要注意的是,在指定`-Xms -Xmx`时,`InitialRAMPercentage`和`MaxRAMPercentage`将会失效。
关闭优化编译器
默认情况下,JVM有多个阶段的JIT编译。虽然这些阶段可以逐渐提高应用的效率,但它们也会增加内存使用的开销,并增加启动时间。
对于短期运行的云原生应用,可以考虑使用以下参数来关闭优化阶段,以牺牲长期运行效率来换取更短的启动时间。
`JAVA_TOOL_OPTIONS="-XX:+TieredCompilation -XX:TieredStopAtLevel=1"`
关闭类验证
当JVM将类加载到内存中以供执行时,它会验证该类未被篡改并且没有恶意修改或损坏。但在云原生环境,CI/CD流水线通常也由云原生平台提供,这表示我们的应用的编译和部署是可信的,因此我们应该考虑使用以下参数关闭验证。如果在启动时加载大量类,则关闭验证可能会提高启动速度。
`JAVA_TOOL_OPTIONS="-noverify"`
减小线程栈大小
大多数Java Web应用都是基于每个连接一个线程的模式。每个Java线程都会消耗本机内存(而不是堆内存)。这称为线程栈,并且每个线程默认为1 MB。如果您的应用处理100个并发请求,则它可能至少有100个线程,这相当于使用了100MB的线程栈空间。该内存不计入堆大小。我们可以使用以下参数来减小线程栈大小。
`JAVA_TOOL_OPTIONS="-Xss256k"`
需要注意如果减小得太多,则将出现`java.lang.StackOverflowError`。您可以对应用进行分析,并找到要配置的最佳线程栈大小。
使用TEM进行零改造的Java应用云原生优化
通过上面的分析,我们可以看出,如果想要让我们的Java应用能在云原生时代发挥出最大实力,是需要付出许多侵入性的改造和优化操作的。那么有没有一种方式能够帮助我们零改造的开展Java应用云原生优化?
腾讯云的TEM弹性微服务就为广大Java开发者提供了一种应用零改造的最佳实践,帮助您的Java应用以最优姿态快速上云。使用TEM您可以享受的以下优势:
零构建部署
直接选择使用Jar包/War包交付,无需自行构建镜像。TEM默认提供能充分利用构建缓存的构建流程,使用新一代构建利器Buildkit进行高速构建,构建速度优化50%以上,并且整个构建流程可追溯,构建日志可查,简单高效。
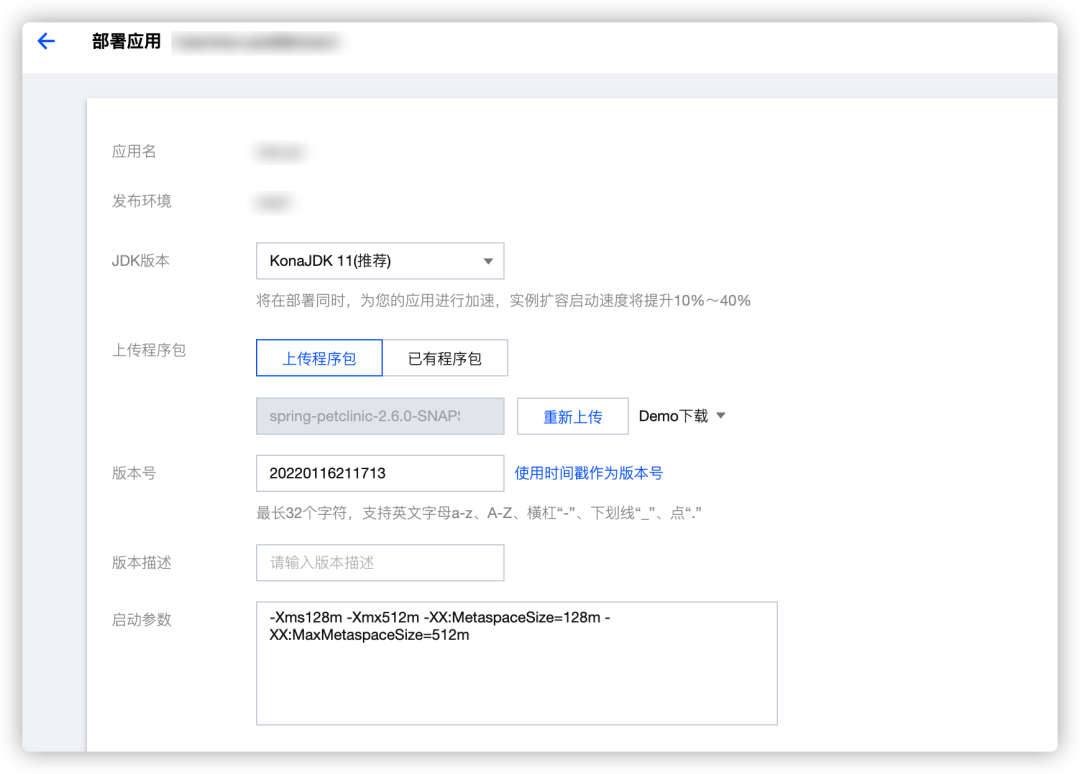
直接使用Jar包部署
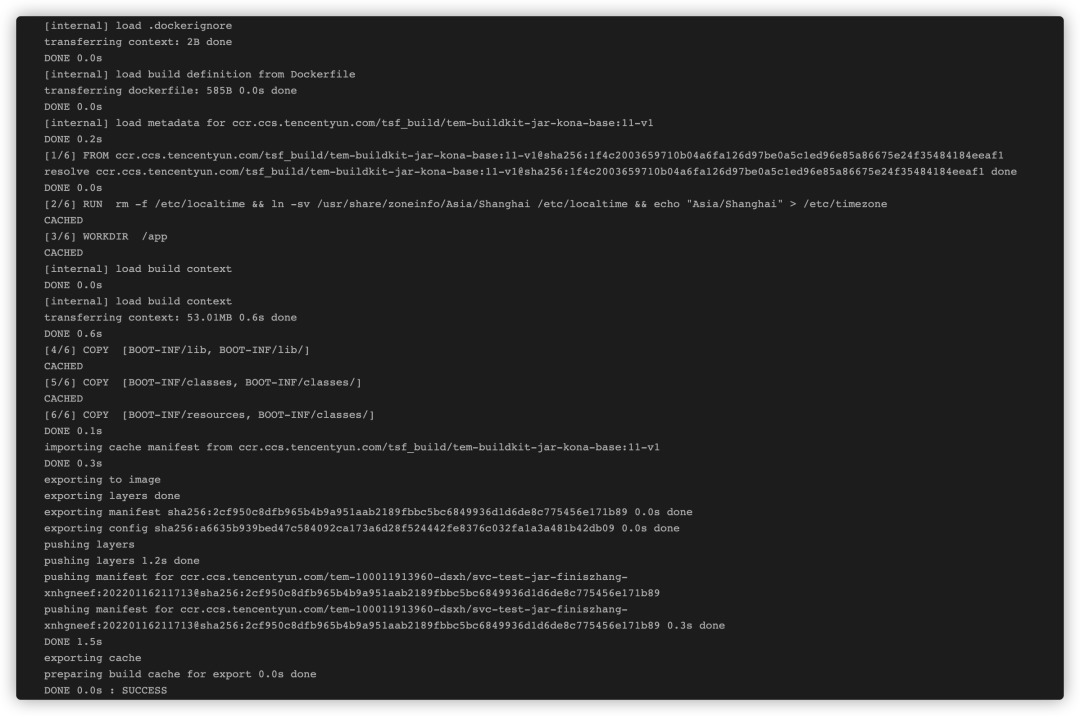
构建日志可查
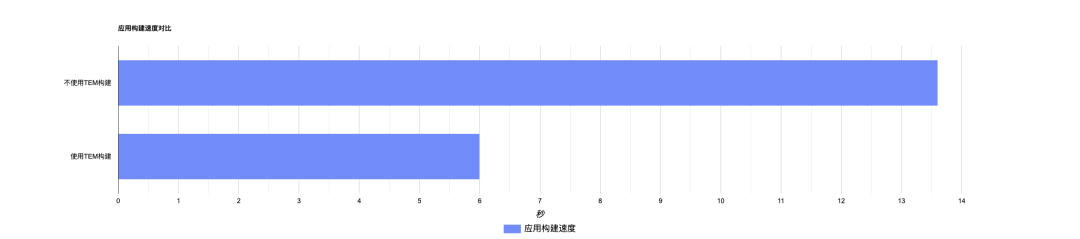
构建速度对比
零改造加速
直接使用KONA Jdk 11/Open Jdk 11进行应用加速,并且默认支持SpringBoot应用零改造加速。您无需改造原有的SpringBoot嵌套Jar包结构,TEM将直接提供Java应用加速的最佳实践,实例扩容时的启动时间将缩短至10%~40%。

不使用应用加速,规格1c2g

使用应用加速,规格1c2g
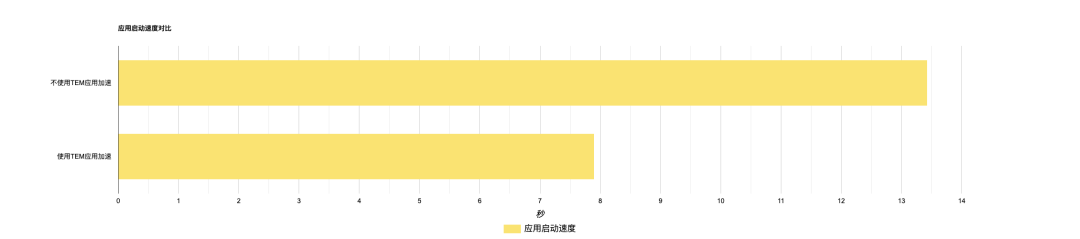
应用启动速度对比
以[spring petclinic](https://github.com/spring-projects/spring-petclinic)为例,规格1c2g
零运维监控
使用SkyWalking为您的Java应用进行应用级别的监控,您可以直观的查看JVM堆内存,GC次数/耗时,接口RT/QPS等关键参数,帮助您即使找到应用性能瓶颈。
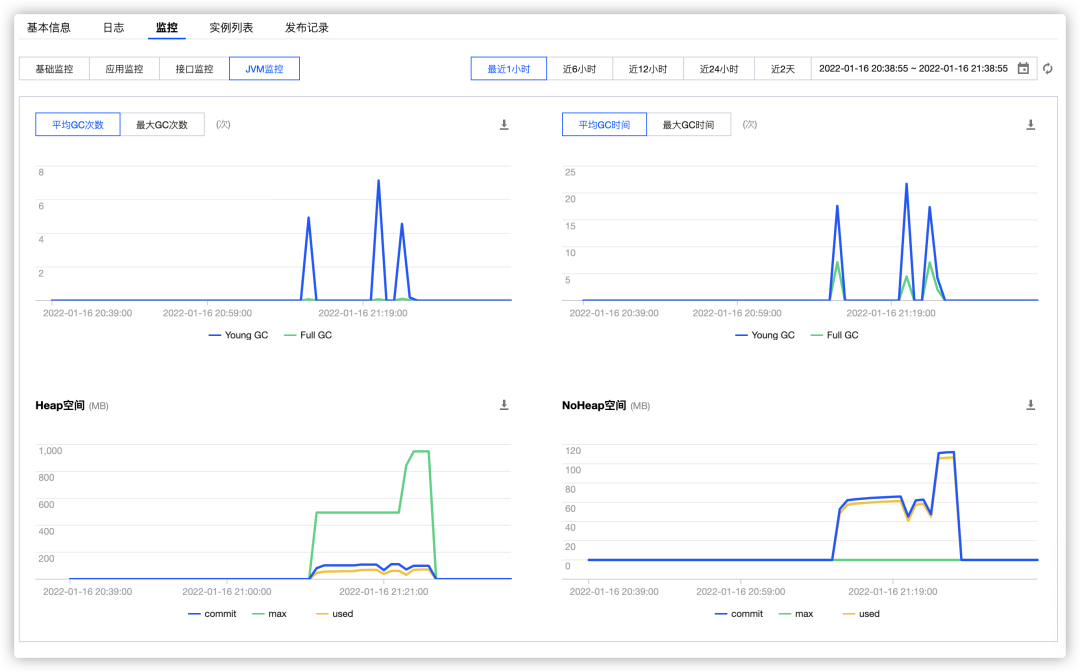
应用JVM监控
极致弹性
TEM默认提供使用率较高的定时弹性策略和基于资源的弹性策略,为您的应用提供秒级的弹性性能,帮助您应对流量洪峰,并能在实例闲置时及时节省资源。
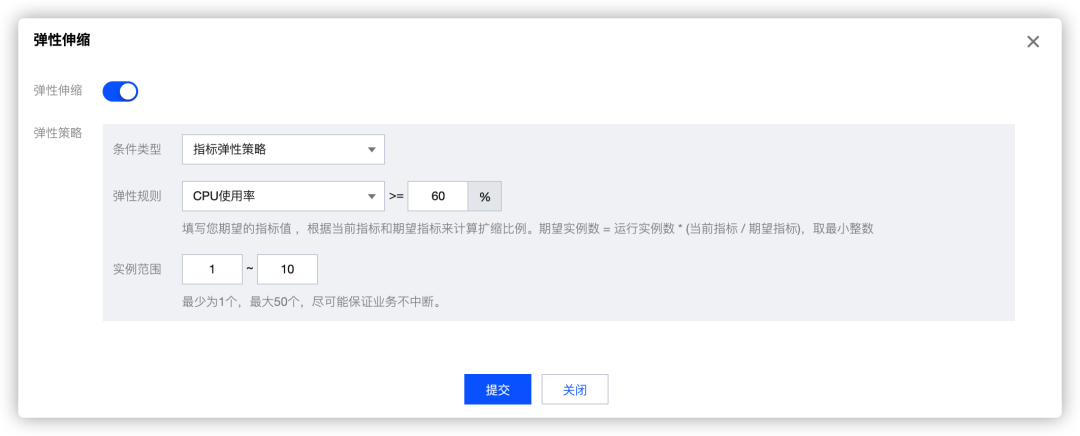
指标弹性策略
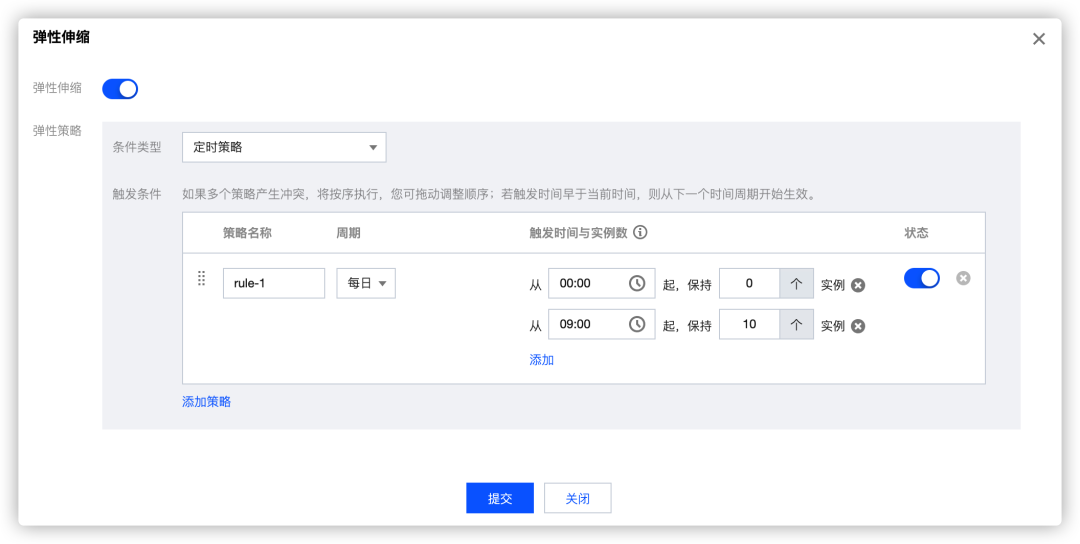
定时弹性策略
总结
工欲善其事,必先利其器。在步入云原生时代的今天,如何让您的Java应用的部署效率和运行性能最大化,这对所有开发者都是一个挑战。而TEM作为一款面向微服务应用的Serverless PaaS平台,将成为您手中的“云端利器”,TEM将致力于为企业和开发者服务,帮助您的业务以最快速、便捷、省心的姿态,无忧上云,享受云原生时代的便利。
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈