NIPS'21「微信」推荐系统:结合课程学习的多反馈表征解耦
title:Curriculum Disentangled Recommendation with Noisy Multi-feedback
link:https://proceedings.neurips.cc/paper/2021/file/e242660df1b69b74dcc7fde711f924ff-Paper.pdf
from:NIPS 2021
1. 导读
从多反馈中学习解耦的表征可以提升推荐系统的性能和可解释性,但是存在以下挑战:
多重反馈是复杂的:不同类型的反馈(如点击,曝光未点击和不喜欢等)以及不同的用户意图之间存在复杂的关系; 多反馈是有噪声的:在特征和标签中都存在噪声(无用)信息,这可能会降低推荐性能。
为了解决上述问题,本文提出CDR,提出利用协同过滤动态路由机制去噪并挖掘不同意图之间的关系,同时利用课程学习,从易到难,并且在标签级别去噪。
2. 方法
2.1 问题定义
符号:令表示两个向量做LayerNorm后的内积,sim(key,query)表示key和query的正则相似度,公式如下,
多反馈:第v个用户的反馈包含点击序列,未点击序列(曝光未点击)。不喜欢商品序列(包括,点击“不喜欢”反馈,低评分等)。序列中的商品都是与用户v交互过的商品,模型的目标就是从这些反馈中学习到用户的解耦意图,然后预测用户v对目标商品t的偏好。
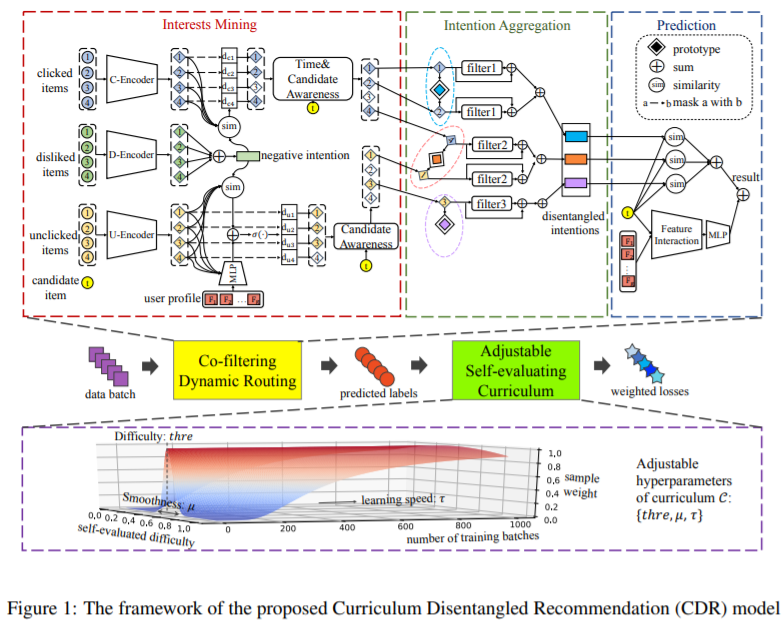
2.2 协同过滤动态路由
路由机制以用户画像、候选商品特征和用户多反馈历史作为输入,通过以下三个步骤进行最终预测。它首先利用各种反馈背后的关系来发现用户的真正兴趣所在。然后,该模型将用户从有用的行为中分离出来的意图聚合起来。最后,它根据学习到的意图预测用户对候选项的偏好。
2.2.1 兴趣挖掘
用户的兴趣可以通过各种反馈反映出来。忽略任何类型的反馈都可能导致不完整或不准确的偏好建模。然而,这些数据背后隐藏的噪声使得直接使用多重反馈来了解用户的兴趣是不可行的。因此,如何利用各种反馈之间的关系来发现用户真正的兴趣所在是这一步的关键。
首先,分别将上述三种反馈c,d,u的序列中的商品对应的ID和类别特征embedding拼接得到每个商品的embedding,然后得到各个序列的embedding序列,如下,
将用户画像中的特征映射为embedding,。然后通过transformer编码器对交互序列进行编码,以点击序列为例,得到
然后,发掘不同类型序列之间的关系。利用点击序列和未点击序列来发掘用户的兴趣,并且利用不喜欢的商品序列来进行去噪。不喜欢的商品序列可以强烈反应用户的负向意向,并且具有较高的置信度。对于用户v的负向意向,可以表示为,这种高置信度的负向意向可以用于过滤噪声。
将点击和未点击embedding序列中的每个商品与n求相似度,从而判断该商品是否对用户意向有帮助。与负向意图的相似度越高,对用户偏好的贡献越小,计算公式如下,其中表示relu,表示sigmoid,w,b为可学习参数。对于点击序列,直接求相似度来表示贡献程度;对于未点击序列,其中存在更多噪声,结合用户画像和负向偏好来计算每个商品的贡献。
除了噪声影响外,还需要考虑时间和目标商品的影响。直观地说,最近点击的商品和与目标商品具有更高相似性的商品将更多地影响用户对候选项目的偏好。公式如下,ht为目标商品的embedding,p为位置embedding。
note:可以发现,对于点击序列,不仅考虑了目标商品和序列中商品的关系,也考虑了最近点击的cm商品和序列中商品的关系,因为他们对最终目标商品的影响较大;而在未点击序列计算中,只计算了未点击序列商品与目标商品之间的关系,因为序列中的未点击商品之间的关系不强。
2.2.2 意图聚合
在上述操作之后,进行各种意图聚合,以获得各种潜在类别下的用户v的意图。假设所有用户的意图都可以分解为K个潜在类别,每个潜在类别的原型为,计算每个商品属于不同原型的概率。
然后,使用高置信度的负向意图,通过残差结构过滤点击和未点击的历史商品特征。通过用户的点击和未点击的序列商品的特征可以聚合出用户的第k个意图,分别为和。其中β为偏置,可学习。λ<1表示未点击序列的先验置信度。(这里zl_uj部分应该是n_u,论文中存在笔误)
其中d是去噪,f是加入时间信息,而c和u是表示不同意图。
2.2.3 预测
在得到不同类型的意图后,在考虑用户和目标商品的特征其对应embedding为,其中表示商品embedding的一个域,然后用多头注意力机制得到新的表征,公式如下,
再结合上述学到的不同意图,总体计算公式如下,其中s表示用户v对商品t的偏好。
损失函数包含两部分,一部分是交叉熵损失函数,另一部分是约束不同聚类原型的相似度,即不同意图的相似度。相似度最小化,控制不同意图尽量不同。
2.3 可调整的自评价课程学习
 存在于训练标签中的噪声也会将模型误导到次优参数。为了解决这个问题,作者利用课程学习的理念来消除噪音。然而,不同的课程策略(例如,从易到难、难样本挖掘等)对于不同的数据集设置是有效的,因此需要灵活的课程设计来适应复杂的推荐场景。
存在于训练标签中的噪声也会将模型误导到次优参数。为了解决这个问题,作者利用课程学习的理念来消除噪音。然而,不同的课程策略(例如,从易到难、难样本挖掘等)对于不同的数据集设置是有效的,因此需要灵活的课程设计来适应复杂的推荐场景。
为此,作者提出了一种可调整的自评估课程学习,算法如算法 1 所示。目标是为推荐者 F 获得最佳参数 θ。在一个batch B上训练时,
首先计算预测每个样本的结果 σ(sj ) 以及真实标签 yj 与预测之间的差异。(line 5) 然后,通过高斯分布获得每个样本的重要性,其中差异越接近预设值 thre 的样本将获得更高的重要性(line 6,7)。这里,超参数 thre ∈ (0, 1) 反映了希望模型关注的样本难度。具体来说,如果 thre 接近 1,则越难的样本将获得更高的权重。而如果 thre 接近 0,模型将更加强调更简单的样本。在实验中,可以调整 thre 的值来设置不同难度级别的课程,以便模型进行自我改进。 最后,使用现有的优化方法 π 通过重新加权的损失来优化参数。算法中,μ控制模型的集中程度,τ是时间-权重-衰减因子。随着训练的进行,随着时间τ,μ越来越小,这使得高斯分布越来越平滑,以至于最终所有样本几乎得到相等的权重进行训练(line 12)。
这个时变的过程符合人类的学习过程:在我们按照预定的课程逐步提高自己后,我们应该回顾所有的样本,以进一步巩固我们头脑中的知识。由于在早期阶段模型已经学习了足够多的知识,因此它可以更加稳健并且不太可能受到噪声样本的影响。通过调整 τ 的值,我们可以控制课程学习速度,其中较大的 τ 意味着更慢的学习过程。
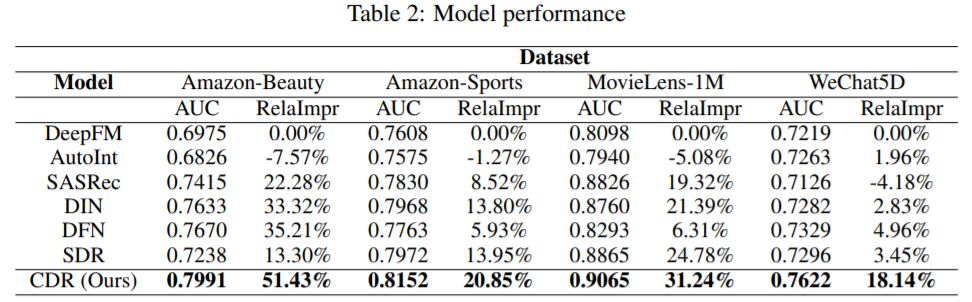
3. 结果