
Kafka常见问题&学习路径&源码阅读小结 | 写在Kafka3.0发布之际
严格来说,这篇文章也不是今天写的。是之前断断续续写在了几篇文章中。
2021年9月21日,随着Kafka3.0的发布,Kafka在「分布式流处理平台」这个目标上的努力进一步得到加强!Kafka不满足于「消息引擎」的定位,正式基于这样的定位,Kafka 社区于 0.10.0.0 版本正式推出了流处理组件 Kafka Streams,也正是从这个版本开始,Kafka 正式"变身"为分布式的流处理平台,而不仅仅是消息引擎系统了。
Kafka不仅是消息引擎系统,也是分布式流处理平台。
在某些场景,可以弃用Flink、Spark这样的计算引擎。借助Kafka Stream轻松实现数据处理。
那么我们在学习Kafka的时候应该从哪些方面入手?
我们在学习Kafka的时候,到底在学习什么?
我在这篇《我们在学习Kafka的时候,到底在学习什么?》这篇文章中总结了整体学习Kafka的方法和路径。
分别从背景、核心概念、核心原理、源码阅读、实际应用等。方面详细的讲解了学习路径和方法。各位读者需要根据自己的实际情况针对性的去学习其中的某一个部分。
这部分特别强调了一下Kafka Stream这个模块。正是Kafka Stream的出现使得Kafka的定位从原来的分布式、分区、有备份的提交日志服务变成了完整的分布式消息引擎和流式计算处理引擎。
Kafka源码阅读的一些小提示
如果你整体上对Kafka有一定的了解,并且简单的应用过Kafka。那么就有一个不可忽视的环节:源码阅读。
Kafka的代码总量有50多万行,我们不太可能通盘阅读,只需要阅读其中的重要部分即可。在《Kafka源码阅读的一些小提示》中,参考网上的资料和自己阅读过的部分源码,给出了一个比较完全的源码阅读大纲。
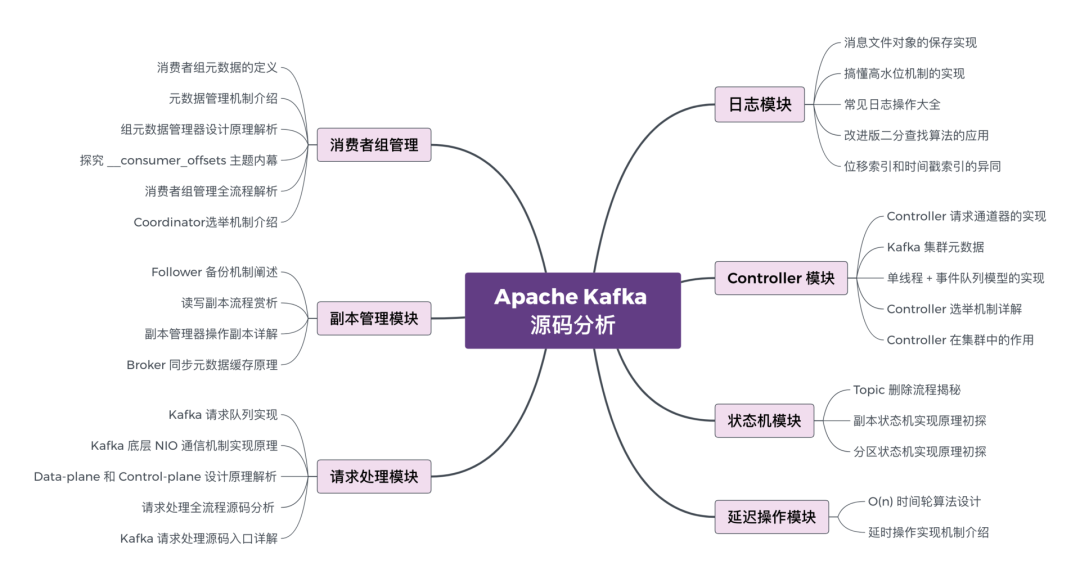
供大家参考。
Kafka常见错误小集合
最后这个部分,是一些常见的错误合集。供大家参考:
Kafka3.0来袭
最后这个部分,是Kafka3.0中的一些重要更新。
Apache Kafka 3.0是一个涉及多方面的大版本,该版本引入了各种新功能、突破性的API更改以及对KRaft的改进——Apache Kafka的内置共识机制将取代Apache ZooKeeper。
虽然KRaft尚未被推荐用于生产(已知差距列表),但我们对KRaft元数据和API进行了许多改进。Exactly-once和分区重新分配支持值得强调。我们鼓励您查看KRaft的新功能并在开发环境中试用它。
从Apache Kafka 3.0开始,生产者默认启用最强的交付保证 (acks=all, enable.idempotence=true)。这意味着用户现在默认获得排序和持久性。
Kafka Connect任务重启增强、KStreams基于时间戳同步的改进以及 MirrorMaker2更灵活的配置选项。
此外,Kafka3.0中弃用了Java8的支持,需要大家升级JDK版本。
更多的详细信息可以网上搜搜。
 八千里路云和月 | 从零到大数据专家学习路径指南 我们在学习Flink的时候,到底在学习什么? 193篇文章暴揍Flink,这个合集你需要关注一下 Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点 我们在学习Spark的时候,到底在学习什么? 在所有Spark模块中,我愿称SparkSQL为最强! 硬刚Hive | 4万字基础调优面试小总结 数据治理方法论和实践小百科全书 标签体系下的用户画像建设小指南 4万字长文 | ClickHouse基础&实践&调优全视角解析 【面试&个人成长】2021年过半,社招和校招的经验之谈 大数据方向另一个十年开启 |《硬刚系列》第一版完结 我写过的关于成长/面试/职场进阶的文章 当我们在学习Hive的时候在学习什么?「硬刚Hive续集」
八千里路云和月 | 从零到大数据专家学习路径指南 我们在学习Flink的时候,到底在学习什么? 193篇文章暴揍Flink,这个合集你需要关注一下 Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点 我们在学习Spark的时候,到底在学习什么? 在所有Spark模块中,我愿称SparkSQL为最强! 硬刚Hive | 4万字基础调优面试小总结 数据治理方法论和实践小百科全书 标签体系下的用户画像建设小指南 4万字长文 | ClickHouse基础&实践&调优全视角解析 【面试&个人成长】2021年过半,社招和校招的经验之谈 大数据方向另一个十年开启 |《硬刚系列》第一版完结 我写过的关于成长/面试/职场进阶的文章 当我们在学习Hive的时候在学习什么?「硬刚Hive续集」你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构&、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。