
Pandas数据分析小技巧系列 第四集
三步加星标
你好!我是 zhenguo
今天数据分析小技巧系列第 4 集,前三集在这里:
小技巧 12 dt 访问器求时分(HH:mm)的分钟差
构造如下四行两列的数据,时间格式为:HH:MM
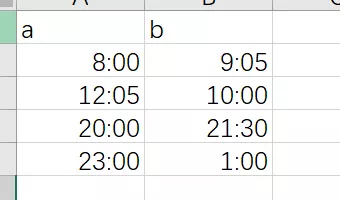
使用pandas读入数据:使用的 pandas 版本为 0.25.1
df = pd.read_excel('test_date_subtract.xlsx')
df
与时间相关,自然第一感觉便是转化为datetime格式,这里需要注意:需要首先将两列转化为 str 类型。
直接使用 astype 转为 str 类型:
df['a'] = df['a'].astype(str)
df['b'] = df['b'].astype(str)
然后转化为 datetime 类型:
df['atime'] = pd.to_datetime(df['a'])
df['btime'] = pd.to_datetime(df['b'])
df
然后使用 dt 访问器转化为分钟数:
df['amins'] = df['atime'].dt.hour * 60 + df['atime'].dt.minute
df['bmins'] = df['btime'].dt.hour * 60 + df['btime'].dt.minute
df
最后求分钟数差值:
df['mins'] = df['amins'] - df['bmins']
小技巧 13 转为 DatetimeIndex 求时分(HH:mm)的分钟差
转化为 DatetimeIndex 类型后,直接获取 hour 和 minute 属性:
atime = pd.DatetimeIndex(df['a'])
btime = pd.DatetimeIndex(df['b'])
df['amins'] = atime.hour * 60 + atime.minute
df['bmins'] = btime.hour * 60 + btime.minute
小技巧 14 split 求时分(HH:mm)的分钟差
split 是更加高效的实现,同样需要先转化为 str 类型:
df['a'] = df['a'].astype(str)
df['b'] = df['b'].astype(str)
其次 split:
df['asplit'] = df['a'].str.split(':')
df['bsplit'] = df['b'].str.split(':')
得到结果如下:

使用 apply 操作每个元素,转化为分钟数:
df['amins'] = df['asplit'].apply(lambda x: int(x[0])*60 + int(x[1]))
df['bmins'] = df['bsplit'].apply(lambda x: int(x[0])*60 + int(x[1]))

小技巧15 100G 数据如何先随机读取1%?
对于动辄就几十或几百个 G 的数据,在读取的这么大数据的时候,我们有没有办法随机选取一小部分数据,然后读入内存,快速了解数据和开展 EDA ?
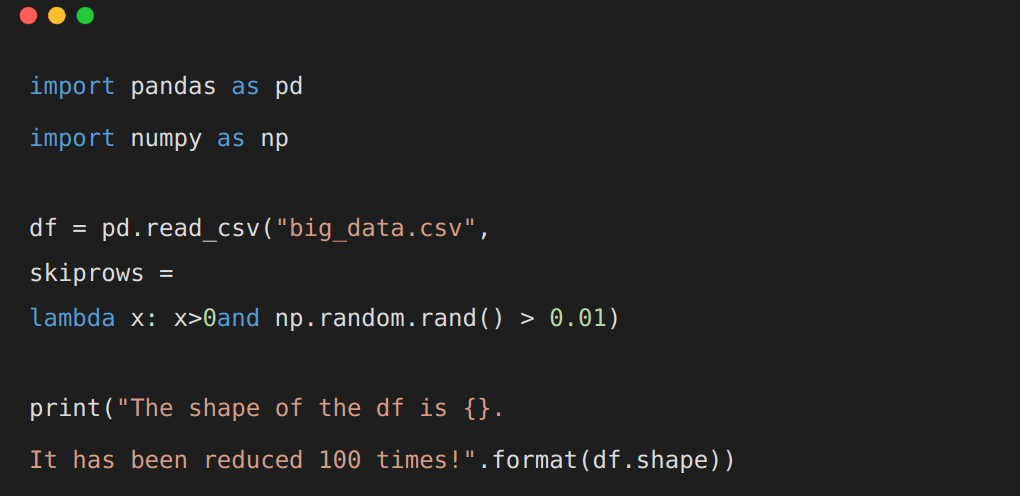
使用 Pandas 的 skiprows 和 概率知识,就能做到。解释具体怎么做,如下所示,读取某 100 G 大小的 big_data.csv 数据
使用 skiprows 参数, x > 0 确保首行读入, np.random.rand() > 0.01 表示 99% 的数据都会被随机过滤掉
言外之意,只有全部数据 1% 才有机会选入内存中。
import pandas as pd
import numpy as np
df = pd.read_csv("big_data.csv",
skiprows =
lambda x: x>0and np.random.rand() > 0.01)
print("The shape of the df is {}.
It has been reduced 100 times!".format(df.shape))
使用这种方法,读取的数据量迅速缩减到原来的 1% ,对于迅速展开数据分析有一定的帮助。
下面是我微信,任何问题都可留言:
评论