
Pandas小技巧,计算数字最大的那个列
群里一个粉丝问了一个问题:

这个问题比较有趣,如果对pandas了解深入的话,一行代码就可以搞定:
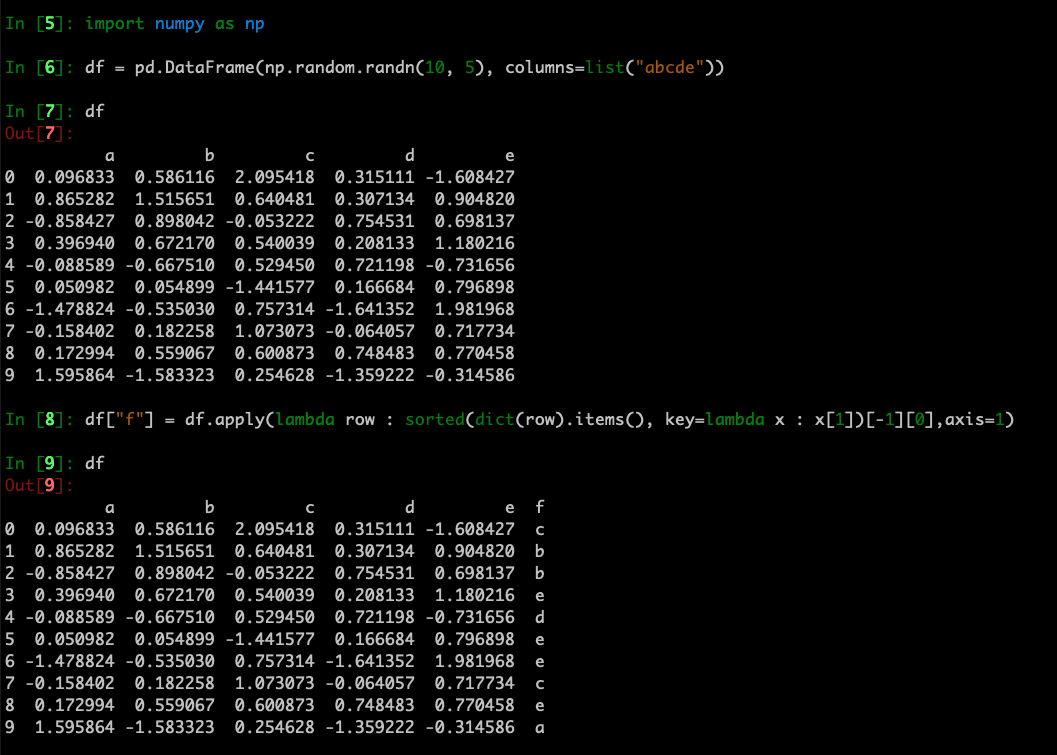
代码粘贴如下:
In [1]: import pandas as pdIn [2]: df = pd.DataFrame({})In [5]: import numpy as npIn [6]: df = pd.DataFrame(np.random.randn(10, 5), columns=list("abcde"))In [7]: dfOut[7]:a b c d e0 0.096833 0.586116 2.095418 0.315111 -1.6084271 0.865282 1.515651 0.640481 0.307134 0.9048202 -0.858427 0.898042 -0.053222 0.754531 0.6981373 0.396940 0.672170 0.540039 0.208133 1.1802164 -0.088589 -0.667510 0.529450 0.721198 -0.7316565 0.050982 0.054899 -1.441577 0.166684 0.7968986 -1.478824 -0.535030 0.757314 -1.641352 1.9819687 -0.158402 0.182258 1.073073 -0.064057 0.7177348 0.172994 0.559067 0.600873 0.748483 0.7704589 1.595864 -1.583323 0.254628 -1.359222 -0.314586In [8]: df["f"] = df.apply(lambda row :sorted(dict(row).items(), key=lambda x : x[1])[-1][0],axis=1)In [9]: dfOut[9]:a b c d e f0 0.096833 0.586116 2.095418 0.315111 -1.608427 c1 0.865282 1.515651 0.640481 0.307134 0.904820 b2 -0.858427 0.898042 -0.053222 0.754531 0.698137 b3 0.396940 0.672170 0.540039 0.208133 1.180216 e4 -0.088589 -0.667510 0.529450 0.721198 -0.731656 d5 0.050982 0.054899 -1.441577 0.166684 0.796898 e6 -1.478824 -0.535030 0.757314 -1.641352 1.981968 e7 -0.158402 0.182258 1.073073 -0.064057 0.717734 c8 0.172994 0.559067 0.600873 0.748483 0.770458 e9 1.595864 -1.583323 0.254628 -1.359222 -0.314586 a
解释一下这个代码:
1、df.apply
df.apply(function, axis=1)这个方式,可以按行遍历df,对每一行使用function函数,这个function的参数是一个series,可以当做字典使用;
2、items
dict(row).items()可以将row这个series变成一个字典。字典的items(),那就是[(key, value), (key, value)]这样的形式,结果形如:[ ('c', 2), ('b', 1), ('a', 3')]
3、sorted
sorted(dict(row).items(), key=lambda x : x[1])这句,我们将字典进行了排序,使用的KEY是每个元素的第二个子元素,即原始字典的value,注意,默认是升序排列,结果形如:[('b', 1), ('c', 2), ('a', 3')]
4、sorted(xx)[-1]
sorted(dict(row).items(), key=lambda x : x[1])[-1]这一句后面加了个[-1],因为是升序排列,所有这里取到了最大的值,例如('a', 123)
5、sorted(xx)[-1][0]
sorted(dict(row).items(), key=lambda x : x[1])[-1][0]这时候,返回了('a', 123)的第0个元素,即列名"a"
这个代码做了比较简化的写法,大家可以思考下。
欢迎关注本公众号,持续分享Python、Pandas小案例
评论