
计算机视觉转型大数据开发,分享一下我的学习历程和大厂面经
点击上方 "大数据肌肉猿"关注, 星标一起成长
后台回复【加群】,进入高质量学习交流群

今天分享的是我学校的直系学弟,6月份刚毕业,他从大三的春季实习开始准备,秋招和春招也一边实习,一边不断面试总结,校招拿了科大讯飞、三七互娱、一嗨租车、点触科技等大公司的offer。
大家好,我是锋哥同大学的学弟,二本独立院校计算机专业,2021届应届毕业生,接下来讲讲自己的经历。
我大一刚进入大学没什么想法,大一课程比较少,也不知道做啥,基本上整个大一就荒废了。
大二的时候我进入了学校的实验室。去到实验室我开始学习计算机视觉方向,在各方面都学了些皮毛,通过实验室的平台我也参加了一些比赛,通过比赛经历锻炼了一些自学能力,也开拓了视野。
认识锋哥还得从锋哥的舍友赞哥(学了三年的嵌入式,但我还是转型了大数据,跟你聊聊我学习的心路历程)说起,赞哥是我同实验室的学长,因为知道赞哥是实验室很优秀的一个人,所以我当时就去找赞哥聊天交谈,了解到了Java大数据方向,也关注了锋哥的微信公众号,通过锋哥的微信公众号我看到了很多转型案例和锋哥的自身经历,当时心里很羡慕。
后来大三的寒假,我终于迈出了第一步,开始自学了Java,看慕课网看B站视频。从Java语法基础学起,一直学到Spring全家桶等等框架的应用。从2月初差不多学到4月多,然后我找了网上的简历模板试着写了自己的简历,打算找份实习。
于是我把简历给锋哥看,锋哥为我指出了简历的不足,于是我下定决心跟着锋哥重新学习项目,并且梳理一下技术栈,再去找实习。
差不多从当时的五一假期,我用五天左右把锋哥给的资料过一遍,然后我就开始边投简历边深入学习了,整个五月份基本都是这个状态,最终是六月初确定了实习公司,总共得到十家公司的面试机会,过了三家。
在实习阶段我认真的听完锋哥关于实习的live讲解,积累实习经验,一直做到8月底辞职,然后我开始投简历参加秋招。
秋招的时候,我投递的都是后端开发的岗位。没想到第一个面试的就是腾讯,当时确实还没准备的很充分就直接上了,一面过了,但是二面由于面试官一直未约时间整个流程就灰掉了(横向对比被筛掉了),后来投递的大厂只有美团、哔哩哔哩、蘑菇街给了面试机会。
美团、哔哩哔哩、蘑菇街都是一面挂。这几家我表现的还不错,但是面试官认为我虽然问题都答对了,但是缺乏自己的理解,所以没给过。秋招我也收到了四五个小公司的offer,当时也算是有了保底的offer,薪资都是10k-12k。
秋招给我的教训就是,投递公司要从小公司投递起,先面一些不太意向的公司,先把自己的感觉找到,并且能对自己简历上的项目、技术做到很熟悉,对答如流的程度,才能更好迎接大厂面试。
除此之外,如果一开始你就投递大厂,加上你没有赛码网、牛客网的笔试经验,经常会遇到一些明明能做出来的算法题,但是过不了的情况。
在今年1月底我请锋哥帮助我规划一下春招前的学习路线,准备春招投递大数据岗位开始,我从Hadoop、Spark慢慢学到实时分析和离线数仓的项目,并且把项目写到简历中,有了之前的学习经验,我很快的就把大数据的东西过了一遍。
二月底我就开始投递简历,进行春招的面试了,我从小公司面起,每一次面试都总结面经,然后回过头来复习,然后持续地投简历面试,逐渐的我收获到了挺多中小厂的大数据offer,年薪25w左右。
但是可惜的是我春招依然很多投递的大厂都没得到面试机会,只有面过腾讯、携程、网易雷火。网易雷火一面挂,腾讯携程都是二面挂。
只能说自己在大厂面前确实还是实力不够,虽说机会少,但是自己一直没有把握住。总结我自身经历我总结以下几点希望对大家有所帮助:
1、腾讯校招喜欢问计算机网络、网络安全等知识。
2、大厂面试都有手撕算法、手撕SQL,哪怕这一面没问下一面一定会问,早点开始刷题吧,越早越好。
3、投递简历要先从小公司投递起,海投!不断完善自己的面经知识库和薄弱点,面试前的准备可以参考锋哥星球的“面试前夕”。
4、大三的时候一定要参加春季招聘,因为大三的实习春招相对来说进大厂比较容易,有些大厂有留任机会,哪怕没有留任,在你参加秋招的时候也是一个大杀器。
5、我很后悔没能早点认识锋哥,早点开始学习和实习,希望大家把握当下,不要像我一样荒废了大学最好的时间
6、参加校招时对所有投递的公司都做一个统计,对于自己的面经要做一个系统的记录,逐渐完善。对于自己的实习项目在实习的时候一定要为将来做准备,因为经常会被问到一些结合项目的高并发大数据量、高可用等等的实际场景问题。这里可以参考#安心实习 or 全心秋招 ?(附实习跑路路线及秋招攻略)
7、秋招前的实习要早点开始,早点结束,这样可以给自己留出充足时间做准备。
8、学习和面试的过程总是有喜有悲,不要太焦虑,也不要太自满,学会调节自己的心情很重要。
在这里贴出我面试前夕整理的脑图,由于展开内容很多,我就把最外层的几个分类给大家看
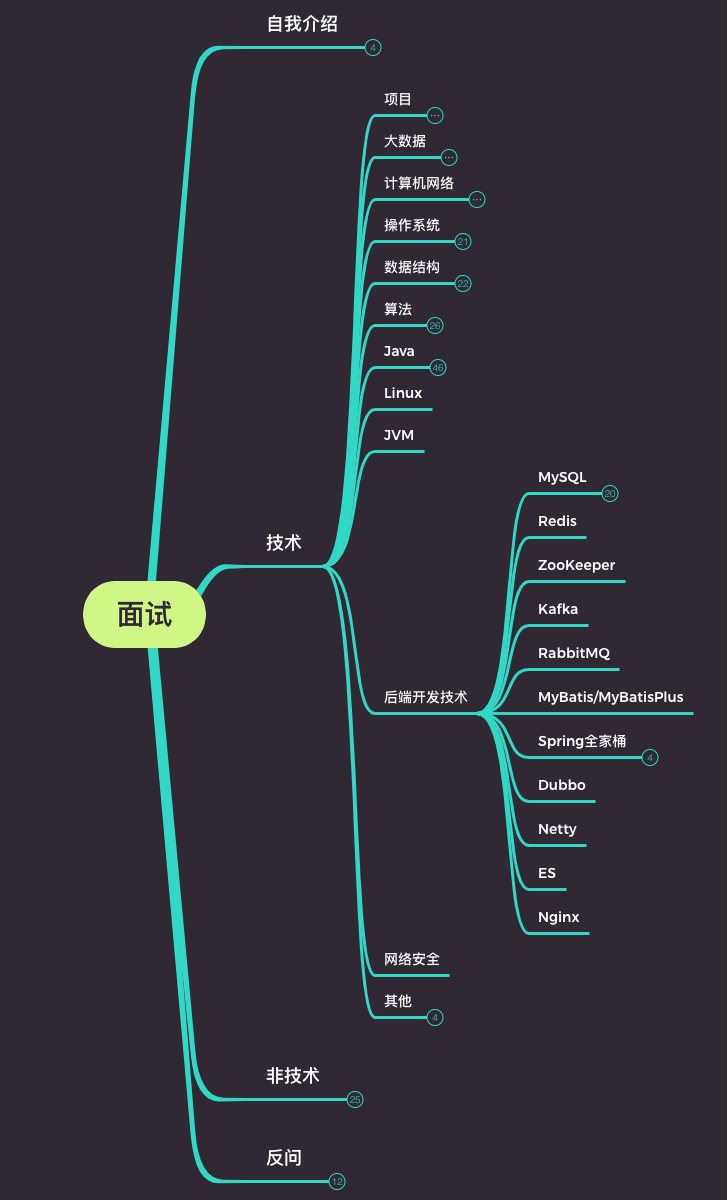
以下是我面试大厂的面经
秋招:
腾讯:
自我介绍
介绍下项目的架构
多端登录你是怎么实现的
项目发消息的流程
消息如何保证可靠性和实时性
为什么用Mysql做数据库
MySQL的索引
MySQL注入了解吗
Redis如何持久化
MySQL如何主从同步
Redis如何主从同步
AOF和RDB分别说一下,以及他们的应用场景
介绍下非对称加密算法和对称加密算法
群聊里的每一个成员如何确保得到消息
数据量大的时候怎么办
Mysql慢查询的优化了解吗
Redis的map底层的数据结构
hash底层数据结构
为什么到了8就扩容?(为什么是8)
https的流程
http的失败码
重定向是什么?
LSM树了解吗?
考你一个linux的命令:如何找出文件里100行数字里重复最多的数据
binlog了解吗?
美团:
LeetCode 移除元素
自我介绍
介绍一下你项目你觉得最难的任务
那么多端登录你是如何实现的
发红包功能怎么保证并发,怎么保证每个人只领到一份红包?
说说Java都有哪些基本数据类型
拆箱和装箱了解吗
容器(集合)了解吗,列举几个?
那么ArrayList你介绍下
那么什么时候用ArrayList,什么时候用LinkedList
介绍HashMap底层实现
那么为什么改成尾插法
HashMap能用在多线程吗?为什么?是因为他会遇到什么问题?(让我详细地说)
为什么用红黑树?
红黑树为什么查起来快
为什么是8变成红黑树?一直用红黑树不就好了吗
MySQL的引擎了解吗
Innodb和MyISAM有什么区别
Innodb支持事务,事务是什么你说下
并发下,事务会带来什么问题
那你介绍下脏读、不可重复度
这些隔离级别底层那你说说B+数底层实现吧具体是如何解决的呢?比如脏读
Innodb默认有什么索引?
说说B+树底层实现吧
如果一个SQL语句执行的很慢,要怎么做优化
最左匹配原则是什么
说说你对Java的理解
多态、重载、重写是什么意思
哔哩哔哩:
说一个自己觉得做得最印象深刻的功能开发过程
假如我不知道Zookeeper 你要怎么向我介绍
MySQL的引擎了解吗
MySQL的数据结构介绍
为什么想来上海
对前后端的认知
为什么选择做后端
未来的职业规划
项目的实时体现在哪里
两个算法题 一个二维数组的旋转 一个最长回文串
蘑菇街:
线程池了解什么?
到达核心线程数后新来的任务怎么办
HashMap和ConcurrentHashMap了解吗
关于ConcurrentHashMap底层synchronized是怎么上锁的
当扩容的时候synchronized是对value 还是key上锁?
HashMap是头插还是尾插
为什么头插会死循环
到了8一定会扩容吗?小于8会变回去吗
Spring了解多少
有一个配置如何在spring中自动加载
Memcache有和Redis区别
Redis如何持久化?它们二者区别
使用哪个持久化?恢复具体如何使用
春招:
腾讯一面:
top命令截图具体的两行是什么意思
redis如何做主从同步
主从同步过程丢失数据 怎么保证可靠性
为什么hashmap在jdk8后使用红黑树而不是avl树或者b+树
netty的io模型
nio的好处
nio和aio的比较
什么是零拷贝
volatile底层原理
强引用弱引用等 对象引用之间的区别
用过哪些排序的集合
进程用的是虚拟内存还是物理内存
腾讯二面:
算法题:12345678变成一千两百三十四万五千六百七十八
zk用什么算法实现一致性(zk的分布式一致性算法
udp的包长度
各大排序的平均复杂度
讲讲cap、cap如果是微信应该舍弃哪一个
sql注入你了解吗怎么避免
top命令第一行最右边三个参数
进程间的通信方式
select和epoll的区别
JVM的垃圾回收机制
MySQL有几种引擎,区别?
B树和B+树的区别?B树的应用?
慢查询的调优
10个数排序找最大或最小的
看过哪些框架的源码?看过
http1.1 1.0 2.0 3.0的区别
CORS CSRF XSS的区别
ssl原理
匿名管道和命名管道的区别
Nagle算法了解吗
timewait在服务端还是客户端
timewait的作用
如何查看占用最大的进程ID
从c语言设计的角度说如何设计服务端
布隆过滤器了解吗
Zset底层如何实现的
redis是单线程为什么还能保证读写
time_wait最长可以等多久
遇到过的困难
为什么不考研
什么时候能实习
有哪些offer
意向公司
看哪些网站来学习
携程一面:
hive的分区表和分桶表
分区的好处
介绍项目
项目自己做的几个需求介绍
偏向于数据采集还是数据处理
hive 几个排序的区别
项目用的是什么压缩格式
存储格式的区别
sql题:用户点击量最大的(要考虑并列去重 groupby)
用户跳转页面的新表生成
携程二面:
hadoop架构
spark的工作流程
spark如何划分job、task、stage
hive小文件过多用什么命令解决
hdfs上传文件下载文件的命令
zk几种节点
如何把kafka的东西存到HDFS
宽依赖窄依赖
hdfs不支持小文件的原因
SQL题 页面跳转统计
支持多线程的容器
网易雷火:
sql题 充值表字段:用户id 、充值金额、日期
1、查询每个用户的首充金额
2、查询某个用户11日当天的充值总金额、11~12当天充值总金额、11~13日(我没用窗口函数)
算法题:ip地址转换为固定的数字
介绍项目
项目的架构
项目有没有在架构上觉得不足之处,遇到过什么困难
数仓的分层
完成了哪些工作
充值业务数据是怎么做的
sortby有什么问题 可以用什么代替
最后希望大家都能提前准备,把握住校招,有些机会错过了可能就很难再有了。
--end--
扫描下方二维码
添加好友,备注【交流】
可私聊交流,也可进资源丰富学习群
更文不易,点个“在看”支持一下👇
评论