
【NLP】使用堆叠双向 LSTM 进行情感分析
情绪分析
情感分析是发现文本数据的情感的过程。情感分析属于自然语言处理中的文本分类。情绪分析将帮助我们更好地了解我们的客户评论。
情绪的性质有:正面、负面和中性。当我们分析产品的负面评论时,我们可以使用这些评论来克服我们面临的问题并提供更好的产品。

使用情感分析的好处包括:
更好地了解客户
根据客户评论改进产品功能
我们将能够识别功能中的错误并解决它们以使客户满意。
情感分析可以通过两种不同的方式进行:
基于规则的情感分析
自动化情绪分析
在基于规则的情感分析中,我们定义了一组规则,如果数据满足这些规则,那么我们可以对它们进行相应的分类。
例如,如果文本数据包含好、漂亮、惊人等词,我们可以将其归类为积极情绪。基于规则的情感分析的问题在于它不能很好地概括并且可能无法准确分类。
例如,基于规则的系统更有可能根据规则将以下句子归类为正面,“The product is not good”。原因是基于规则的系统识别出句子中的单词 good 并将其归类为积极情绪,但上下文不同,句子是消极的。
为了克服这些问题,我们可以使用深度学习技术进行情感分析。
在自动情感分析中,我们利用深度学习来学习数据中的特征-目标映射。在我们的例子中,特征是评论,目标是情绪。因此,在我们的文章中,我们使用深度学习模型来进行自动情感分析。
使用 TensorFlow 进行情感分析
在这篇文章中,我们将利用深度学习来发现 IMDB 评论的情绪。我们将在这篇文章中使用 IMDB 评论数据。你可以在此处(https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews)下载数据。
数据包含两列,即评论和情绪。情绪列仅包含两个值,即正面和负面,表示相应评论的情绪。所以我们可以推断我们的问题是一个二元分类问题。我们的模型将学习特征-目标映射,在我们的例子中,它是评论-情绪映射。
在这篇文章中,我们将使用 regex 和 spaCy 进行预处理,使用 TensorFlow 的双向 LSTM 模型进行训练。
要安装 spaCy,请参阅此(https://spacy.io/usage#installation)网页以获取说明。
要安装 TensorFlow,请参阅此(https://www.tensorflow.org/install)网页以获取说明。
安装 spaCy 后,使用以下命令下载名为 en_core_web_sm 的 spaCy 的训练管道包,我们将使用它进行预处理。
python -m spacy download en_core_web_sm
导入所需的库
import re
import spacy
import numpy as np
import pandas as pd
import en_core_web_sm
import tensorflow as tf
from nltk.stem import WordNetLemmatizer
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.models import Sequential
from spacy.lang.en.stop_words import STOP_WORDS
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional, Dropout
nlp = en_core_web_sm.load()
lemmatizer = WordNetLemmatizer()
stopwords = STOP_WORDS
EMOJI_PATTERN = re.compile(
"["
u"U0001F600-U0001F64F" # emoticons
u"U0001F300-U0001F5FF" # symbols & pictographs
u"U0001F680-U0001F6FF" # transport & map symbols
u"U0001F1E0-U0001F1FF" # flags (iOS)
u"U00002702-U000027B0"
u"U000024C2-U0001F251"
"]+", flags=re.UNICODE
)
FILTERS = '!"#$%&()*+,-/:;?@[\]^_`{|}~tn'
HTML_TAG_PATTERN = re.compile(r']*>')
NUMBERING_PATTERN = re.compile('d+(?:st|[nr]d|th)')
DISABLE_PIPELINES = ["tok2vec", "parser", "ner", "textcat", "custom", "lemmatizer"]
我们正在使用命令 en_core_web_sm.load() 加载 spaCy 的训练管道 en_core_web_sm。我们还加载了 spaCy 中可用的停用词。停用词是没有太多意义的词,一些例子包括像 the、he、she、it 等词。
上面定义的表情符号模式EMOJI_PATTERN用于删除评论数据中的表情符号。
上面定义的过滤器FILTERS是评论中可能提供的特殊字符。
上面定义的 HTML 标记模式(HTML_TAG_PATTERN)用于删除 HTML 标记并仅保留标记内的数据。
上面定义的编号模式NUMBERING_PATTERN用于删除编号,如 1st、2nd、3rd 等。
上面定义的禁用管道DISABLE_PIPELINES用于禁用 spaCy 语言模型中的某些管道,从而高效且低延迟地完成处理。
def initial_preprocessing(text):
"""
- Remove HTML tags
- Remove Emojis
- For numberings like 1st, 2nd
- Remove extra characters > 2 eg:
ohhhh to ohh
"""
tag_removed_text = HTML_TAG_PATTERN.sub('', text)
emoji_removed_text = EMOJI_PATTERN.sub(r'', tag_removed_text)
numberings_removed_text = NUMBERING_PATTERN.sub('', emoji_removed_text)
extra_chars_removed_text = re.sub(
r"(.)1{2,}", r'11', numberings_removed_text
)
return extra_chars_removed_text
def preprocess_text(doc):
"""
Removes the
1. Spaces
2. Email
3. URLs
4. Stopwords
5. Punctuations
6. Numbers
"""
tokens = [
token
for token in doc
if not token.is_space and
not token.like_email and
not token.like_url and
not token.is_stop and
not token.is_punct and
not token.like_num
]
"""
Remove special characters in tokens except dot
(would be useful for acronym handling)
"""
translation_table = str.maketrans('', '', FILTERS)
translated_tokens = [
token.text.lower().translate(translation_table)
for token in tokens
]
"""
Remove integers if any after removing
special characters, remove single characters
and lemmatize
"""
lemmatized_tokens = [
lemmatizer.lemmatize(token)
for token in translated_tokens
if len(token) > 1
]
return lemmatized_tokens
labels = imdb_data['sentiment'].iloc[:10000]
labels = labels.map(lambda x: 1 if x=='positive' else 0)
"""
Preprocess the text data
"""
data = imdb_data.iloc[:10000, :]
column = 'review'
not_null_data = data[data
.notnull()]
not_null_data
= not_null_data
.apply(initial_preprocessing)
texts = [
preprocess_text(doc)
for doc in nlp.pipe(not_null_data
, disable=DISABLE_PIPELINES)
]
上面的代码是如何工作的?
首先,我们取前 10000 行数据。此数据中的目标是名为“情绪”的列。情绪列由两个值组成,即“正面”和“负面”,表示相应评论的情绪。
我们用整数 1 替换值“正”,用整数 0 替换值“负”。
我们只取非空的行,这意味着我们忽略了具有空值的评论。在获得非空评论后,我们应用上面定义的初始预处理函数。
方法初始预处理后的步骤是,
删除 HTML 标签,如 ,并提取标签内定义的数据
删除数据中的表情符号
删除数据中的编号模式,如 1st、2nd、3rd 等。
删除单词中的多余字符。例如,单词 ohhh 被替换为 ohh。
在应用初始预处理步骤后,我们使用 spacy 来预处理数据。预处理方法遵循的步骤是,
删除数据中的空格。
删除数据中的电子邮件。
删除数据中的停用词。
删除数据中的 URL。
删除数据中的标点符号。
删除数据中的数字。
词形还原。
函数 nlp.pipe 将在 spaCy 中生成一系列 doc 对象。spaCy 中的文档是一系列令牌对象。我们使用禁用管道来加快预处理时间。
词形还原是寻找词根的过程。例如,单词 running 的词根是 run。进行词形还原的目的是减少词汇量。为了使单词词形还原,我们使用了 nltk 包中的 WordNetLemmatizer。
tokenizer = Tokenizer(
filters=FILTERS,
lower=True
)
padding = 'post'
tokenizer.fit_on_texts(texts)
vocab_size = len(tokenizer.word_index) + 1
sequences = []
max_sequence_len = 0
for text in texts:
# convert texts to sequence
txt_to_seq = tokenizer.texts_to_sequences([text])[0]
sequences.append(txt_to_seq)
# find max_sequence_len for padding
txt_to_seq_len = len(txt_to_seq)
if txt_to_seq_len > max_sequence_len:
max_sequence_len = txt_to_seq_len
# post padding
padded_sequences = pad_sequences(
sequences,
maxlen=max_sequence_len,
padding=padding
)
执行预处理后,我们将对数据进行标记化,将标记化的单词转换为序列,并填充标记化的句子。标记化是将句子分解为单词序列的过程。
例如,“我喜欢苹果”可以标记为 [“我”,“喜欢”,“苹果”]。将标记化的句子转换为序列看起来像 [1, 2, 3]。单词“i”、“like”和“apples”被映射到数字 1、2 和 3。然后填充序列看起来像 [1, 2, 3, 0, 0, 0]。数字 3 后面的三个零是填充序列。这也称为后填充。
model = Sequential()
model.add(Embedding(vocab_size, 64, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(64, return_sequences=True, input_shape=(None, 1))))
model.add(Dropout(0.2))
model.add(Bidirectional(LSTM(32)))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(1, activation='sigmoid'))
adam = Adam(learning_rate=0.01)
model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=adam,
metrics=['accuracy']
)
model.summary()
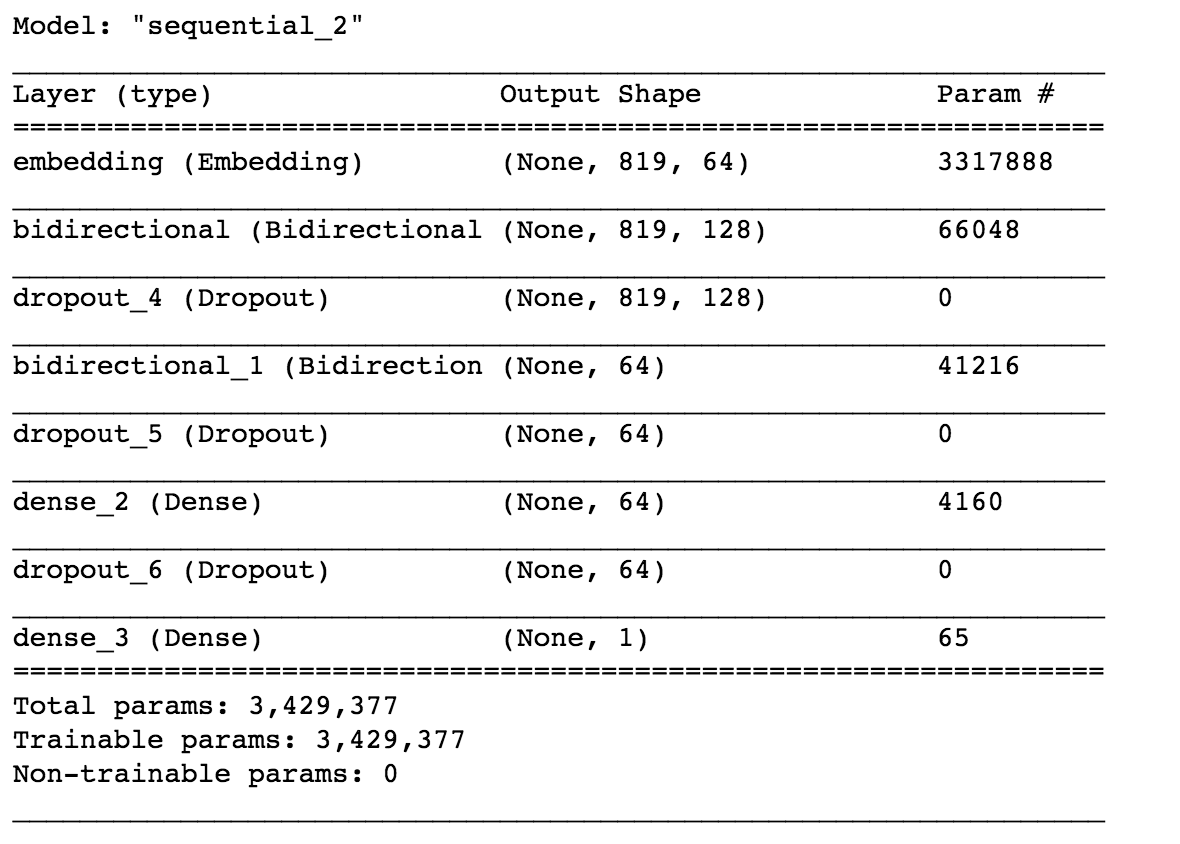
这里我们使用了使用 TensorFlow 的双向 LSTM 模型。让我们深入了解模型的工作原理。
首先,我们定义了一个嵌入层。嵌入层将单词转换为词向量。例如,单词“apple”可以嵌入为 [0.2, 0.12, 0.45]。维数是一个超参数。
使用词嵌入的目的是在词之间找到更好的相似性,这是独热编码失败的地方。这里我们选择了维度64。
我们在这里使用的模型是堆叠的双向 LSTM。第一个双向层定义为 64 个单元,第二层定义为 32 个双向 LSTM 单元。
之后,我们使用了具有 64 个单元的 Dense 层和激活函数 ReLU。最后一层是具有 sigmoid 激活函数的输出层,因为我们的问题是一个二元分类问题,我们使用了 sigmoid 函数。我们还使用了 Dropout 层来防止过度拟合。
我们使用 Adam 优化函数进行反向传播,并使用二元交叉熵损失函数进行度量的损失和准确性。损失函数用于优化模型,而度量用于我们的比较。要了解有关 LSTM 工作的更多信息,请参阅此博客:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
history = model.fit(
padded_sequences,
labels.values,
epochs=10,
verbose=1,
batch_size=64
)
现在是时候训练模型了。我们使用了 10 个 epoch 和 64 的批量来训练。我们使用评论的填充序列作为特征,将情感作为目标。

import matplotlib.pyplot as plt
fig = plt.plot(history.history['accuracy'])
title = plt.title("History")
xlabel = plt.xlabel("Epochs")
ylabel = plt.ylabel("Accuracy")
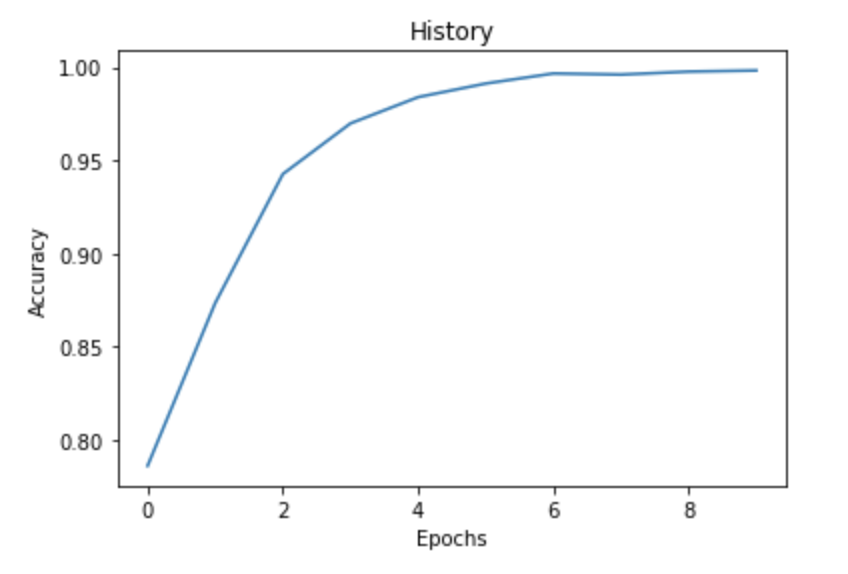
如果我们绘制历史记录,我们可以清楚地看到,随着epoch的增加,我们的准确性也会提高。我们获得了 99.82% 的准确率。
现在我们已经训练了我们的模型,我们可以用它来进行预测。
predictions = model.predict(padded_sequences[:4])
for pred in predictions:
print(pred[0])
我们使用了前四篇经过预处理和预测的评论。我们正在获得以下结果。
Output
0.99986255
0.9999008
0.99985176
0.00030466914
输出表示积极情绪的概率。让我们检查一下这是否正确。

这些预测非常令人印象深刻。通过这种方式,你可以利用 TensorFlow 进行情感分析。
总结
在这篇文章中,我们了解了基于规则的情感分析和自动情感分析之间的区别。此外,我们利用深度学习的自动化情感分析来分析情感。
使用 spaCy 预处理数据。使用标记器将文本转换为序列。
使用堆叠双向 LSTM 训练数据
训练后绘制历史
使用经过训练的模型进行预测
随意调整模型的超参数,例如更改优化器函数、添加额外层、更改激活函数,并尝试增加嵌入向量中的维度。这样,你将能够获得更精细,更精细的结果。
往期精彩回顾 本站qq群554839127,加入微信群请扫码: