英伟达CPU面世!基于Arm,性能超过英特尔为核心的自家系统10倍,连客户都找好了

大数据文摘出品
作者:Caleb
是的,那个男人又“下厨房”了!
就在今天凌晨,黄仁勋黄教主又在自家厨房发表了NVIDIA GPU技术大会演讲。
这次的演讲和之前有所不同,可以从下图明显看到,黄教主的脸逐渐圆润、头发也越留越长了。

咳咳跑题了……
在以400亿美元收购Arm的6个月后,这次的大会上,英伟达宣布推出三款基于Arm IP打造的处理器,即全球首款专为TB级加速计算而设计的CPU NVIDIA Grace、全新BlueField-3 DPU,以及业界首款1000TOPS算力的自动驾驶汽车SoC。
是的,你没有看错,作为全球GPU的绝对霸主,就在苹果M1芯片向英特尔发起挑战的时候,英伟达CPU正式问世。

和苹果一样,英伟达或许是看到了英特尔硬件已经接近当前的极限,想要突破,就只能自己动手打造芯片了。
“最前端的AI数据科学已经将当今的电脑架构推到了极限,处理着数量不可想像的庞大数据量,”黄仁勋如此说,“搭配上GPU与DPU(数据处理器),英伟达的CPU将能提供NVIDIA所需的第三个基础计算芯片,让数据中心能以最先进的AI技术为核心,重心进行架构。英伟达现在是个三芯片公司了”。
黄教主在演讲中说到:“英伟达正在为当今时代的每一位‘达芬奇’推进他们的各项研究工作,包括语言理解、药物研发或量子计算等。英伟达将助力成就他们毕生的事业。”
“我们每年都会发布激动人心的新品。三类芯片,逐年飞跃,一个架构。”黄仁勋说,数据中心路线图包括CPU、GPU和DPU这三类芯片,每个芯片架构历经两年的打磨周期(周期内可能出现转变),一年专注于x86平台,另一年专注于Arm平台。
英伟达CPU来了!“能充分彰显出Arm的强大”
根据黄教主介绍,英伟达首款数据中心CPU取名为Grace,以美国海军少将、计算机编程先驱Grace Hopper的名字命名。
Grace主要是瞄准了AI超级计算和自然语言处理等大规模计算工作。由于它是以Arm核心为基础,因此可预期会比以英特尔Xeon核心为基础的NVIDIA DGX系统更省能源,且与英伟达自家最新的GPU技术更加紧密结合。
具体来说,基于Grace的系统与英伟达GPU紧密结合,性能将比目前最先进的NVIDIA DGX系统(在x86 CPU上运行)高出10倍。

Grace在创新性上,可以总结为以下三点:
内置下一代Arm Neoverse内核,每个CPU能在SPECrate2017_int_base基准测试中单位时间运行超过300个实例;
采用第四代NVIDIA NVLink,从CPU到GPU连接速度超过900GB/s,相当于目前服务器14倍的带宽速度;从CPU到CPU的速度超过600GB/s。
拥有最高的内存带宽,采用的新内存LPDDR5x技术,带宽是LPDDR4的2倍,能源效率提高了10倍,能提供更多计算能力。
目前,绝大多数的数据中心仍将继续使用现有的CPU,而Grace主要将用于计算领域的细分市场。
“Grace能充分彰显出Arm的强大。” 黄仁勋如此总结到。

不仅如此,英伟达已经为Grace找到了至少两个客户。
黄仁勋宣布,瑞士国家超级计算中心(CSCS)将构建的一台名为Alps的超级计算机,其算力可达20Exaflops,以及美国洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory)即将推出的超级计算机,都都将采用Grace。
CPU+GPU+DPU,未来计算的三大支柱
除了备受瞩目的英伟达CPU,英伟达的DPU同样值得关注。
黄教主表示,CPU和GPU,以及负责在数据中心传输和处理数据的数据处理单元(DPU),将共同组成“未来计算的三大支柱”。
英伟达全新BlueField-3 DPU包含220亿个晶体管,采用16个Arm A78 CPU核心、18M IOPs弹性块存储,加密速度是上一代的4倍,并完全向下兼容BlueField-2。
BlueField-2能够卸载相当于30个CPU核的工作负载,而BlueField-3实现了10倍的加速计算性能提升,能够替代300个CPU核,以400Gbps的速率,对网络流量进行保护、卸载和加速。
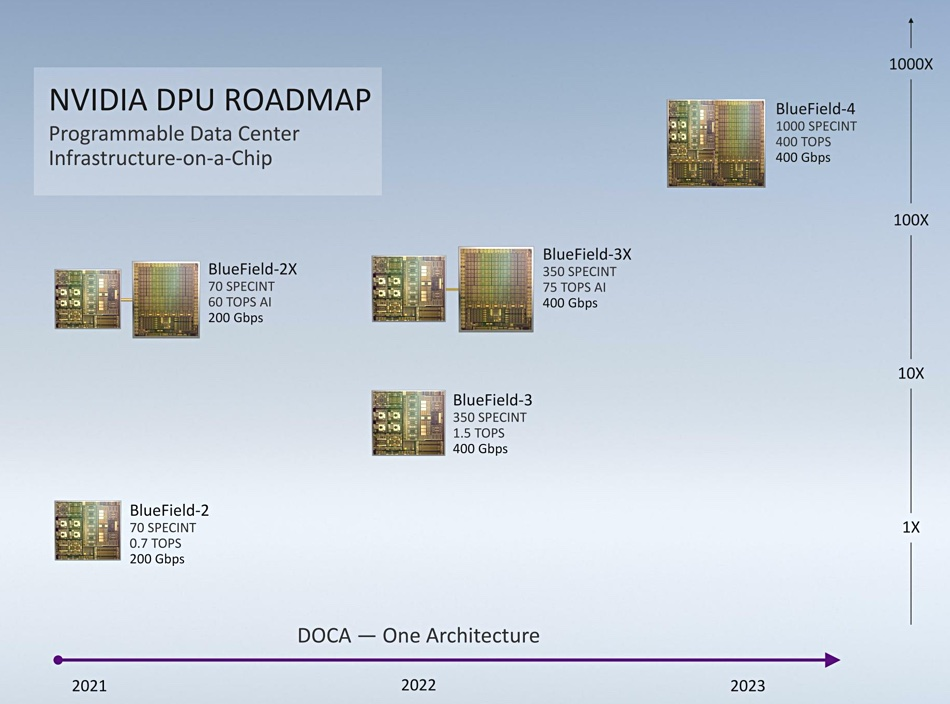
BlueField-3通过NVIDIA DOCA(集数据中心于芯片的架构)软件开发包,为开发者提供了一个完整、开放的软件平台,开发在BlueField DPU上开发软件定义和硬件加速的网络、存储、安全和管理等应用。DOCA已于今日发布并提供下载。
同时该处理器也是首款支持第五代PCIe总线并提供数据中心时间同步加速的DPU。
在自动驾驶方面,英伟达将于2022年投产自动驾驶汽车计算系统级芯片——NVIDIA DRIVE Orin,该芯片旨在成为覆盖自动驾驶和智能车机的汽车中央电脑。
NVIDIA DRIVE Atlan是新一代AI自动驾驶汽车处理器,将采用Grace下一代CPU和下一代安培架构GPU,同时也集成数据处理单元 (DPU),最终其算力将达到1000TOPS,约是上一代Orin处理器的4倍。
“对于汽车而言,更高的算力意味着更加智能化,开发者们也能让产品更快迭代。TOPS就是新的马力。”黄仁勋表示。
除此之外,本次NVIDIA GPU技术大会,黄教主还分享了NVIDIA Megatron的最新进展、发布了NVIDIA Jarvis的新版本、发布了发布了量子计算模拟环境cuQUANTUM,详情可戳官网查看: