
爆肝何恺明的视觉预训练新范式MAE!
何恺明大神在去年11月发表了一篇新论文:Masked Autoencoders Are Scalable Vision Learners证明了 masked autoencoders(MAE) 是一种可扩展的计算机视觉自监督学习方法。

本文提出了一种掩膜自编码器 (MAE)架构,可以作为计算机视觉的可扩展自监督学习器使用,而且效果显著。
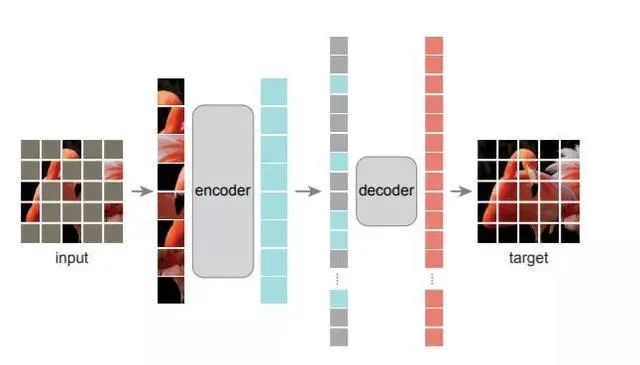
此文最大的贡献,可能是在NLP和CV两大领域之间架起了一座更简便的桥梁。
深度之眼特邀讲师电子羊,将用1个小时的时间,为大家直播讲解本篇论文。
1月14日晚20:00直播
扫码0.1元订阅
附赠老师直播PPT课件
评论