
基础学习 | 重参数新方法,ACNet的升级版DBB
1、开篇小记
知识点1:
并行多分支结构提取的特征具有更强的表征性;
具体可以回忆参考DenseNet、VOVNet、Res2Net以及PeleeNet(后续均会有解读)。
知识点2:
并行多分支结构会带来更大别的计算开销;
具体可以参考CSPNet对此的分析。
知识点3:
使用 1×3 conv + 3×1 conv + 3×3 conv 代替原本一个的 3×3 conv的ACNet重参方法是有效的;
具体可以参考ACNet的分析。
知识点4:重参有没有更好的呢?
答:有,DBB可以说就是ACNet v2,全面升级!
2、DBB 简述
Diverse Branch Block是继ACNet的又一次对网络结构重参数化的探索,即ACNet v2,DBB设计了一个类似Inception的模块,以多分支的结构丰富卷积块的特征空间,各分支结构包括平均池化,多尺度卷积等。最后在推理阶段前,把多分支结构中进行重参数化,融合成一个主分支。加快推理速度的同时,顺带提升一下精度!
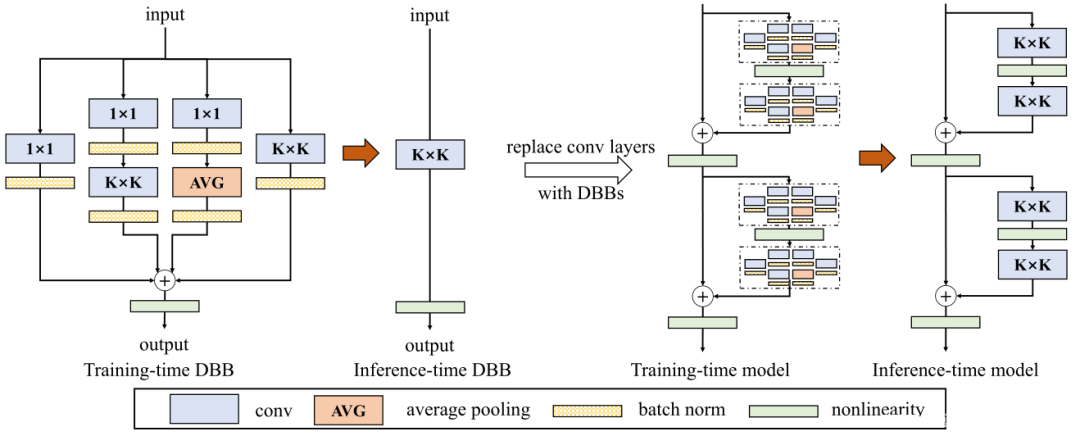
上图给出了设计的DBB结构示意图。类似Inception,它采用1×1、1×1−K×K、1×1−AVG等组合方式对原始K×K卷积进行增强。对于1×1−K×K分支,设置中间通道数等于输入通道数并将1×1卷积初始化为Identity矩阵;其他分支则采用常规方式初始化。
此外,在每个卷积后都添加BN层用于提供训练时的非线性,这对于性能提升很有必要。
3、DBB的实现
以下是 DBB 的Pytorch实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
from dbb_transforms import *
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
padding_mode='zeros'):
conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups,
bias=False, padding_mode=padding_mode)
bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True)
se = nn.Sequential()
se.add_module('conv', conv_layer)
se.add_module('bn', bn_layer)
return se
class IdentityBasedConv1x1(nn.Conv2d):
def __init__(self, channels, groups=1):
super(IdentityBasedConv1x1, self).__init__(in_channels=channels,
out_channels=channels,
kernel_size=1,
stride=1,
padding=0,
groups=groups,
bias=False)
assert channels % groups == 0
input_dim = channels // groups
id_value = np.zeros((channels, input_dim, 1, 1))
for i in range(channels):
id_value[i, i % input_dim, 0, 0] = 1
self.id_tensor = torch.from_numpy(id_value).type_as(self.weight)
nn.init.zeros_(self.weight)
def forward(self, input):
kernel = self.weight + self.id_tensor.to(self.weight.device)
result = F.conv2d(input,
kernel,
None,
stride=1,
padding=0,
dilation=self.dilation,
groups=self.groups)
return result
def get_actual_kernel(self):
return self.weight + self.id_tensor.to(self.weight.device)
class BNAndPadLayer(nn.Module):
def __init__(self,
pad_pixels,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True):
super(BNAndPadLayer, self).__init__()
self.bn = nn.BatchNorm2d(num_features,
eps,
momentum,
affine,
track_running_stats)
self.pad_pixels = pad_pixels
def forward(self, input):
output = self.bn(input)
if self.pad_pixels > 0:
if self.bn.affine:
pad_values = self.bn.bias.detach() - self.bn.running_mean * self.bn.weight.detach() / torch.sqrt(
self.bn.running_var + self.bn.eps)
else:
pad_values = - self.bn.running_mean / torch.sqrt(self.bn.running_var + self.bn.eps)
output = F.pad(output, [self.pad_pixels] * 4)
pad_values = pad_values.view(1, -1, 1, 1)
output[:, :, 0:self.pad_pixels, :] = pad_values
output[:, :, -self.pad_pixels:, :] = pad_values
output[:, :, :, 0:self.pad_pixels] = pad_values
output[:, :, :, -self.pad_pixels:] = pad_values
return output
@property
def weight(self):
return self.bn.weight
@property
def bias(self):
return self.bn.bias
@property
def running_mean(self):
return self.bn.running_mean
@property
def running_var(self):
return self.bn.running_var
@property
def eps(self):
return self.bn.eps
class DiverseBranchBlock(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
internal_channels_1x1_3x3=None,
deploy=False,
nonlinear=None,
single_init=False):
super(DiverseBranchBlock, self).__init__()
self.deploy = deploy
if nonlinear is None:
self.nonlinear = nn.Identity()
else:
self.nonlinear = nonlinear
self.kernel_size = kernel_size
self.out_channels = out_channels
self.groups = groups
assert padding == kernel_size // 2
if deploy:
self.dbb_reparam = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=True)
else:
self.dbb_origin = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups)
self.dbb_avg = nn.Sequential()
if groups < out_channels:
self.dbb_avg.add_module('conv',
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=groups,
bias=False))
self.dbb_avg.add_module('bn',
BNAndPadLayer(pad_pixels=padding,
num_features=out_channels))
self.dbb_avg.add_module('avg',
nn.AvgPool2d(kernel_size=kernel_size,
stride=stride,
padding=0))
self.dbb_1x1 = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=stride,
padding=0,
groups=groups)
else:
self.dbb_avg.add_module('avg',
nn.AvgPool2d(kernel_size=kernel_size,
stride=stride,
padding=padding))
self.dbb_avg.add_module('avgbn',
nn.BatchNorm2d(out_channels))
if internal_channels_1x1_3x3 is None:
# For mobilenet, it is better to have 2X internal channels
internal_channels_1x1_3x3 = in_channels if groups < out_channels else 2 * in_channels
self.dbb_1x1_kxk = nn.Sequential()
if internal_channels_1x1_3x3 == in_channels:
self.dbb_1x1_kxk.add_module('idconv1',
IdentityBasedConv1x1(channels=in_channels, groups=groups))
else:
self.dbb_1x1_kxk.add_module('conv1',
nn.Conv2d(in_channels=in_channels,
out_channels=internal_channels_1x1_3x3,
kernel_size=1,
stride=1,
padding=0,
groups=groups,
bias=False))
self.dbb_1x1_kxk.add_module('bn1',
BNAndPadLayer(pad_pixels=padding,
num_features=internal_channels_1x1_3x3,affine=True))
self.dbb_1x1_kxk.add_module('conv2',
nn.Conv2d(in_channels=internal_channels_1x1_3x3,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=0,
groups=groups,
bias=False))
self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))
# The experiments reported in the paper used the default initialization of bn.weight (all as 1).
# But changing the initialization may be useful in some cases.
if single_init:
# Initialize the bn.weight of dbb_origin as 1 and others as 0.
# This is not the default setting.
self.single_init()
def get_equivalent_kernel_bias(self):
k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.weight,
self.dbb_origin.bn)
if hasattr(self, 'dbb_1x1'):
# 按照方式1进行conv+bn的融合
k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight,
self.dbb_1x1.bn)
# 按照方式方式6进行多尺度卷积的合并
k_1x1 = transVI_multiscale(k_1x1,
self.kernel_size)
else:
k_1x1, b_1x1 = 0, 0
if hasattr(self.dbb_1x1_kxk, 'idconv1'):
k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()
else:
k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weight
# 按照方式1进行conv+bn的融合
k_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first,
self.dbb_1x1_kxk.bn1)
# 按照方式1进行conv+bn的融合
k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight,
self.dbb_1x1_kxk.bn2)
# 按照方式3进行1x1卷积与kxk卷积的合并
k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first,
b_1x1_kxk_first,
k_1x1_kxk_second,
b_1x1_kxk_second,
groups=self.groups)
k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups)
# 按照方式1进行conv+bn的融合
k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg.to(self.dbb_avg.avgbn.weight.device),
self.dbb_avg.avgbn)
if hasattr(self.dbb_avg, 'conv'):
# 按照方式1进行conv+bn的融合
k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_avg.conv.weight,
self.dbb_avg.bn)
# 按照方式3进行1x1卷积与kxk卷积的合并
k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first,
b_1x1_avg_first,
k_1x1_avg_second,
b_1x1_avg_second,
groups=self.groups)
else:
k_1x1_avg_merged, b_1x1_avg_merged = k_1x1_avg_second, b_1x1_avg_second
# 按照方式2进行分支的合并
return transII_addbranch((k_origin,
k_1x1,
k_1x1_kxk_merged,
k_1x1_avg_merged),
(b_origin,
b_1x1,
b_1x1_kxk_merged,
b_1x1_avg_merged))
def switch_to_deploy(self):
if hasattr(self, 'dbb_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.dbb_reparam = nn.Conv2d(in_channels=self.dbb_origin.conv.in_channels,
out_channels=self.dbb_origin.conv.out_channels,
kernel_size=self.dbb_origin.conv.kernel_size,
stride=self.dbb_origin.conv.stride,
padding=self.dbb_origin.conv.padding,
dilation=self.dbb_origin.conv.dilation,
groups=self.dbb_origin.conv.groups, bias=True)
self.dbb_reparam.weight.data = kernel
self.dbb_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('dbb_origin')
self.__delattr__('dbb_avg')
if hasattr(self, 'dbb_1x1'):
self.__delattr__('dbb_1x1')
self.__delattr__('dbb_1x1_kxk')
def forward(self, inputs):
if hasattr(self, 'dbb_reparam'):
return self.nonlinear(self.dbb_reparam(inputs))
out = self.dbb_origin(inputs)
if hasattr(self, 'dbb_1x1'):
out += self.dbb_1x1(inputs)
out += self.dbb_avg(inputs)
out += self.dbb_1x1_kxk(inputs)
return self.nonlinear(out)
def init_gamma(self, gamma_value):
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight,
gamma_value)
if hasattr(self, "dbb_1x1"):
torch.nn.init.constant_(self.dbb_1x1.bn.weight,
gamma_value)
if hasattr(self, "dbb_avg"):
torch.nn.init.constant_(self.dbb_avg.avgbn.weight,
gamma_value)
if hasattr(self, "dbb_1x1_kxk"):
torch.nn.init.constant_(self.dbb_1x1_kxk.bn2.weight,
gamma_value)
def single_init(self):
self.init_gamma(0.0)
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight, 1.0)
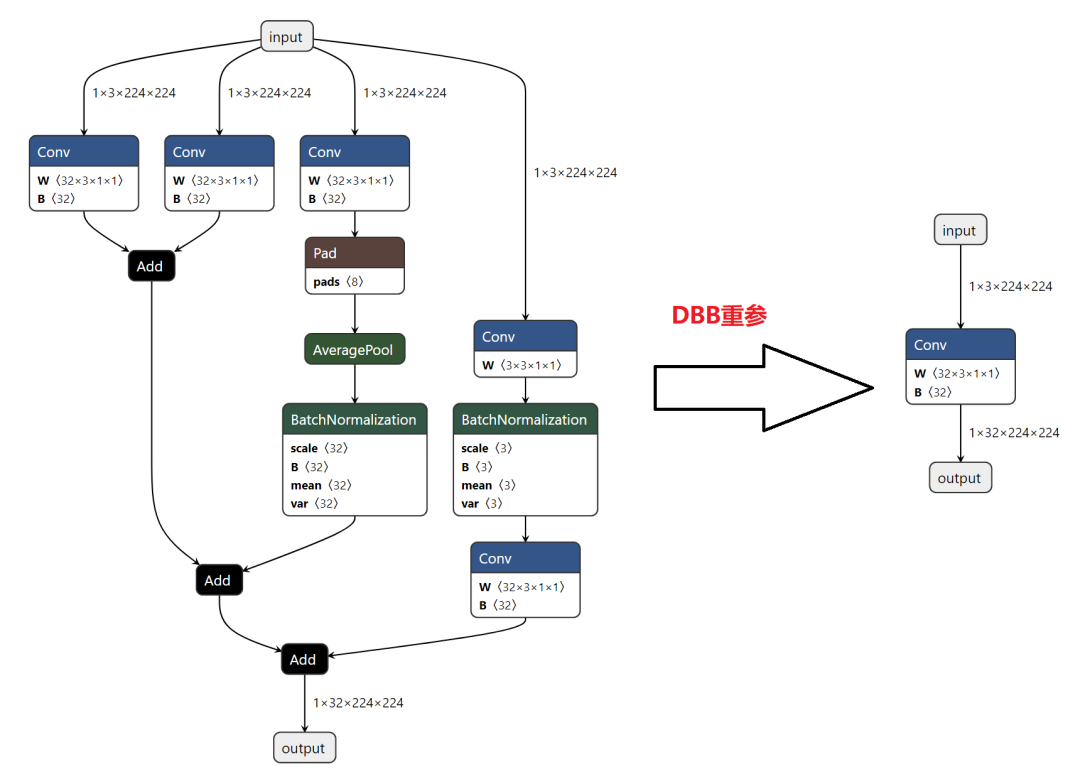
话不多说,直接对比ONNX的输出,就问你香不香!!!
4、参考
[1].https://github.com/DingXiaoH/DiverseBranchBlock/blob/main/diversebranchblock.py
5、推荐阅读
评论