
Google Research提出StylEx:训练GAN可视化解释每个属性如何影响分类模型 | ICCV2021
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
大家好,我是阿潘,今天给大家分享一篇最新的成果《Explaining in Style: Training a GAN to explain a classifier in StyleSpace》,以前对分类器进行视觉解释的方法,例如注意力图突出显示图像中的哪些区域影响分类,但它们没有解释 这些区域内的【属性】决定了分类结果。本文提出了一种新的分类器视觉解释方法。StylEx 会自动发现和可视化影响分类器的【解耦属性】。它允许通过单独操作这些属性来探索单个属性的影响(更改一个属性不会影响其他属性)
论文标题:
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
论文、代码和主页链接:
https://arxiv.org/abs/2104.13369
https://github.com/google/explaining-in-style
https://explaining-in-style.github.io/

效果:

上面是一些应用示例,通过编辑人脸的属性,并可视化每个生成结果的最终得分。
更多效果:
解读
神经网络可以非常出色地执行某些任务,但了解它们如何做出决定——例如,识别图像中的哪些信号导致模型确定它属于一类而不是另一类——[通常是一个谜](https:/ /www.nature.com/news/can-we-open-the-black-box-of-ai-1.20731)。解释神经模型的决策过程可能会在某些领域产生high social impact ,例如医学图像分析和自动驾驶,其中人工监督至关重要。这些见解还有助于指导医疗保健机构、揭示模型偏差、为下游决策者提供支持,甚至有助于科学发现。
以前对分类器进行视觉解释的方法,例如注意力图(例如,Grad-CAM),突出显示图像中的哪些区域影响分类,但它们没有解释 这些区域内的属性决定了分类结果:例如,是它们的颜色吗?它们的形状?另一类方法通过在一类和另一类之间平滑转换图像来提供解释(例如,GANalyze)。然而,这些方法往往会同时改变所有属性,因此难以隔离影响个体的属性。
high social impact:https://www.nature.com/articles/s42256-019-0048-x
Grad-CAM:https://arxiv.org/abs/1610.02391
GANalyze:https://arxiv.org/abs/1906.10112
在“Explaining in Style: Training a GAN to explain a classifier in StyleSpace ”中,发表于 ICCV 2021,我们提出了一种新的分类器视觉解释方法。我们的方法 StylEx 会自动发现和可视化影响分类器的解耦属性。它允许通过单独操作这些属性来探索单个属性的影响(更改一个属性不会影响其他属性)。StylEx 适用于广泛的领域,包括动物、树叶、人脸和视网膜图像。我们的结果表明,StylEx 找到的属性与语义属性非常吻合,生成有意义的特定于图像的解释,并且在用户研究中可以被人们解释。
Explaining in Style: Training a GAN to explain a classifier in StyleSpace (https://arxiv.org/pdf/2104.13369.pdf)
ICCV 2021: https://iccv2021.thecvf.com/home
视频的内容解释猫与狗分类器:StylEx 提供了解释分类的 top-K 发现的解耦属性。移动每个旋钮仅操作图像中的相应属性,保持对象的其他属性固定。
例如,要了解给定图像上的猫与狗分类器,StylEx 可以自动检测分离的属性,并可视化操作每个属性如何影响分类器概率。然后用户可以查看这些属性并对它们所代表的内容进行语义解释。例如,在上图中,可以得出“狗比猫更容易张开嘴”(上图 GIF 中的属性 #4)、“猫的瞳孔更像狭缝”(属性 # 5),“猫的耳朵不倾向于折叠”(属性#1),等等。
How StylEx Works: Training StyleGAN to Explain a Classifier
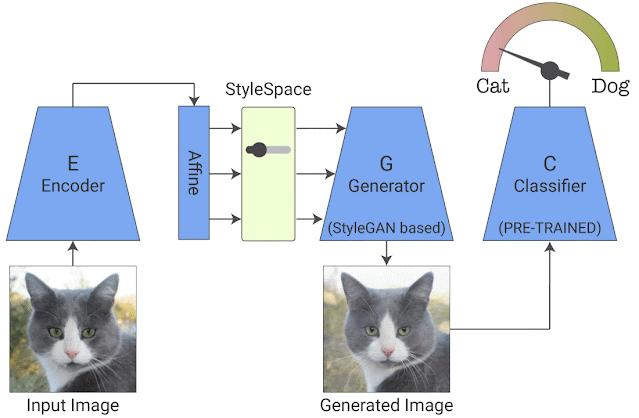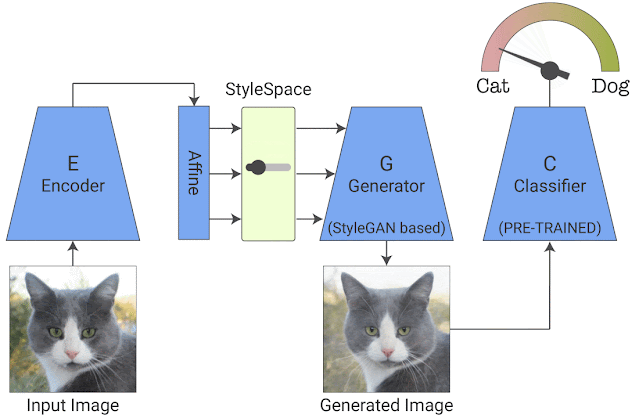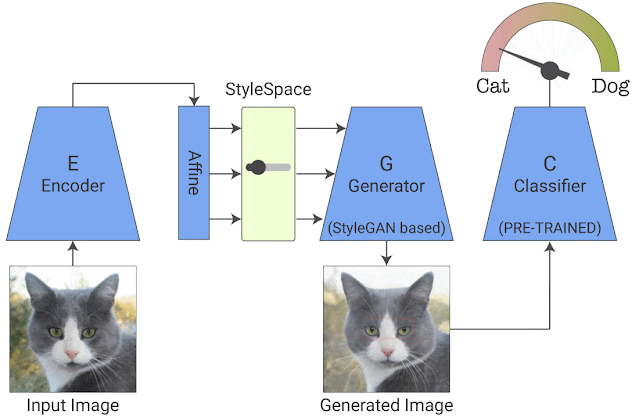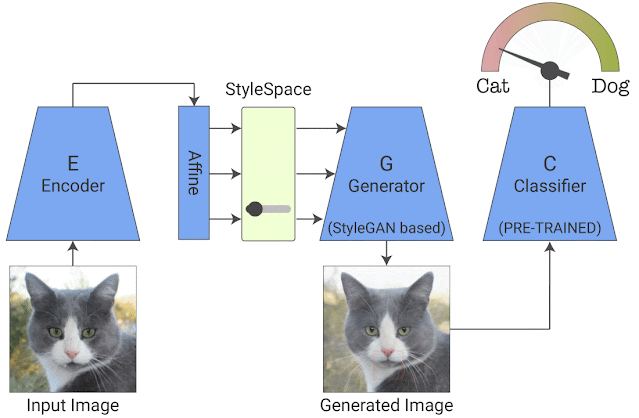
给定一个分类器和一个输入图像,我们希望找到并可视化影响其分类的各个属性。为此,我们利用 StyleGAN2 架构,该架构以生成高质量图像而闻名。我们的方法包括两个阶段:
StyleGAN2 https://arxiv.org/abs/1912.04958
Phase 1: Training StylEx
最新的工作表明 StyleGAN2 包含一个名为“StyleSpace”的解耦潜在空间,其中包含训练数据集中图像的单个语义上有意义的属性。但是,由于 StyleGAN 训练不依赖于分类器,它可能无法代表那些对我们要解释的特定分类器的决策很重要的属性。因此,我们训练了一个类似于 StyleGAN 的生成器来满足分类器,从而鼓励它的 StyleSpace 适应分类器特定的属性。
https://arxiv.org/abs/2011.12799
这是通过使用两个附加组件训练 StyleGAN 生成器来实现的。第一个是编码器,与具有重建损失的 GAN 一起训练,它强制生成的输出图像在视觉上与输入相似。这允许我们将生成器应用于任何给定的输入图像。然而,图像的视觉相似性是不够的,因为它可能不一定捕获对特定分类器(例如医学病理学)重要的细微视觉细节。为了确保这一点,我们在 StyleGAN 训练中添加了一个分类损失,它强制生成图像的分类器概率与输入图像的分类器概率相同。这保证了对分类器很重要的细微视觉细节(例如医学病理学)将包含在生成的图像中。
架构图:
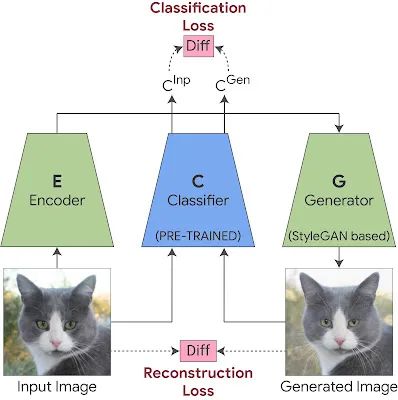
Training StyleEx:我们联合训练生成器和编码器。在生成的图像和原始图像之间应用重建损失以保持视觉相似性。在生成图像的分类器输出和原始图像的分类器输出之间应用分类损失,以确保生成器捕获对分类很重要的细微视觉细节。
Phase 2: Extracting Disentangled Attributes
训练完成后,我们会在经过训练的生成器的 StyleSpace 中搜索显着影响分类器的属性。为此,我们操纵每个 StyleSpace 坐标并测量其对分类概率的影响。我们寻求使给定图像的分类概率变化最大化的顶级属性。这提供了 top-K 图像特定属性。通过对每个类的大量图像重复这个过程,我们可以进一步发现 top-K 类特定属性,它告诉我们分类器对特定类的了解。我们称我们的端到端系统为“StylEx”。
图像特定属性提取的可视化说明:一旦训练,我们搜索对给定图像的分类概率影响最大的 StyleSpace 坐标。
StylEx is Applicable to a Wide Range of Domains and Classifiers
我们的方法适用于各种领域和分类器(二元和多类)。以下是类特定解释的一些示例。在所有测试的领域中,我们的方法检测到的顶级属性在由人类解释时对应于连贯的语义概念,并通过人类评估得到验证。
对于感知的性别和年龄分类器,以下是每个分类器检测到的前四个属性。我们的方法举例说明了自动选择的多个图像上的每个属性,以最好地展示该属性。对于每个属性,我们在源图像和属性操作图像之间闪烁。操作属性对分类器概率的影响程度显示在每个图像的左上角。

Top-4 自动检测到的感知性别分类器的属性。

Top-4 自动检测到的感知年龄分类器的属性。
请注意,我们的方法解释的是分类器,而不是现实。也就是说,该方法旨在揭示给定分类器从数据中学会利用的图像属性;这些属性可能不一定代表现实中类别标签(例如年轻或年长)之间的实际物理差异。特别是,这些检测到的属性可能会揭示分类器训练或数据集中的偏差,这是我们方法的另一个关键优势。它可以进一步用于提高神经网络的公平性,例如,通过增加训练数据集的示例来补偿我们的方法揭示的偏差。
在分类依赖于精细细节的领域中,将分类器损失添加到 StyleGAN 训练中变得至关重要。例如,在没有分类器损失的情况下在视网膜图像上训练的 GAN 不一定会生成与特定疾病相对应的精细病理细节。添加分类损失会导致 GAN 生成这些微妙的病理学作为分类器的解释。下面以视网膜图像分类器 (DME disease) 和病叶/健康叶分类器为例。StylEx 能够发现与疾病指标一致的属性,例如“硬渗出物”,这是众所周知的视网膜 DME 标记,以及叶病的腐烂。
DME disease:https://arxiv.org/pdf/1710.01711.pdf
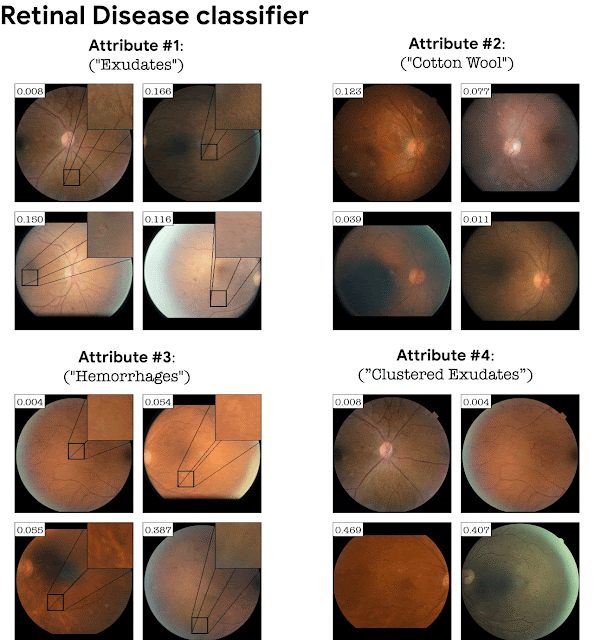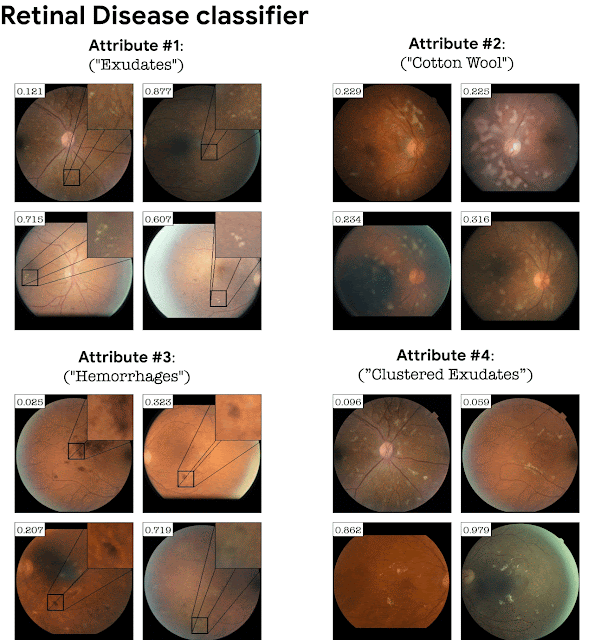
Top-4 自动检测视网膜图像 DME 分类器的属性。

Top-4 自动检测到病/健康叶子图像分类器的属性。

最后,该方法也适用于多类问题,如 鸟类分类器所示。
在 CUB-2011 上训练的 200 路分类器中,Top-
4 自动检测到(a)“brewer blackbird”类和(b)“yellow bellied flycatcher”类的属性。事实上,我们观察到 StylEx 检测到与 CUB 分类中的属性相对应的属性。
Broader Impact and Next Steps
总的来说,我们引入了一种新技术,可以为给定图像或类上的给定分类器生成有意义的解释。我们相信,我们的技术是朝着检测和缓解分类器和/或数据集中先前未知的偏差迈出的有希望的一步,符合 Google 的 AI 原则。此外,我们对基于多属性的解释的关注是提供关于以前不透明的分类过程的新见解和帮助科学发现过程的关键。最后,我们的 GitHub 存储库包括 Colab 和我们论文中使用的 GAN 的模型权重。
CVPR2021 最具创造力的那些工作成果!或许这就是计算机视觉的魅力!