
值得收藏!这是 Python 数据预处理最频繁使用的5个技巧!
关注"Python学习与数据挖掘"
设为“置顶或星标”,第一时间送达干货
我们知道数据是一项宝贵的资产,近年来经历了指数级增长。但是原始数据通常不能立即使用,它需要进行大量清理和转换。
Pandas 是 Python 的数据分析和操作库,它有多种清理数据的方法和函数。在本文中,我将做5个示例来帮助大家掌握数据清理技能。
数据集
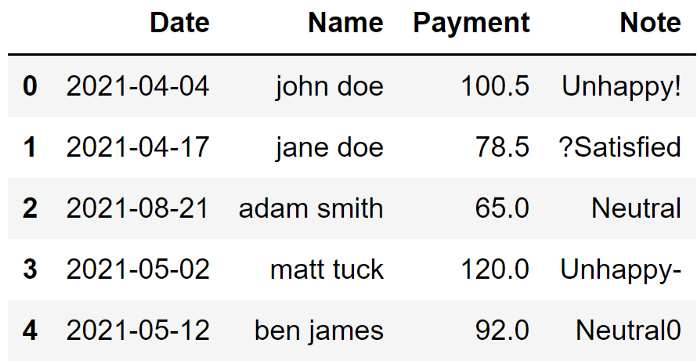
这是一个包含脏数据的示例数据框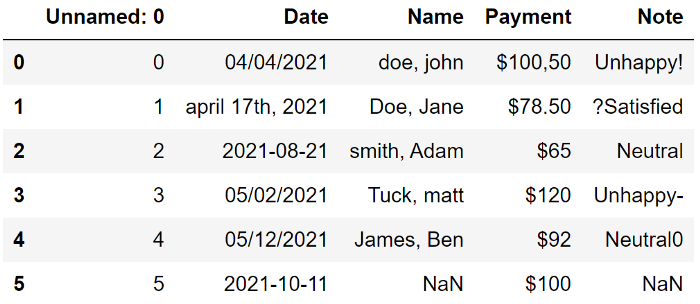 让我们看看可以做些什么来使这个数据集变得干净。
让我们看看可以做些什么来使这个数据集变得干净。
第一列是多余的,应该删除; Date 没有标准; Name 写成姓氏、名字,并有大写和小写字母; Payment 代表一个数量,但它们显示为字符串,需要处理; 在 Note 中,有一些非字母数字应该被删除;
示例 1
删除列是使用 drop 函数的简单操作。除了写列名外,我们还需要指定轴参数的值,因为 drop 函数用于删除行和列。最后,我们可以使用 inplace 参数来保存更改。
import pandas as pd
df.drop("Unnamed: 0", axis=1, inplace=True)
示例 2
我们有多种选择将日期值转换为适当的格式。一种更简单的方法是使用 astype 函数来更改列的数据类型。它能够处理范围广泛的值并将它们转换为整洁、标准的日期格式。
df["Date"] = df["Date"].astype("datetime64[ns]")
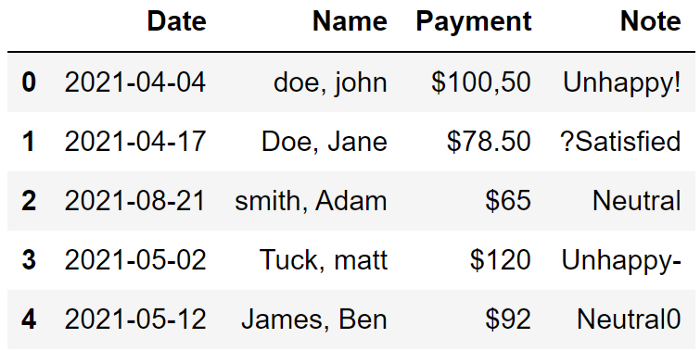
示例 3
关于名称列,我们首先需要解决如下问题:
首先我们应该用所有大写或小写字母来表示它们。另一种选择是将它们大写(即只有首字母是大写的); 切换姓氏和名字的顺序;
df["Name"].str.split(",", expand=True)
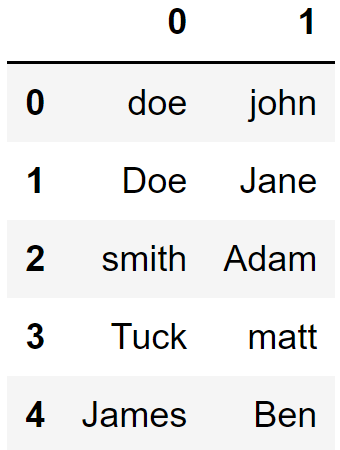
然后,我将取第二列与第一列结合起来,中间有一个空格。最后一步是使用 lower 函数将字母转换为小写。
df["Name"] = (df["Name"].str.split(",", expand=True)[1] + " " + df["Name"].str.split(",", expand=True)[0]).str.lower()
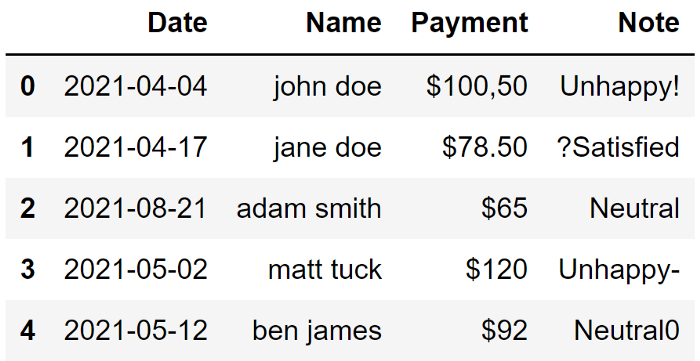
示例 4
支付Payment的数据类型是不能用于数值分析的。在将其转换为数字数据类型(即整数或浮点数)之前,我们需要删除美元符号并将第一行中的逗号替换为点。
我们可以使用 Pandas 在一行代码中完成所有这些操作
df["Payment"] = df["Payment"].str[1:].str.replace(",", ".").astype("float")
示例 5
Note 列中的一些字符也需要删除。在处理大型数据集时,可能很难手动替换它们。
我们可以做的是删除非字母数字字符(例如?、!、-、. 等)。在这种情况下也可以使用 replace 函数,因为它接受正则表达式。
如果我们只想要字母字符,下面是我们如何使用替换函数:
df["Note"].str.replace('[^a-zA-Z]', '')
0 Unhappy
1 Satisfied
2 Neutral
3 Unhappy
4 Neutral
Name: Note, dtype: object
如果我们想要字母和数字(即字母数字),我们需要在我们的正则表达式中添加数字:
df["Note"].str.replace('[^a-zA-Z0-9]', '')
0 Unhappy
1 Satisfied
2 Neutral
3 Unhappy
4 Neutral0
Name: Note, dtype: object
请注意,这次没有删除最后一行中的 0,我只需选择第一个选项。如果我还想在删除非字母数字字符后将字母转换为小写
df["Note"] = df["Note"].str.replace('[^a-zA-Z]', '').str.lower()
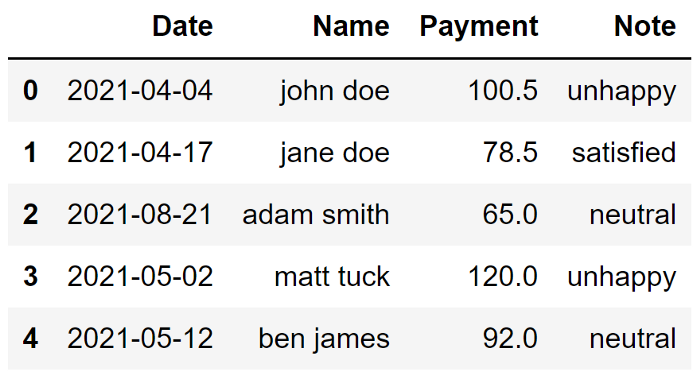 与初始形式相比,数据集看起来要好得多。当然,它是一个简单的数据集,但这些清理操作在处理大型数据集时肯定会对你有所帮助。
与初始形式相比,数据集看起来要好得多。当然,它是一个简单的数据集,但这些清理操作在处理大型数据集时肯定会对你有所帮助。
长按或扫描下方二维码,后台回复:加群,即可申请入群。一定要备注:来源+研究方向+学校/公司,否则不拉入群中,见谅!
(长按三秒,进入后台)
推荐阅读
