
AI算法工程师的笔记本环境配置
前一阵子买了个新的笔记本电脑,幻13-3050TI-1T版本,全能本,CPU是8核心16线程的标压版AMD锐龙9-5900HS,显卡是NVIDIA-3050TI,重量和macbook差不多,都是1.4kg,便携、可以改变形态。
大概长这样:

可以变换3种形态(莫名有种兴奋感),可能也有人问我为啥不买macbook,没买的原因有两点:
macbook不支持nvidia显卡,这个无解,没办法本地跑AI代码,只能远程服务器 macbook用腻了,有一点审美疲劳,新版的macbook pro也太厚了,感觉不方便携带,主要也贵...
于是有了一台和macbook接近大小、差不多重量的带独显的全能笔记本,日常简单开发、调试调试足够用了。CPU是R9-5900HS、显卡是3050TI-4G,CPU的编译速度也还可以,GPU的话除了显存有点小,30系列的特性都有了,可以尽情尝试。

毕竟搞AI的,当然对GPU比较敏感,这个3050TI是基于GA107核心,有2560个CUDA Core,80个Tensor Core,基本是够玩了。计算能力8.6,目前(这句话写的时候还是最新,但是立马老黄3月份推出了H100)最新的特性该有的都有:
FP32、FP16、BF16和INT8精度的支持 第三代Tensor Core等等
附一个GA102的白皮书[1],感兴趣的可以翻翻。
有了笔记本,接下来就是配置开发环境了。
之前不想用Windows本主要是习惯了Linux的操作环境,而Mac和Linux操作起来相差不大,而用windows就会种种不习惯。
所以一开始的方案就是win10+ubuntu双系统:
Ubuntu + win10/win11 双系统方案
这也是大部分程序员的配置,开发当然必须是ubuntu了,windows娱乐,ubuntu工作。

这里我先是在win10下安装了ubuntu,之后在win10+ubuntu双系统的前提下,将win10升级成了win11。整个升级过程很顺滑,升级后没有任何改动(引导没有被破坏、ubuntu系统未被破坏)升级完重启后,可以正常使用ubuntu,此时双系统升级为win11+ubuntu。
而装Ubuntu也是老生常谈的话题了,基本都是:
下载好Ubuntu镜像,拿个U盘制作U盘镜像 Win10系统内划分出一部分磁盘给Ubuntu使用 重启bios设置启动方式为U盘然后安装
我安装的是20.04版本的Ubuntu。
大概就是这么个流程,网上的资料很多很多,随便一搜就有了,有一点和之前安装16.04不一样,NVIDIA的驱动安装比想象中要顺利很多,四年前那会也在一个笔记本上装Ubuntu吃了不少苦头:ubuntu16.04下安装NVIDIA(cuda)-gtx965m相关步骤以及问题[2],这次的NVIDIA驱动没有很多坑,安装正常逻辑安装就行,也不需要禁用什么什么的。
进入新的Ubuntu系统,基本步骤大体也都一样:
先切换源,注意源的版本一定和你的ubuntu版本一致(不一致会导致你的各种软件不兼容,也就是unmet会很多,这个我一开始没有注意,折腾了很久),去找清华或者阿里源:
https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/ https://developer.aliyun.com/mirror/ubuntu?spm=a2c6h.13651102.0.0.3d151b117MRP65
然后把/etc/apt中的source.list替换成国内源之后:
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install build-essential
安装Ubuntu的必要组件之后,接下来就是要升级内核(Ubuntu-20.04默认是5.10的内核)。至于为啥要升级内核,是因为我这个是幻13是比较新的笔记本,有些功能旧版的内核不支持(比如翻转屏幕、比如键盘灯、指纹解锁啥的),于是乎先升级内核。
升级内核有一些坑,我参照了ROG幻13安装ubuntu20.04,解决各种驱动问题[3]这篇文章,也确实帮了我大忙,大概就是,如果你从官方kernel[4]中去下载更新,可能会因为官方kernel中的libc6版本不兼容导致sudo apt-get update有时候会出错,会报各种问题,需要下载合适版本的kernel才行。
对内核有疑问的可以看看这篇文章,总之升级内核需要谨慎一些,另外使用最新版本的Ubuntu系统,会自带最新的内核。
接下来说说WSL2。
win11+wsl2+docker
WSL(Windows Subsystem for Linux)是我在调研win11相关资料时候看到的新名词,之前只是听说过,但没有实际使用过,现在有windows跑Ubuntu的需求,突然想到可以试试看。
wsl的功能就是可以让你在windows上使用linux系统。可以让我这种习惯命令行的人在windows下开发也不难受。毕竟如果直接在ubuntu下开发,摸鱼和聊天确实比较折腾,我还是想实现类似于macos上开发的效果,娱乐工作两不误,开发体验也不割裂。
因为mac和nvidia水火不容,对于我这种搞深度学习极度依赖nvidia显卡的人来说用mac只能远程连接服务器来开发,在网络不好的情况下就比较难受了。
貌似WSL2也比VMware虚拟机性能强一些(懂得小伙伴可以说下),也可以直接在windows中运行Ubuntu镜像,然后vscode连接开发,效率直接翻倍,这点直接抓住了我的心。
目前wsl的最新版是wsl2,wsl和wsl2的区别挺大,男人的第六感让我用新不用旧,于是选择使用wsl2,其实还有一个原因是wsl2下的linux内核可以调用cuda。
首先升级win11,再装一个WSL专用驱动510.06_gameready_win11_win10-dch_64bit_international,然后直接在win终端输入:
wsl --set-default-version 2
此时就默认使用WSl2了。
如果着急看WSL2能不能用可以直接在WIN跑下这个:
docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
---
result:
---
GPU Device 0: "Ampere" with compute capability 8.6
> Compute 8.6 CUDA device: [NVIDIA GeForce RTX 3050 Ti Laptop GPU]
20480 bodies, total time for 10 iterations: 40.139 ms
= 104.495 billion interactions per second
= 2089.903 single-precision GFLOP/s at 20 flops per interaction
输出正常的话,就证明WSL-NVIDIA驱动和你的显卡都能正确检测到。
安装Ubuntu
接下来安装Ubuntu试试,一般网上都是建议在Microsoft Store中搜索安装,不过如果直接在WIN11的商店中搜索Ubuntu,会给你直接安装到C盘,这点很烦,我也是一不小心就将Ubuntu镜像搞到了C盘,无奈只能先删掉,然后将WSL2中的docker绑定解绑,然后移到其他盘中(这里我移动到了D盘):
wsl --export docker-desktop-data D:\Docker\wsl\docker-desktop-data\docker-desktop-data.tar
wsl --unregister docker-desktop-data
wsl --import docker-desktop-data D:\Docker\wsl\docker-desktop-data\ D:\Docker\wsl\docker-desktop-data\docker-desktop-data.tar --version 2
docker镜像地址移到其他盘后,就可以放开手搞镜像了!
基于wsl2的docker镜像
既然都是镜像,为啥不直接找一个带有cuda环境的镜像呢,直接在docker官网或者NVIDIA-docker[5]就可以搜到:nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04,然后docker拉一下就行
于是,我在wsl2中注销掉了之前的Ubuntu镜像,wsl --unregister Ubuntu,并且删除之前的镜像。然后docker pull nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04拉取新的镜像。
运行一下试试,执行docker run -it --gpus all 42a32a65aa9d /usr/bin/bash,注意要把--gpus all加上,不然会检测不到显卡。
进入容器内部执行nvidia-smi:
root@304af4811a38:/# nvidia-smi
Sun Jan 30 10:37:28 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.39.01 Driver Version: 511.23 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A |
| N/A 51C P8 8W / N/A | 0MiB / 4096MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
嗯,没毛病。
测试CUDA
编译https://github.com/NVIDIA/cuda-samples中的代码,然后跑个deviceQuery:
root@0b09ee5e9284:~/code/cuda-samples/bin/x86_64/linux/release# ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce RTX 3050 Ti Laptop GPU"
CUDA Driver Version / Runtime Version 11.6 / 11.4
CUDA Capability Major/Minor version number: 8.6
Total amount of global memory: 4096 MBytes (4294443008 bytes)
(020) Multiprocessors, (128) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1035 MHz (1.03 GHz)
Memory Clock rate: 5501 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 102400 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.6, CUDA Runtime Version = 11.4, NumDevs = 1
Result = PASS
可以正常检测出卡,也可以正常运行。
再跑一个简单的矩阵乘法:
root@0b09ee5e9284:~/code/cuda-samples/bin/x86_64/linux/release# ./matrixMul
[Matrix Multiply Using CUDA] - Starting...
GPU Device 0: "Ampere" with compute capability 8.6
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
done
Performance= 294.72 GFlop/s, Time= 0.445 msec, Size= 131072000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
嗯,也没毛病。
编译tvm测试
简单在WSL2下和在双系统Ubuntu下进行编译TVM测试,tvm版本用GITHUB上779dc51e1332f417fa4c304b595ce76891dfc33a这个commit进行测试,win端调整到rog的性能模式,Ubuntu系统没有额外设置,cmake的设置相同,都使用ninja j8命令进行编译。
WSL2和Ubuntu编译TVM差30s,将近2%吧,相差不是很大。其实这个对比不是很标准哈,两个系统的CPU最高频率没有统一,只是简单测测吧~
搭配VSCODE
使用VSCODE开发已经是很稀松平常的事儿了,VSCODE有个remote-SSH插件可以让我们很方便地连接远程服务器进行开发,就和本地服务一样。
同样的,VSCODE中也有一个插件直接可以连接WSL2下的docker,在windows下docekr run之后,就可以在win下的vscode中找到这个docker容器:
执行Attach Vscode之后就可以进入VSCODE的docker环境:

开发就和在Ubuntu下的VSCODE一模一样,有root权限,可以装插件,可以调试代码,想干啥就干啥。
到目前为止WSL2在WIN11上的开发一切顺利~
WIN11到底好不好用
刚拿到这个笔记本时是WIN10,也没有升级WIN11的想法,不过因为在win10中使用WSL2比较麻烦,而WIN11自带wsl2。于是乎就升级了一波WIN11。
整个升级过程比想象中顺滑,在设置里头点点点就可以直接升级,下载更新、重启一气呵成,重启后就是新系统了,之前的所有软件都能用。
据说WIN11相比WIN10在CPU调度会差一点,打游戏会比较影响。不过我感觉不出来,使用上比WIN10界面好看些,其他核心操作和WIN10相差不大,对于触屏用户更友好些。
令我比较惊喜的是WIN11自带了类似MAC端付费应用Paste的核心功能,Win+V可以直接展示最近的剪切板随便选择粘贴,图片也是可以的。
遇到的问题
有一个比较坑的问题,本来win11+Ubuntu20.04双系统用的好好的,突然有一天华硕让升级bios(从407->408),当时没有什么想法就直接升级了。升级完直接傻眼,发现进不去ubuntu系统了,而win11系统没啥问题。
以为是引导的问题,修改了半天grub引导,通过u盘ubuntu安装器fix-boot后也不行,试了种种方式都进不去,差点就要重装了。
最后偶然在reddit上查了下貌似是408版本不兼容ubuntu-20.04,直接降级bios就好了。
相关问题链接:
https://www.reddit.com/r/FlowX13/comments/sskb3q/updating_bios_seems_to_have_broken_my_ubuntu/
华硕bios下载官网:
https://www.asus.com/supportonly/ROG%20Flow%20X13%20GV301/HelpDesk_BIOS/!
使用lldb
用clang编译后的文件想要在VSCODE中debug,需要下一个codeLLDB,然后json中配置:
{
"type": "lldb",
"request": "launch",
"name": "lldb launch",
"program": "/path/to/a.out",
},
就可以了~
3080拓展坞
因为幻13可以通过专用的PCIE拓展口连接自己的拓展坞显卡,传输速率比雷电4要快不少,外接显卡几乎可以无损。于是在日亚上淘了个3080的显卡坞,7300+800的税,等了一个月终于到了。

首先这不是真正的桌面版RTX3080。这是rtx3070桌面版ga104核心的满血版。多了一些cuda核心而已。因为功耗限制,实际上比桌面版3070还要慢,也就是略弱于桌面端3070。不过我买这个主要是看重其16G的显存,真的很适合炼丹啊~

看大石头的评测,这个3080显卡坞在和幻13极限双烤开增强模式,GPU可以跑到150w温度82度,CPU可以跑到45W温度95度,说实话这温度有点高,如果自己平时使用的话还是建议调低点,毕竟这玩意儿比较娇贵。
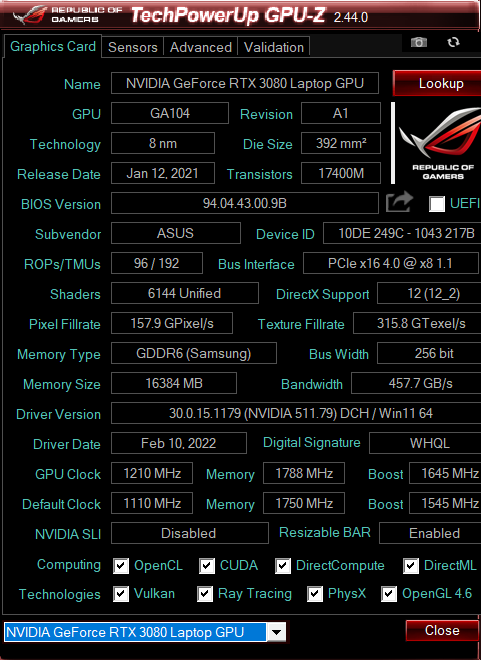
有一点肯定要清楚,这显卡的性能和功耗是成正比的,不管是桌面级、笔记本还是嵌入式的显卡,都是功耗越强性能越强。
另外,在WIN11端切换3080显卡之后,重启成Ubuntu直接就识别为3080了,爽。
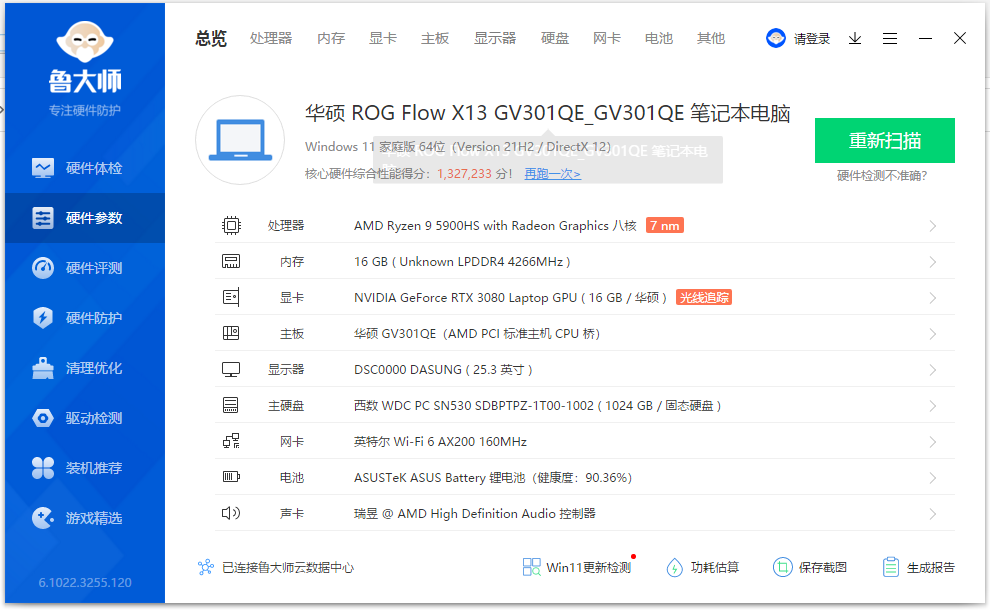
桌面配置
借着这次唠叨,顺便说下咱们不常见的屏幕挂灯,一开始想到用挂灯的场景是墨水屏,因为墨水屏不会发光,在白天还好,但是晚上就没法用了,虽然可以使用台灯照着,但是光不均匀或者说照不全,比如这样:
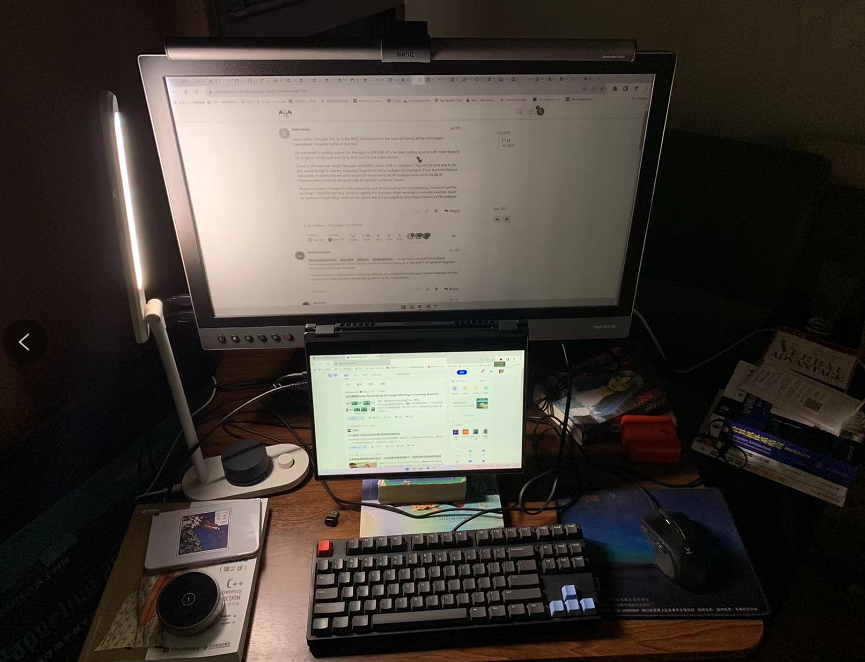
上面就是仅使用台灯的样子,上面的屏幕挂灯还没有开,这样办公太难受了。
如果开了屏幕挂灯的话:
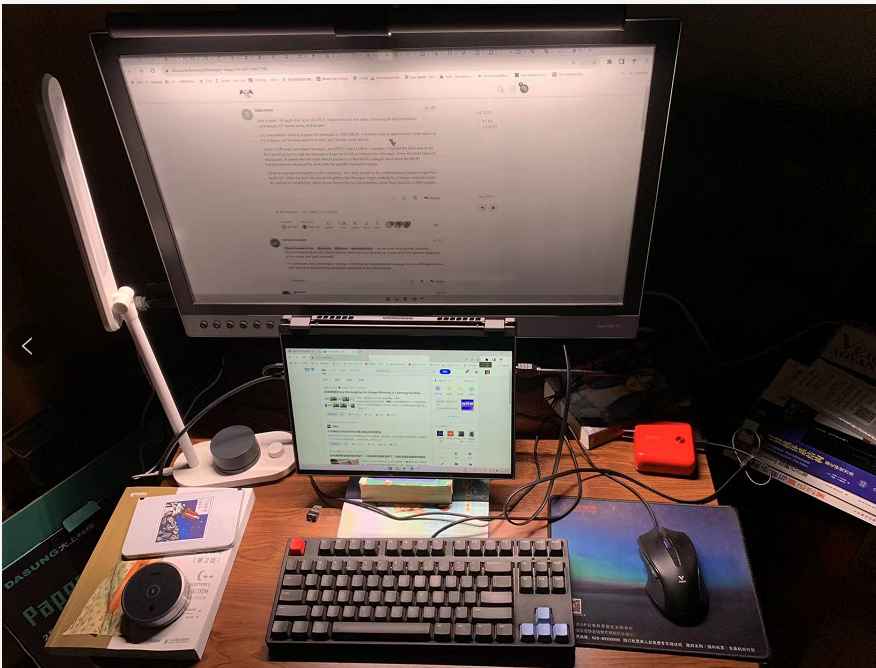
可以看到墨水屏被照亮了很多...另外桌面也照亮了,台灯关了也无所谓,只有挂灯,看书没有任何问题。
这个灯是明基的Screenbar Halo,话说都配这么贵的墨水屏显示器了,不差一个挂灯了,之前用的小米的,感觉亮度有点不够,索性就配了个比较好的挂灯了。相比小米肯定高级很多哈,亮度提升了不少,最高亮度需要大电流的输出才行(1A有点勉强,1.5A-2A差不多),之前的小米就不用(因为没有那么亮),我挂了个充电宝就没任何问题了。
不过说实话貌似屏幕挂灯不是这么用的,人家是为了给你个环境光,照亮桌面,可以看书又不占地方,关键的是这个灯是非对称的(咱也不懂),就是不会照到普通的屏幕上给你反光(普通的屏幕是会发光的,和我这个墨水屏还不一样),但其实我是想让这个挂灯照到我的屏幕上的(因为墨水屏不发光嘛),但是我正常使用挂灯(明基这个)就照不到屏幕,这个确实不错,毕竟屏幕挂灯本应该不照屏幕以防反光。然后我只能强行调整一下挂灯的方向,让它尽量照我的屏幕,感觉有点为难人家。
我也拿普通屏幕试了试:
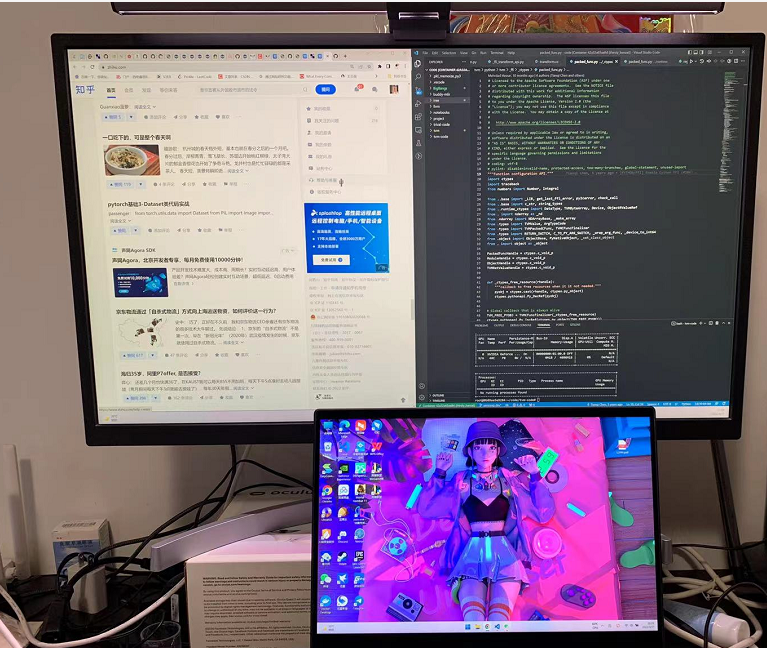
无论是上面的还是下面的屏幕都不反光,看的很清楚,简直太棒了~看代码打游戏啥的没有任何问题,感觉普通屏幕,使用挂灯,让周围环境光充足起来,这样眼睛就不会太容易疲劳了。
毕竟算是生产力了,屏幕挂灯用了就不会回去了。
这篇就讲这么多吧,下一篇就还是大家熟悉的技术文了~
参考资料
https://docs.nvidia.com/cuda/wsl-user-guide/index.html https://zhuanlan.zhihu.com/p/455979556 https://www.codetd.com/fr/article/13628610 https://developer.nvidia.com/blog/leveling-up-cuda-performance-on-wsl2-with-new-enhancements/ https://l-zb.com/?id=49#
参考资料
白皮书: https://images.nvidia.cn/aem-dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf
[2]ubuntu16.04下安装NVIDIA(cuda)-gtx965m相关步骤以及问题: https://oldpan.me/archives/ubuntu16-04-nvidia-cuda-gtx965m
[3]ROG幻13安装ubuntu20.04,解决各种驱动问题: https://zhuanlan.zhihu.com/p/455979556
[4]官方kernel: https://www.kernel.org/
[5]NVIDIA-docker: https://github.com/NVIDIA/nvidia-docker
整理不易,点赞三连↓