
一切为了AI!黄仁勋GTC大会发布全新DPU处理器,计算吞吐量三年跨越1000倍

新智元报道
新智元报道
编辑:白峰、QJP
【新智元导读】昨晚的GTC大会,英伟达推出了包括数据中心、边缘人工智能、协作工具和医疗健康等多个场景的AI计算解决方案。同时,黄仁勋重磅发布了全新DPU处理器,未来三年计算吞吐量将跨越1000倍。
昨晚的GTC大会上,教主黄仁勋再次下到厨房,为大家炒出多道新品!

这次GTC大会主题很鲜明,AI,一切为了AI!英伟达要把自己的AI算力发挥到极致,赋能千行百业。
过去,服务器领域一直是英特尔领衔的X86架构占据主导地位,各种GPU、NPU只是以加速卡形式出现,但今天英伟达公布了数据中心专用处理器DPU有可能改变这一局面,DPU结合Arm将在服务器市场撼动X86的地位。
DPU拥抱Arm,大举发力服务器市场
DPU拥抱Arm,大举发力服务器市场
以前我们有CPU、GPU,但显然英伟达认为这些都还不够,于是又推出了「BlueField-2 DPU」以及对应的软件生态架构DOCA(Data-Center-Infrastructure-On-A-Chip Architecture)。
英伟达企业计算负责人Manuvir Das将DOCA比作服务器领域的CUDA,此举显然是想在服务器领域复制CUDA的成功经验。
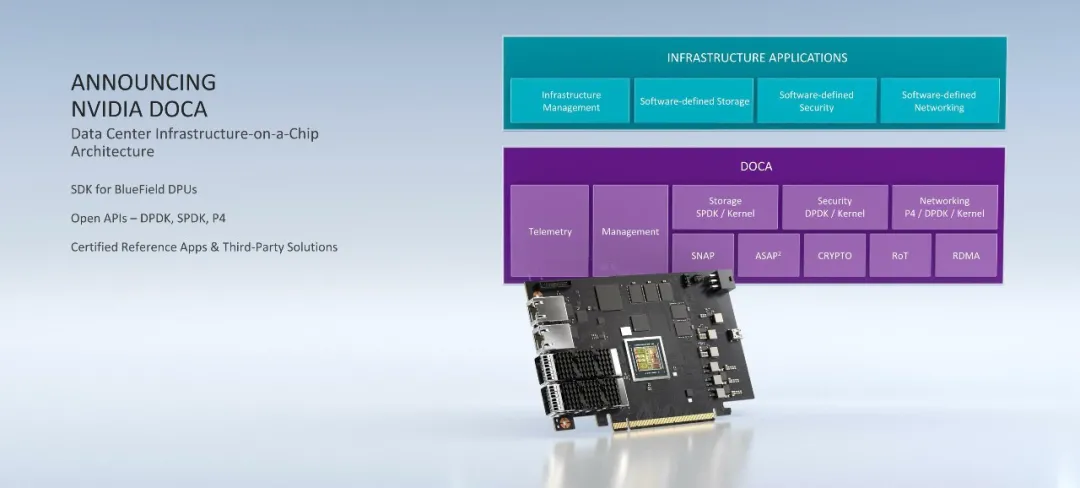
DPU是一种新型数据处理单元(Data Processing Unit)。BlueField 2 DPU是一个具有Arm核心和加速引擎的可编程处理器,用于网络、存储和安全的在线速度处理。
数据处理器由 DOCA 提供支持,DOCA 是一种数据中心基础设施芯片架构,支持突破性的网络、存储和安全性能。
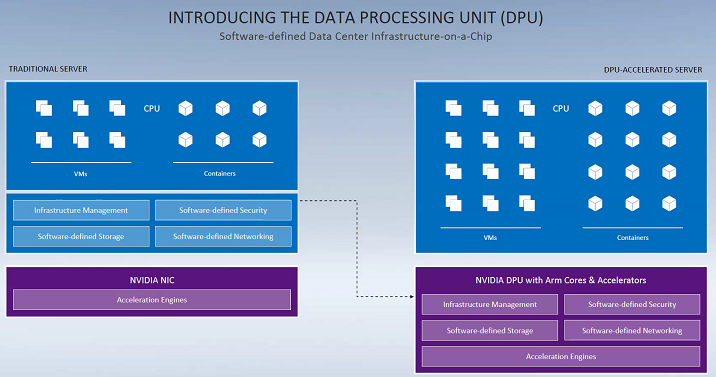
上图是一个单一的 BlueField-2 DPU,可以提供相同的数据中心服务,BlueField-2集成了8个64位A72 Arm核,2个超长指令字(VLIW)加速引擎,以及两个100Gb/s的网络通道(Mellanox ConnectX 6 Dx NIC),并在安全性能、网络性能和存储性能上有诸多亮点。

英伟达称,一颗BlueField-2 DPU可以替换125颗x86处理器,这样可以释放出宝贵的 CPU 核心来运行大范围的其他企业应用程序。
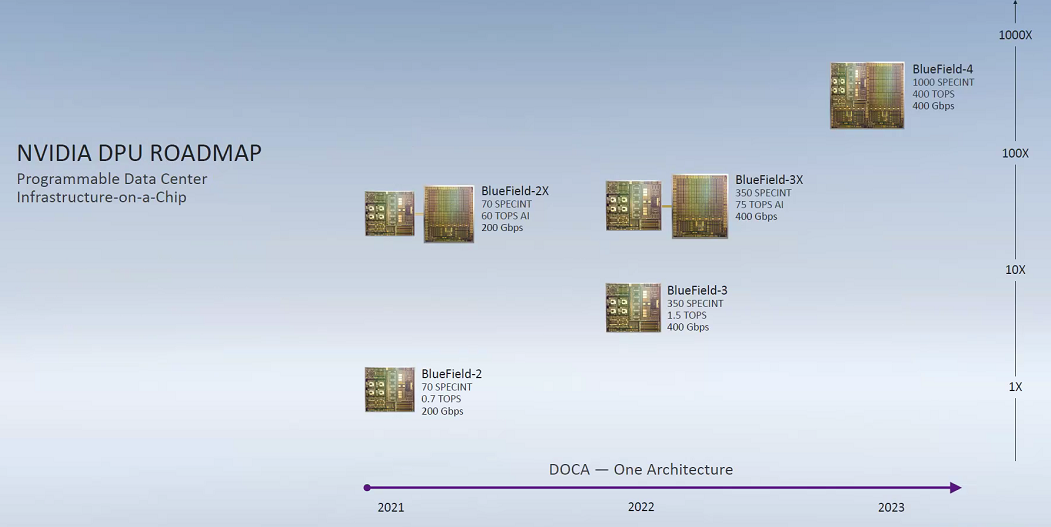
老黄还透露了DPU为期三年的发展计划,其中包括 NVIDIA BlueField-2系列DPU和 NVIDIA DOCA 软件开发工具包,用于构建DPU加速数据中心基础设施服务的应用程序。
「数据中心已经成为新的计算单位,DPU是现代安全加速数据中心的重要组成部分,在这些数据中心中,CPU、GPU和数据处理器可以组合成一个完全可编程的、支持人工智能的计算单元,并且可以提供以前无法提供的安全级别和计算能力。」
除此之外,老黄还说BlueField-2正在进行采样测试,BlueField-3正在完成,BlueField-4正在加速研发设计,他还补充说「 BlueField-4将于2023年推出,为 CUDA 并行编程平台和 NVIDIA AI 增强网络计算视野提供帮助」。届时都会采用Arm的新型CPU架构,其中BlueField-4的整体效能将会是BlueField-2的600-1000倍左右。

除了 BlueField-2,黄仁勋还介绍了「BlueField-2X DPU」,包括了BlueField-2 DPU 的所有关键特性,同时增强了Ampere架构GPU的AI能力。它可以应用于数据中心的安全、网络和存储任务。
从NVIDIA的第三代Tensor Cores中,它可以使用人工智能进行实时安全分析,包括识别可能显示机密数据被盗的异常流量、以线速度进行加密流量分析、主机自省以识别恶意活动,以及动态安全编排和自动响应。

针对大型物联网等边缘计算的需求,老黄宣布,EGX Edge AI 平台正在扩展,将 NVIDIA Ampere GPU 和 BlueField-2 DPU 合并到一张 PCIe 卡上,试图通过易于部署的云端原生应用软件加速边缘计算。这次更新将为机构提供一个共同的平台,以建立安全、快捷的数据中心。

Jetson Nano:人人可用的AI开发套件,仅售59美元
Jetson Nano:人人可用的AI开发套件,仅售59美元
英伟达今天宣布在 Edge 平台上扩展 Jetson AI,这是一个基于Arm的 SoC,经过了全新的设计。

Jetson Nano 2GB 开发工具包是 NVIDIA 的 Jetson AI 在 The Edge 平台的最新产品,它得到了 NVIDIA JetPack SDK 的支持,该 SDK 附带了 NVIDIA 运行时和完整的 Linux 软件开发环境。
Jetson Nano 为教授和学习人工智能而设计的,在机器人和智能物联网等领域创建实践项目。该套装将在本月底通过 NVIDIA 的分销渠道以59美元的价格发售。
Maxine:Zoom们的超级加速器,体验极致视频会议
Maxine:Zoom们的超级加速器,体验极致视频会议
疫情的爆发,让Zoom火遍全球,视频会议也迎来的自己的元年,亚马逊、谷歌,国内的腾讯、阿里等都推出了自己的视频会议软件,爆发式的增长,让英伟达也看到了机会。
这次,英伟达推出了基于云计算的流媒体视频AI平台Maxine,Maxine将整合英伟达在音视频领域的AI能力,为视频会议软件提供高质量的视频体验和极致的加速性能。
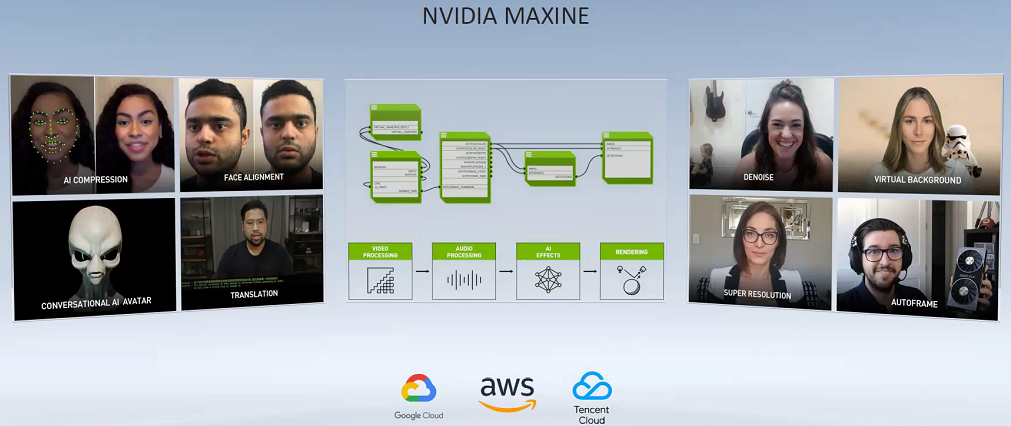
Maxine平台采用了模块化设计,视频会议软件可以轻松集成Maxine上视频相关的AI能力。
所有的推理任务都在云端NVIDIA GPU上进行,视频会议服务提供商可以使用Maxine平台为用户提供各种视频AI能力,如超分辨率、风格转换、环境降噪、实时字幕等,由于数据都搬到了云端,同时也会降低本地终端硬件的功耗。
Maxine通过各种AI视频压缩技术,可以将视频会议所消耗的带宽减少到原来的十分之一。
基于英伟达的生成对抗网络Video2Video,StyleGan等技术,Maxine使得视频会议更加丰富多彩,如自动更换背景,自动人脸对齐,人脸风格化等。

目前,Maxine已经跟三大公有云Google Cloud、AWS、 Microsoft Azure 以及 ORACLE 展开合作,对广大视频会议应用开发者来说真是「开箱即用」。
AI算力达400 petaflops,剑桥-1将问鼎英国超算
AI算力达400 petaflops,剑桥-1将问鼎英国超算
黄仁勋在主题演讲中表示: 为应对全球医疗领域最紧迫的挑战,大规模的计算资源比以往更需要人工智能。
因此英伟达推出了名为剑桥 -1的超级计算机,它将成为英国的创新中心,进一步推动英国研究人员在关键医疗保健和药物发现方面的开创性工作。
这个新系统是以剑桥大学命名的,剑桥 -1包含80个DGX A100系统,20tb/sec 的带宽,2 pb 的 NVMe 内存,如此强大的配置功耗却仅有500KW 。
Nvidia 表示,剑桥 -1将提供8 petaflops Linpack性能 ,AI性能超过400 petaflops,将使其成为英国最顶级的计算系统,在 Top500上排名第29位。
但是,这种算法与 Top500所基于的双精度 Linpack 基准测试并不一致。剑桥 -1的640 个A100 gpu 提供了6.2 petaflops 的 IEEE标准的双精度计算能力。再加上160个 Epyc Rome 处理器提供的约500万亿次浮点运算,仍然低于8 petaflops 浮点运算性能 。
剑桥 -1将服务于学术界和工业界,例如葛兰素史克(GSK)等,它将解决大规模的医疗保健和数据科学问题,并且将计算资源捐赠给研究机构,方便全世界研究人员使用,帮助培养AI人才。
其他
其他
除了以上这些,黄仁勋还宣布了公司已经进入 NVIDIA Omniverse 平台的公测阶段。Omniverse 支持客户在机器人、汽车、建筑、工程和建筑、制造、媒体和娱乐行业工作所必需的协作和模拟,「 Omniverse 允许设计师、艺术家、创作者,甚至是在不同世界使用不同工具的人工智能,在一个共同的世界中连接起来ーー合作,共同创造一个世界」。
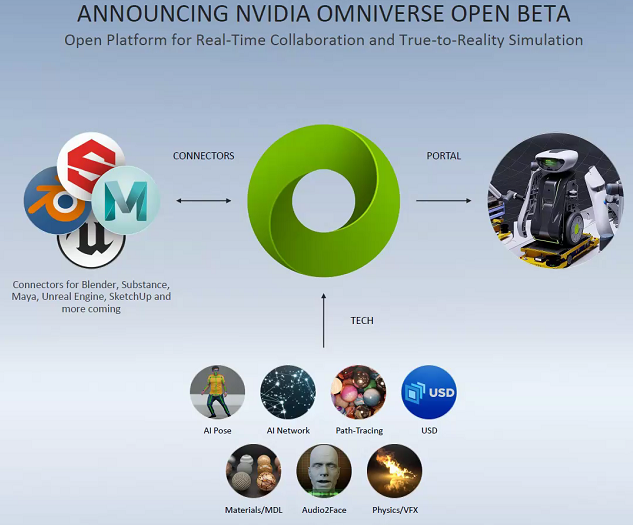
Omniverse是一个实时的线上的GPU-3D模拟协作平台,使用了Pixar所开发的开源3D场景,可以让设计师开发者直接在线上对3D建模进行协作。举个例子,像台湾和美国的动画团队就可以在上面开3D专案创建动画,或者让汽车工程师在3D环境里同时模拟与自动调整功能。
老黄还宣布提供免费的在线培训和 AI 认证项目。这些认证计划将为各种源项目提供补充,包括如何操作和视频,这些都是由 Jetson 社区的成千上万的开发者提供的。
收购Arm后,英伟达的AI实力将更加雄厚,能否搅动英特尔的服务器市场地位,让我们拭目以待。
推荐阅读:

