
2020年数据术语的故事
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源

2020年整个技术圈子要说话题最多的,应该是大数据方向。新感念层出不穷,数据湖概念就是其中之一。这篇文章是关于数据仓库、数据湖、数据集市、数据中台等一些列的概念和发展进程。希望给大家带来一个全面的感知。
本文作者:Murkey学习之旅、开心自由天使
本文整理:大数据技术与架构,未经允许不得转载。
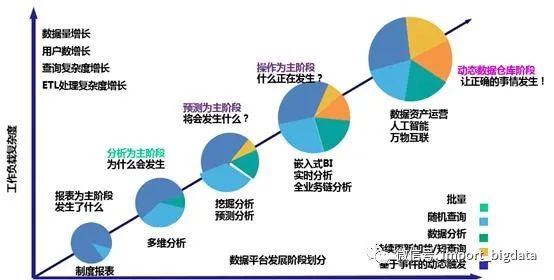
如今,随着诸如互联网以及物联网等技术的不断发展,越来越多的数据被生产出来-据统计,每天大约有超过2.5亿亿字节的各种各样数据产生。这些数据需要被存储起来并且能够被方便的分析和利用。
随着大数据技术的不断更新和迭代,数据管理工具得到了飞速的发展,相关概念如雨后春笋一般应运而生,如从最初决策支持系统(DSS)到商业智能(BI)、数据仓库、数据湖、数据中台等,这些概念特别容易混淆,本文对这些名词术语及内涵进行系统的解析,便于读者对数据平台相关的概念有全面的认识。
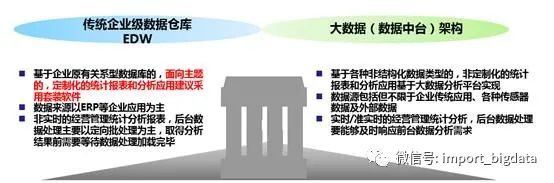
一、数据仓库
它利用信息科技,将分散于企业内、外部各种数据加以整合并转换成知识,并依据某些特定的主题需求,进行决策分析和运算;
用户则通过报表、图表、多维度分析的方式,寻找解决业务问题所需要的方案;
这些结果将呈报给决策者,以支持策略性的决策和定义组织绩效,或者融入智能知识库自动向客户推送。
1.1、数据仓库基本定义
所谓主题:是指用户使用数据仓库进行决策时所关心的重点方面,如:收入、客户、销售渠道等;所谓面向主题,是指数据仓库内的信息是按主题进行组织的,而不是像业务支撑系统那样是按照业务功能进行组织的。
所谓集成:是指数据仓库中的信息不是从各个业务系统中简单抽取出来的,而是经过一系列加工、整理和汇总的过程,因此数据仓库中的信息是关于整个企业的一致的全局信息。
所谓随时间变化:是指数据仓库内的信息并不只是反映企业当前的状态,而是记录了从过去某一时点到当前各个阶段的信息。通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
1.2、数据仓库系统作用和定位
是面向企业中、高级管理进行业务分析和绩效考核的数据整合、分析和展现的工具;
是主要用于历史性、综合性和深层次数据分析;
数据来源是ERP(例:SAP)系统或其他业务系统;
能够提供灵活、直观、简洁和易于操作的多维查询分析;
不是日常交易操作系统,不能直接产生交易数据。
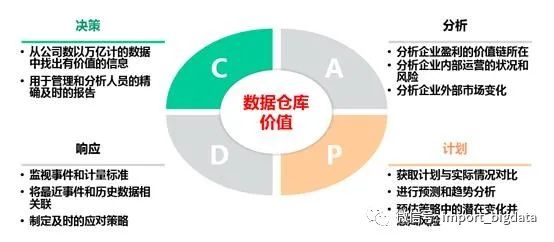
1.3、数据仓库能提供什么
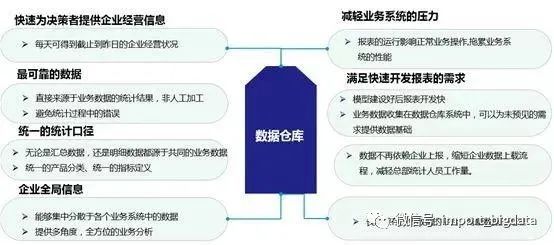
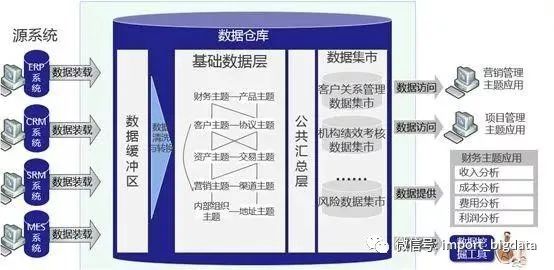
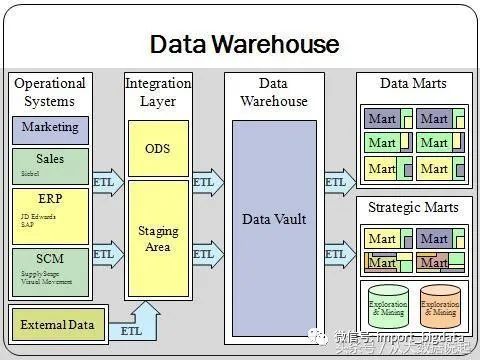
1.4、数据仓库系统构成
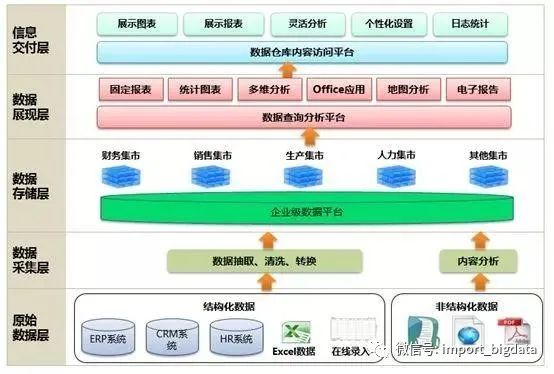
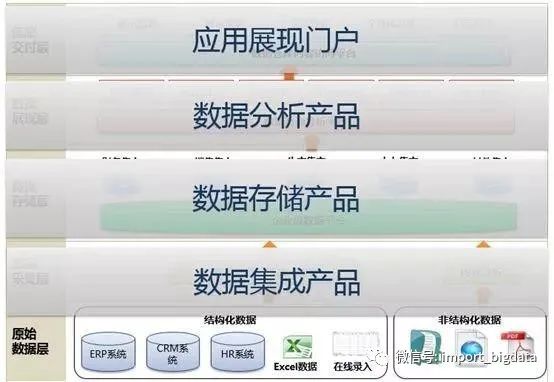
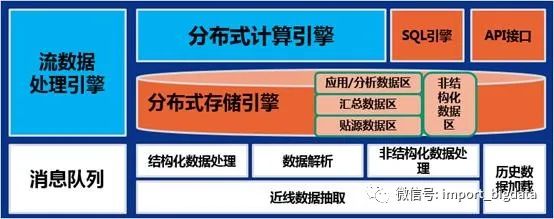
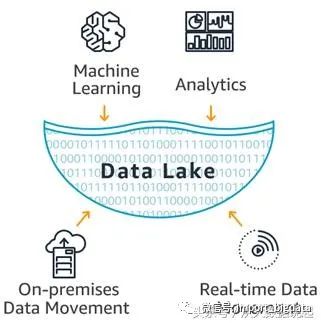
二、数据湖
从源系统导入所有的数据,没有数据流失。
数据存储时没有经过转换或只是简单的处理。
数据转换和定义schema 用于满足分析需求。
2.1、维基百科对数据湖的定义
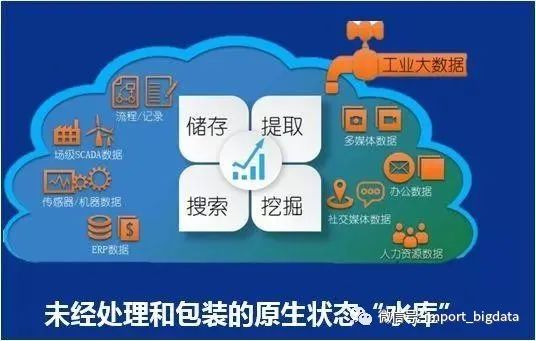
2.2、数据湖能给企业带来多种能力
实现数据治理(data governance);
通过应用机器学习与人工智能技术实现商业智能;
预测分析,如领域特定的推荐引擎;
信息追踪与一致性保障;
根据对历史的分析生成新的数据维度;
有一个集中式的能存储所有企业数据的数据中心,有利于实现一个针对数据传输优化的数据服务;
帮助组织或企业做出更多灵活的关于企业增长的决策。
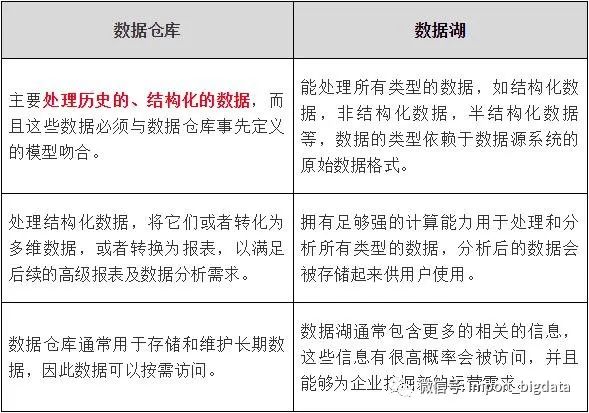
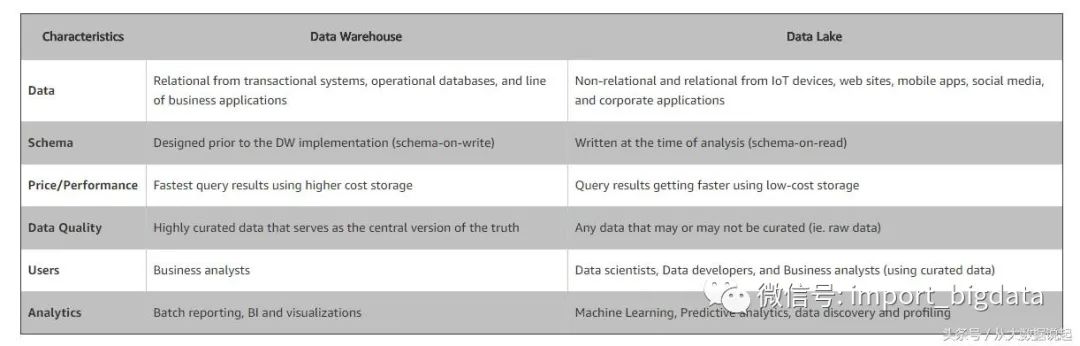
在储存方面上,数据湖中数据为非结构化的,所有数据都保持原始形式。存储所有数据,并且仅在分析时再进行转换。数据仓库就是数据通常从事务系统中提取。
在将数据加载到数据仓库之前,会对数据进行清理与转换。在数据抓取中数据湖就是捕获半结构化和非结构化数据。而数据仓库则是捕获结构化数据并将其按模式组织。
数据湖的目的就是数据湖非常适合深入分析的非结构化数据。数据科学家可能会用具有预测建模和统计分析等功能的高级分析工具。而数据仓库就是数据仓库非常适用于月度报告等操作用途,因为它具有高度结构化。
在架构中数据湖通常,在存储数据之后定义架构。使用较少的初始工作并提供更大的灵活性。在数据仓库中存储数据之前定义架构。表1 数据仓库和数据湖的区别
三、数据中台
3.1、产生的背景
3.2、数据中台建设是数字化转型的支撑
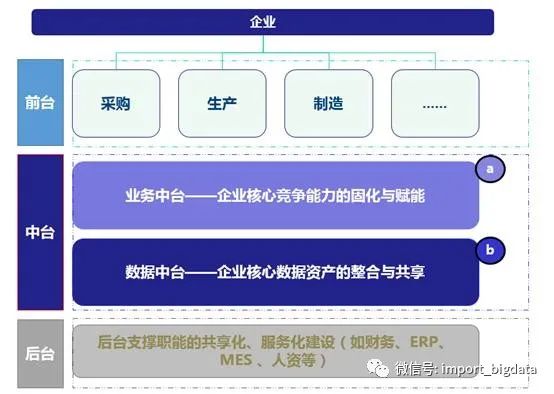
敏捷前台:一线作战单元,强调敏捷交互及稳定交付的组织能力建设。
业务中台:能力固化与赋能,固化通用能力,赋能前线部队,提升配置效率,加快前线响应,产品化业务化,开辟全新生态。
数据中台:资产整合与共享,整合多维数据,统一资产管理,连通数据孤岛,共享数据资源,深入挖掘数据,盘活资产价值。
稳定后台:以共享中心建设为核心,为前中台提供专业的内部服务支撑。
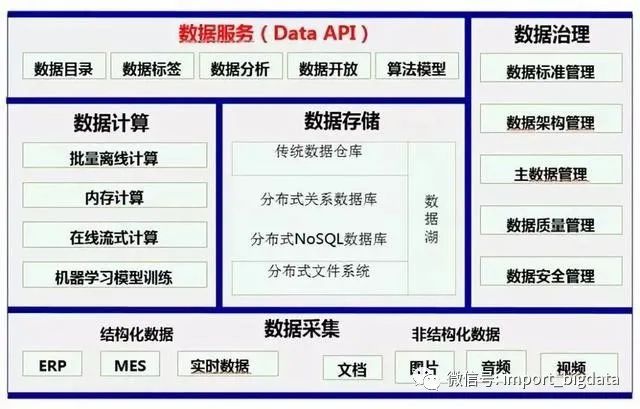
3.4、数据中台带来价值
构建了开放、灵活、可扩展的企业级统一数据管理和分析平台, 将企业内、外部数据随需关联,打破了数据的系统界限。
利用大数据智能分析、数据可视化等技术,实现了数据共享、日常报表自动生成、快速和智能分析,满足集团总部和各分子公司各级数据分析应用需求。
深度挖掘数据价值,助力企业数字化转型落地。实现了数据的目录、模型、标准、认责、安全、可视化、共享等管理,实现数据集中存储、处理、分类与管理,建立大数据分析工具库、算法服务库,实现报表生成自动化、数据分析敏捷化、数据挖掘可视化,实现数据质量评估、落地管理流程。
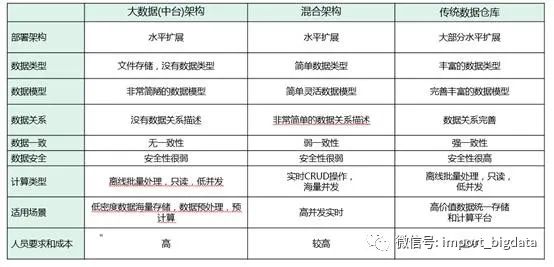

四、数据湖(Data Lake)和数据仓库(Data Warehouses)理解误区

误解一:数据仓库和数据湖二者在架构上只能二选一
误解二:相对于数据湖,数据仓库更有名更受欢迎
误解三:数据仓库易于使用,而数据湖却很复杂
五、数据仓库、数据集市与数据湖的对比
从源系统导入所有的数据,没有数据流失。
数据存储时没有经过转换或只是简单的处理。
数据转换和定义schema 用于满足分析需求。
5.1数据湖保留全部的数据
5.2.数据湖支持所有数据类型
5.3.数据库支持所有用户使用
5.4.数据湖很容易适应变化
5.5.数据湖支持快速洞察数据
5.6 数据仓库vs.数据集市
5.7 数据仓库vs.ODS
5.8 关系型数据库vs.数据仓库和数据湖
六、小结
 二.数据仓库:
二.数据仓库:2.有特定的应用。
3.面向部门。
4.由业务部门定义、设计和开发。
5.业务部门管理和维护。
6.能快速实现。
7.购买较便宜。
8.投资快速回收。
9.工具集的紧密集成。
10.提供更详细的、预先存在的、数据仓库的摘要子集。
11.可升级到完整的数据仓库。
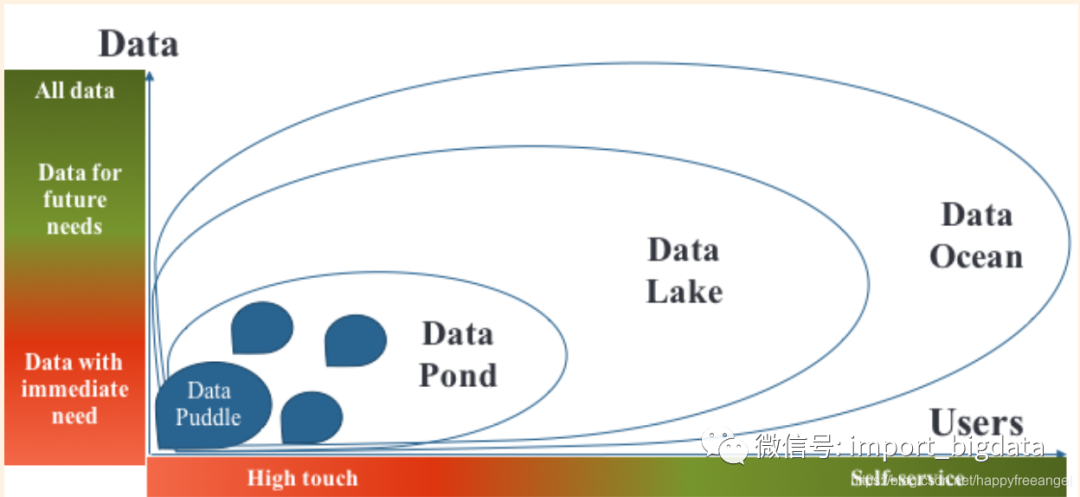
有时,构建数据水坑是为了帮助IT人员进行自动化的计算密集型和数据密集型流程,例如提取,转换,加载(ETL)卸载,这些将在后面的章节中详细介绍,在这些章节中,所有转换工作都从数据仓库或仓库中转移。昂贵的ETL工具到大数据平台。另一个常见用途是通过提供一个称为“沙箱”的工作区域为单个团队提供服务,数据科学家可以在其中进行实验。
数据水坑通常范围较小,数据种类有限-它们由小型专用数据流填充,并且构建和维护它们需要技术团队或IT部门的大力参与。
数据池(Data Ponds):数据池是数据水坑的集合。正如您可以将数据池视为使用大数据技术构建的数据集市一样,您也可以将数据池视为使用大数据技术构建的数据仓库。随着更多的水坑被添加到大数据平台,它可能有机地存在。创建数据池的另一种流行方法是将数据仓库卸载。
与ETL卸载不同,ETL卸载使用大数据技术来执行填充数据仓库所需的一些处理,此处的想法是将数据仓库中的所有数据加载到大数据平台中。愿景通常是最终摆脱数据仓库以节省成本并提高性能,因为大数据平台比关系数据库便宜得多且可伸缩性更高。但是,仅卸载数据仓库并不能使分析人员访问原始数据。由于仍然保持适用于数据仓库的严格体系结构和治理,因此组织无法解决数据仓库的所有挑战,例如冗长而昂贵的变更周期,复杂的转换以及将人工编码作为所有报告的基础。最后,分析人员通常不喜欢从具有闪电般快速查询的精细数据仓库迁移到可预测性差得多的大数据平台,在该平台上,大批查询的运行速度可能比数据仓库中的运行速度快,但更典型的小型查询可能需要几分钟的时间。数据池的一些典型局限性:缺乏可预测性,敏捷性以及无法访问未经处理的原始数据。
