
【从零开始学TVM】三,基于ONNX模型结构了解TVM的前端
【GiantPandaCV导语】本文基于Pytorch导出的ONNX模型对TVM前端进行了详细的解析,具体解答了TVM是如何将ONNX模型转换为Relay IR的,最后还给出了一个新增自定义OP的示例。其实在TVM中支持编译多种目前主流的深度学习框架如TensorFlow,Pytorch,MxNet等,其实它们的前端交互过程和本文介绍的ONNX也大同小异,希望对TVM感兴趣的读者在阅读这篇文章之后对新增OP,或者说在TVM中支持一种新的DL框架有一个整体把握。本文实验相关的代码在https://github.com/BBuf/tvm_learn。
0x0. 介绍
在这个专题的前面两次分享中对TVM以及scheduler进行了介绍,这篇文章我们将基于TVM的前端来尝试走进TVM的源码。TVM的架构如下图所示:
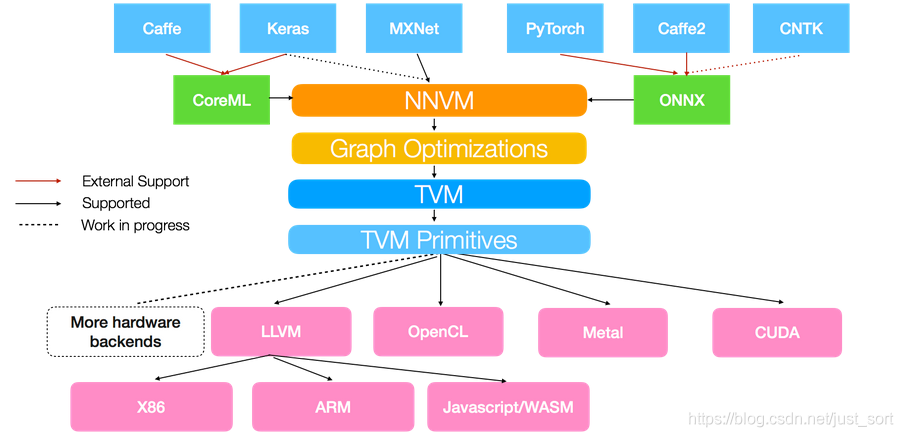
这里说的TVM的前端指的是将Caffe/Keras/MxNet等框架训好的模型使用Relay的对应接口进行加载,这个接口就是TVM的模型解析前端,它负责将各种框架的计算图翻译成TVM可以处理的计算图。本文以ONNX模型为例,走一遍这个过程,并尝试剖析一下这个过程中的关键代码,以及如果我们要支持自定的模型应该怎么做(新增OP)?
0x1. 使用TVM加载ONNX模型并预测
由于官方文档示例中提供的ONNX模型因为网络原因一直下载不下来,所以这里在第一次推文的基础上用Pytorch的ResNet18模型导出一个ONNX作为例子。在导出ONNX之前我们需要确认Pytorch模型是正确的。具体来说,我们预测一张猫的图片看一下它的类别是否对应猫。代码如下:
import torch
import numpy as np
import torchvision
# 加载torchvision中的ResNet18模型
model_name = "resnet18"
model = getattr(torchvision.models, model_name)(pretrained=True)
model = model.eval()
from PIL import Image
image_path = 'cat.png'
img = Image.open(image_path).resize((224, 224))
# 处理图像并转成Tensor
from torchvision import transforms
my_preprocess = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
img = my_preprocess(img)
img = np.expand_dims(img, 0)
# 使用Pytorch进行预测结果
with torch.no_grad():
torch_img = torch.from_numpy(img)
output = model(torch_img)
top1_torch = np.argmax(output.numpy())
print(top1_torch)
# export onnx
torch_out = torch.onnx.export(model, torch_img, 'resnet18.onnx', verbose=True, export_params=True)
其中top1_torch的值为282,这个ID恰好对应着ImageNet中的猫类别,所以我们可以认为上面的Pytorch模型是正确的。至于导出的ONNX模型,我们接着使用TVM来加载它并进行推理看一下,在推理之前建议先用Netron打开看一下,看看导出的模型是否正常。
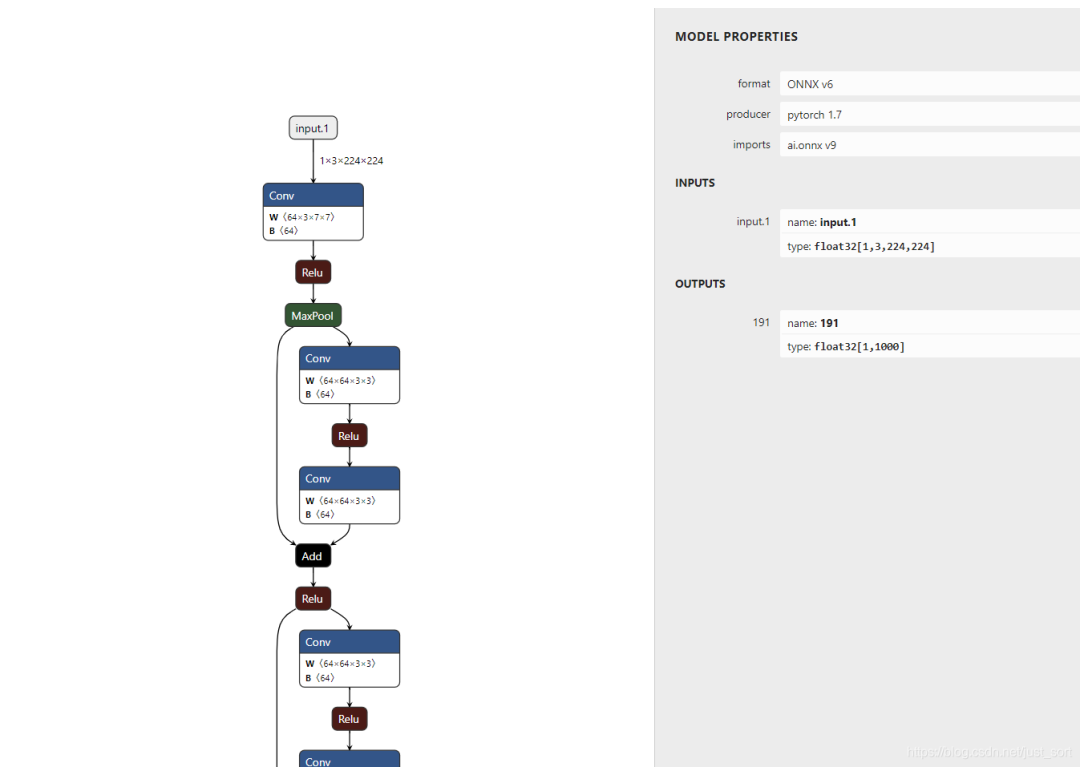
现在我们使用TVM来导入ONNX并进行推理,首先导入一些要用到的包,并对输入数据进行预处理,这里和上面的Pytorch程序保持输入一致,并且预处理也是完全一致的:
import onnx
import numpy as np
import tvm
from tvm import te
import tvm.relay as relay
onnx_model = onnx.load('resnet18.onnx')
from PIL import Image
image_path = 'cat.png'
img = Image.open(image_path).resize((224, 224))
# Preprocess the image and convert to tensor
from torchvision import transforms
my_preprocess = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
img = my_preprocess(img)
x = np.expand_dims(img, 0)
接下来我们使用TVM的Relay将ONNX模型变成TVM可以识别的Graph IR,TVM在Realy中提供了一个frontend.from_onnx用来加载ONNX模型并转换为Relay IR。我们加载完模型之后可以打印看一下ONNX模型在TVM中对应的IR变成什么样了。代码如下:
# 这里设置了target表示我们要在CPU后端运行Realy IR
target = "llvm"
input_name = "input.1"
shape_dict = {input_name: x.shape}
mod, params = relay.frontend.from_onnx(onnx_model, shape_dict)
我们先打印一下mod:
def @main(%input.1: Tensor[(1, 3, 224, 224), float32], %v193: Tensor[(64, 3, 7, 7), float32], %v194: Tensor[(64), float32], %v196: Tensor[(64, 64, 3, 3), float32], %v197: Tensor[(64), float32], %v199: Tensor[(64, 64, 3, 3), float32], %v200: Tensor[(64), float32], %v202: Tensor[(64, 64, 3, 3), float32], %v203: Tensor[(64), float32], %v205: Tensor[(64, 64, 3, 3), float32], %v206: Tensor[(64), float32], %v208: Tensor[(128, 64, 3, 3), float32], %v209: Tensor[(128), float32], %v211: Tensor[(128, 128, 3, 3), float32], %v212: Tensor[(128), float32], %v214: Tensor[(128, 64, 1, 1), float32], %v215: Tensor[(128), float32], %v217: Tensor[(128, 128, 3, 3), float32], %v218: Tensor[(128), float32], %v220: Tensor[(128, 128, 3, 3), float32], %v221: Tensor[(128), float32], %v223: Tensor[(256, 128, 3, 3), float32], %v224: Tensor[(256), float32], %v226: Tensor[(256, 256, 3, 3), float32], %v227: Tensor[(256), float32], %v229: Tensor[(256, 128, 1, 1), float32], %v230: Tensor[(256), float32], %v232: Tensor[(256, 256, 3, 3), float32], %v233: Tensor[(256), float32], %v235: Tensor[(256, 256, 3, 3), float32], %v236: Tensor[(256), float32], %v238: Tensor[(512, 256, 3, 3), float32], %v239: Tensor[(512), float32], %v241: Tensor[(512, 512, 3, 3), float32], %v242: Tensor[(512), float32], %v244: Tensor[(512, 256, 1, 1), float32], %v245: Tensor[(512), float32], %v247: Tensor[(512, 512, 3, 3), float32], %v248: Tensor[(512), float32], %v250: Tensor[(512, 512, 3, 3), float32], %v251: Tensor[(512), float32], %fc.bias: Tensor[(1000), float32], %fc.weight: Tensor[(1000, 512), float32]) {
%0 = nn.conv2d(%input.1, %v193, strides=[2, 2], padding=[3, 3, 3, 3], kernel_size=[7, 7]);
%1 = nn.bias_add(%0, %v194);
%2 = nn.relu(%1);
%3 = nn.max_pool2d(%2, pool_size=[3, 3], strides=[2, 2], padding=[1, 1, 1, 1]);
%4 = nn.conv2d(%3, %v196, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%5 = nn.bias_add(%4, %v197);
%6 = nn.relu(%5);
%7 = nn.conv2d(%6, %v199, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%8 = nn.bias_add(%7, %v200);
%9 = add(%8, %3);
%10 = nn.relu(%9);
%11 = nn.conv2d(%10, %v202, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%12 = nn.bias_add(%11, %v203);
%13 = nn.relu(%12);
%14 = nn.conv2d(%13, %v205, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%15 = nn.bias_add(%14, %v206);
%16 = add(%15, %10);
%17 = nn.relu(%16);
%18 = nn.conv2d(%17, %v208, strides=[2, 2], padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%19 = nn.bias_add(%18, %v209);
%20 = nn.relu(%19);
%21 = nn.conv2d(%20, %v211, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%22 = nn.bias_add(%21, %v212);
%23 = nn.conv2d(%17, %v214, strides=[2, 2], padding=[0, 0, 0, 0], kernel_size=[1, 1]);
%24 = nn.bias_add(%23, %v215);
%25 = add(%22, %24);
%26 = nn.relu(%25);
%27 = nn.conv2d(%26, %v217, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%28 = nn.bias_add(%27, %v218);
%29 = nn.relu(%28);
%30 = nn.conv2d(%29, %v220, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%31 = nn.bias_add(%30, %v221);
%32 = add(%31, %26);
%33 = nn.relu(%32);
%34 = nn.conv2d(%33, %v223, strides=[2, 2], padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%35 = nn.bias_add(%34, %v224);
%36 = nn.relu(%35);
%37 = nn.conv2d(%36, %v226, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%38 = nn.bias_add(%37, %v227);
%39 = nn.conv2d(%33, %v229, strides=[2, 2], padding=[0, 0, 0, 0], kernel_size=[1, 1]);
%40 = nn.bias_add(%39, %v230);
%41 = add(%38, %40);
%42 = nn.relu(%41);
%43 = nn.conv2d(%42, %v232, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%44 = nn.bias_add(%43, %v233);
%45 = nn.relu(%44);
%46 = nn.conv2d(%45, %v235, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%47 = nn.bias_add(%46, %v236);
%48 = add(%47, %42);
%49 = nn.relu(%48);
%50 = nn.conv2d(%49, %v238, strides=[2, 2], padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%51 = nn.bias_add(%50, %v239);
%52 = nn.relu(%51);
%53 = nn.conv2d(%52, %v241, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%54 = nn.bias_add(%53, %v242);
%55 = nn.conv2d(%49, %v244, strides=[2, 2], padding=[0, 0, 0, 0], kernel_size=[1, 1]);
%56 = nn.bias_add(%55, %v245);
%57 = add(%54, %56);
%58 = nn.relu(%57);
%59 = nn.conv2d(%58, %v247, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%60 = nn.bias_add(%59, %v248);
%61 = nn.relu(%60);
%62 = nn.conv2d(%61, %v250, padding=[1, 1, 1, 1], kernel_size=[3, 3]);
%63 = nn.bias_add(%62, %v251);
%64 = add(%63, %58);
%65 = nn.relu(%64);
%66 = nn.global_avg_pool2d(%65);
%67 = nn.batch_flatten(%66);
%68 = nn.batch_flatten(%67);
%69 = nn.dense(%68, %fc.weight, units=1000);
%70 = multiply(1f, %fc.bias);
add(%69, %70)
}
可以看到这个mod其实就是一个函数(Relay Function),函数的输入就是ONNX模型中所有输入Tensor的shape信息,不仅包含真实的输入input.1,还包含带权重OP的权重Tensor的shape信息,比如卷积层的weight和bias。对应的mod, params = relay.frontend.from_onnx(onnx_model, shape_dict)这里的params则保存了ONNX模型所有OP的权重信息,以一个字典的形式存放,字典的key就是权重Tensor的名字,而字典的value则是TVM的Ndarry,存储了真实的权重(通过Numpy作为中间数据类型转过来的)。
接下来我们需要对这个计算图模型进行优化,这里我们选择优化的等级为1,最后我们将利用优化的Relay IR执行推理,看看分类结果和Pytorch是否一致。
with tvm.transform.PassContext(opt_level=1):
intrp = relay.build_module.create_executor("graph", mod, tvm.cpu(0), target)
######################################################################
# Execute on TVM
# ---------------------------------------------
dtype = "float32"
tvm_output = intrp.evaluate()(tvm.nd.array(x.astype(dtype)), **params).asnumpy()
print(np.argmax(tvm_output))
输出的结果为282,和Pytorch一致,这样我们就完成了使用TVM部署ONNX模型的任务。
0x2. TVM是如何将ONNX转换成Realy IR的?
下面我们开始谈一谈TVM是如何加载ONNX并将其转换为Realy IR的,也就是上面的mod, params = relay.frontend.from_onnx(onnx_model, shape_dict)这行代码具体做了哪些工作。首先定位到这个函数,在tvm/python/tvm/relay/frontend/onnx.py。我们将注释翻译成中文就比较容易理解:
def from_onnx(model, shape=None, dtype="float32", opset=None, freeze_params=False):
"""将一个ONNX模型转换成一个等价的Relay函数.
ONNX Graph被一个Python的Protobuf对象来表示,伴随着的参数将被自动处理。
然而,ONNX Graph的输入名称是模糊的,混淆了输入和网络权重/偏差,如“1”,“2”。。。
为方便起见,我们将“real”输入名重命名为“input_0”,“input_1”...
并将参数重命名为“param_0”、“param_1”...
默认情况下,ONNX根据动态形状定义模型。ONNX导入器在导入时会保留这种动态性,并且编译器会在编译
时尝试将模型转换为静态形状。 如果失败,则模型中可能仍存在动态操作。 并非所有的TVM kernels当前
都支持动态形状,如果在使用动态kernels时遇到错误,请在ask.tvm.apache.org上提出问题。
参数
----------
model : protobuf 对象
ONNX ModelProto after ONNX v1.1.0
shape : str为key,tuple为value的字典, 可选
计算图的输入shape
dtype : str or dict of str to str
计算图的输入shapes(可能有多个输入,所以可能是str,也可能是字典)
opset : int, 可选
覆盖自动检测的算子集合。
对于一些测试是有用的。
freeze_params: bool
If this parameter is true, the importer will take any provided
onnx input values (weights, shapes, etc) and embed them into the relay model
as Constants instead of variables. This allows more aggressive optimizations
at compile time and helps in making models static if certain inputs represent
attributes relay would traditionally consider compile-time constants.
这段话简单来说就是一旦打开freeze_params这个参数,通过ONNX产生的Relay IR就会把所有可能提
供的输入,包括权重,shape都以常量的方式嵌入到Relay IR中。这有助于编译时优化和产生静态模型。
返回
-------
mod : tvm.IRModule
用于编译的Realy IR
params : dict of str to tvm.nd.NDArray
Relay使用的参数字典,存储权重
"""
try:
import onnx
if hasattr(onnx.checker, "check_model"):
# try use onnx's own model checker before converting any model
try:
onnx.checker.check_model(model)
except Exception as e: # pylint: disable=c-extension-no-member, broad-except
# the checker is a bit violent about errors, so simply print warnings here
warnings.warn(str(e))
except ImportError:
pass
# 一个从pb2.GraphProto复制的helper class,用于处理Relay IR。
g = GraphProto(shape, dtype, freeze_params)
# ONNX模型的GraphProto
graph = model.graph
if opset is None:
try:
opset = model.opset_import[0].version if model.opset_import else 1
except AttributeError:
opset = 1
# Use the graph proto as a scope so that ops can access other nodes if needed.
with g:
mod, params = g.from_onnx(graph, opset)
return mod, params
上面的freeze_params参数,我个人理解就是如果这个参数打开,那么编译出来的静态模型就只能处理用户指定shape的模型。比如一个全卷积网络,原本可以输入任意分辨率,但如何用户指定了的分辨率进行构建Realy IR并将这个参数设置为True,那么在模型推理时如果接收了非长宽的图片就会抛出异常。从上面的函数注释中我们可以发现Realy IR在接收到ONNX模型之后新建了一个GraphProto类来管理 ONNX模型的OP转换以及生成Relay IR。这里面的核心函数就是g.from_onnx(graph, opset),继续跟进,带注释的代码如下:
def from_onnx(self, graph, opset, get_output_expr=False):
"""基于ONNX模型构建Relay IR。
参数
----------
graph : onnx protobuf 对象
加载进来的ONNX Graph
opset : 操作集版本
get_output_expr: bool
如果设置为true,则此转换将返回每个输出表达式,而不是打包的模块。
将子图转换为Relay时,这可能很有用。
Returns
-------
mod : tvm.IRModule
The returned relay module
params : dict
A dict of name: tvm.nd.array pairs, used as pretrained weights
"""
self.opset = opset
# 解析网络的输入到relay中, 又叫参数,onnx的initializer就是用来保存模型参数的
for init_tensor in graph.initializer:
if not init_tensor.name.strip():
raise ValueError("Tensor's name is required.")
# 具体实现就是先把这个TensorProto使用get_numpy函数获得值,再reshape到特定形状,再基于这个numpy构造tvm.nd.array。
array = self._parse_array(init_tensor)
# 前面解释过,如果设置冻结参数,则将这个参数设置为Relay中的常量OP
if self._freeze_params:
self._nodes[init_tensor.name] = _expr.const(array)
else:
self._params[init_tensor.name] = array
self._nodes[init_tensor.name] = new_var(
init_tensor.name,
shape=self._params[init_tensor.name].shape,
dtype=self._params[init_tensor.name].dtype,
)
# 解析ONNX模型的输入
for i in graph.input:
# from onnx v0.2, GraphProto.input has type ValueInfoProto,
# and the name is 'i.name'
# 获取i这个输入的名字,shape,数据类型以及shape每个维度对应的名字
i_name, i_shape, d_type, i_shape_name = get_info(i)
# 判断i这个输入是权重参数还是输入
if i_name in self._params:
# i is a param instead of input
self._num_param += 1
self._params[i_name] = self._params.pop(i_name)
self._nodes[i_name] = new_var(
i_name, shape=self._params[i_name].shape, dtype=self._params[i_name].dtype
)
# 输入节点已经在Relay IR中了就不用处理了
elif i_name in self._nodes:
continue
else:
# 真正的输入节点,依赖用户进行指定
self._num_input += 1
self._input_names.append(i_name)
if i_name in self._shape:
i_shape = self._shape[i_name]
else:
if "?" in str(i_shape):
warning_msg = (
"Input %s has unknown dimension shapes: %s. "
"Specifying static values may improve performance"
% (i_name, str(i_shape_name))
)
warnings.warn(warning_msg)
if isinstance(self._dtype, dict):
dtype = self._dtype[i_name] if i_name in self._dtype else d_type
else:
dtype = d_type
self._nodes[i_name] = new_var(i_name, shape=i_shape, dtype=dtype)
self._inputs[i_name] = self._nodes[i_name]
# Only check user inputs in the outer-most graph scope.
if self._old_manager is None:
assert all(
[name in self._input_names for name in self._shape.keys()]
), "User specified the shape for inputs that weren't found in the graph: " + str(
self._shape
)
# 获取不支持的算子列表
convert_map = _get_convert_map(opset)
unsupported_ops = set()
for node in graph.node:
op_name = node.op_type
if (
op_name not in convert_map
and op_name != "Constant"
and op_name not in _identity_list
):
unsupported_ops.add(op_name)
# 输出不支持的算子集合
if unsupported_ops:
msg = "The following operators are not supported for frontend ONNX: "
msg += ", ".join(unsupported_ops)
raise tvm.error.OpNotImplemented(msg)
# 到这里说明这个ONNX模型的所有算子都被Relay支持,可以正常进行转换了
for node in graph.node:
op_name = node.op_type
# 解析attribute参数
attr = self._parse_attr(node.attribute)
# 创建并填充onnx输入对象。
inputs = onnx_input()
for i in node.input:
if i != "":
# self._renames.get(i, i)用来获取ONNX Graph每个节点的输入
inputs[i] = self._nodes[self._renames.get(i, i)]
else:
inputs[i] = None
i_name = self._parse_value_proto(node)
node_output = self._fix_outputs(op_name, node.output)
attr["tvm_custom"] = {}
attr["tvm_custom"]["name"] = i_name
attr["tvm_custom"]["num_outputs"] = len(node_output)
# 执行转换操作
op = self._convert_operator(op_name, inputs, attr, opset)
# op的输出可能只有一个也可能有多个
if not isinstance(op, _expr.TupleWrapper):
outputs_num = 1
else:
outputs_num = len(op)
if outputs_num > 1:
# ONNX的某些节点支持可选输出
# 这一块在ONNX的Graph中搜索缺失的输出并移除不需要的节点
valid_outputs = [False] * outputs_num
for i, output in enumerate(node_output):
if output != "":
valid_outputs[i] = True
# If we have outputs ONNX isn't expecting, we need to drop them
# 如果我们有ONNX不期望出现的输出,我们需要删除它们
if not all(valid_outputs):
tup = op.astuple()
# TupleWrapper can also wrap ops with TupleType outputs
if isinstance(tup, _expr.Tuple):
# For tuples, we extract the fields instead of using GetTupleItem
outputs = [tup.fields[i] for i, valid in enumerate(valid_outputs) if valid]
else:
# For call nodes, we need to GetTupleItem
outputs = [op[i] for i, valid in enumerate(valid_outputs) if valid]
# Create the new op with valid outputs
if len(outputs) == 1:
op = outputs[0]
else:
op = _expr.TupleWrapper(outputs, len(outputs))
# Drop invalid outputs for the onnx node
outputs_num = len(outputs)
node_output = [output for output in node_output if output != ""]
assert (
len(node_output) == outputs_num
), "Number of output mismatch {} vs {} in {}.".format(
len(node_output), outputs_num, op_name
)
# 输出只有一个有可能是常量OP,可以执行一次常量折叠功能
if outputs_num == 1:
self._nodes[node_output[0]] = fold_constant(op)
else:
op = _expr.TupleWrapper(fold_constant(op.astuple()), len(op))
for k, i in zip(list(node_output), range(len(node_output))):
self._nodes[k] = op[i]
# 解析ONNX模型的输出
outputs = [self._nodes[self._parse_value_proto(i)] for i in graph.output]
outputs = outputs[0] if len(outputs) == 1 else _expr.Tuple(outputs)
# 如果需要直接返回转换后的表达式,在这里return
if get_output_expr:
return outputs
# 保持来自ONNX Graph的输入和参数顺序,但仅仅包含这些需要执行转换到Relay的节点
free_vars = analysis.free_vars(outputs)
nodes = {v: k for k, v in self._nodes.items()}
free_vars = [nodes[var] for var in free_vars]
for i_name in self._params:
if i_name in free_vars and i_name not in self._inputs:
self._inputs[i_name] = self._nodes[i_name]
# 根据我们的输出表达式和所有输入变量创建一个函数。
func = _function.Function([v for k, v in self._inputs.items()], outputs)
# 把这个函数用IRModule包起来返回,并同时返回权重参数
return IRModule.from_expr(func), self._params
通过解析这个函数,我们看到了ONNX Graph是如何被转换成Relay的IR的。在这个函数里面最重要的是对每个OP执行具体转换逻辑的函数,即op = self._convert_operator(op_name, inputs, attr, opset)。我们来看一下这个函数是如何将ONNX的OP转换成Relay IR的。convert_operator的函数定义如下:
def _convert_operator(self, op_name, inputs, attrs, opset):
"""将ONNX的OP转换成Relay的OP
转换器必须为不兼容的名称显式指定转换,并将处理程序应用于运算符属性。
Parameters
----------
op_name : str
Operator 名字, 比如卷积, 全连接
inputs : tvm.relay.function.Function的list
List of inputs.
attrs : dict
OP的属性字典
opset : int
Opset version
Returns
-------
sym : tvm.relay.function.Function
Converted relay function
"""
convert_map = _get_convert_map(opset)
if op_name in _identity_list:
sym = get_relay_op(op_name)(*inputs, **attrs)
elif op_name in convert_map:
sym = convert_map[op_name](inputs, attrs, self._params)
else:
raise NotImplementedError("Operator {} not implemented.".format(op_name))
return sym
这里有一个_get_convert_map可以获取ONNX 特定Opset Version中被TVM支持的OP字典,字典的Key是ONNX OP的类型名字,而字典的Value就是转换之后的Relay IR。
# _convert_map defines maps of name to converter functor(callable)
# for 1 to 1 mapping, use Renamer if nothing but name is different
# use AttrCvt if attributes need to be converted
# for 1 to N mapping(composed), use custom callable functions
# for N to 1 mapping, currently not supported(?)
def _get_convert_map(opset):
return {
# defs/experimental
"Identity": Renamer("copy"),
"Affine": Affine.get_converter(opset),
"BitShift": BitShift.get_converter(opset),
"ThresholdedRelu": ThresholdedRelu.get_converter(opset),
"ScaledTanh": ScaledTanh.get_converter(opset),
"ParametricSoftplus": ParametricSoftPlus.get_converter(opset),
"Constant": Constant.get_converter(opset),
"ConstantOfShape": ConstantOfShape.get_converter(opset),
# 'GivenTensorFill'
"FC": AttrCvt("dense", ignores=["axis", "axis_w"]),
"Scale": Scale.get_converter(opset),
# 'GRUUnit'
# 'ATen'
# 'ImageScaler'
# 'MeanVarianceNormalization'
# 'Crop'
# 'Embedding'
"Upsample": Upsample.get_converter(opset),
"SpatialBN": BatchNorm.get_converter(opset),
# defs/generator
# 'Constant' # Implemented
# 'RandomUniform'
# 'RandomNormal'
# 'RandomUniformLike'
# 'RandomNormalLike'
# defs/logical
# defs/math
"Add": Add.get_converter(opset),
"Sub": Sub.get_converter(opset),
"Mul": Mul.get_converter(opset),
"Div": Div.get_converter(opset),
"Neg": Renamer("negative"),
"Abs": Absolute.get_converter(opset),
"Reciprocal": Reciprocal.get_converter(opset),
"Floor": Renamer("floor"),
"Ceil": Renamer("ceil"),
"Round": Renamer("round"),
"IsInf": Renamer("isinf"),
"IsNaN": Renamer("isnan"),
"Sqrt": Renamer("sqrt"),
"Relu": Renamer("relu"),
"LeakyRelu": Renamer("leaky_relu"),
"Selu": Selu.get_converter(opset),
"Elu": Elu.get_converter(opset),
"Exp": Renamer("exp"),
"Greater": Greater.get_converter(opset),
"Less": Less.get_converter(opset),
"Log": Renamer("log"),
"Acos": Renamer("acos"),
"Acosh": Renamer("acosh"),
"Asin": Renamer("asin"),
"Asinh": Renamer("asinh"),
"Atan": Renamer("atan"),
"Atanh": Renamer("atanh"),
"Cos": Renamer("cos"),
"Cosh": Renamer("cosh"),
"Sin": Renamer("sin"),
"Sinh": Renamer("sinh"),
"Tan": Renamer("tan"),
"Tanh": Renamer("tanh"),
"Pow": Renamer("power"),
"PRelu": Prelu.get_converter(opset),
"Sigmoid": Renamer("sigmoid"),
"HardSigmoid": HardSigmoid.get_converter(opset),
"Max": Maximum.get_converter(opset),
"Min": Minimum.get_converter(opset),
"Sum": Sum.get_converter(opset),
"Mean": Mean.get_converter(opset),
"Clip": Clip.get_converter(opset),
"Softplus": Softplus.get_converter(opset),
# softmax default axis is different in onnx
"Softmax": Softmax.get_converter(opset),
"LogSoftmax": LogSoftmax.get_converter(opset),
"OneHot": OneHot.get_converter(opset),
# 'Hardmax'
"Softsign": Softsign.get_converter(opset),
"Gemm": Gemm.get_converter(opset),
"MatMul": MatMul.get_converter(opset),
"Mod": Mod.get_converter(opset),
"Xor": Renamer("logical_xor"),
# defs/nn
"AveragePool": AveragePool.get_converter(opset),
"LpPool": LpPool.get_converter(opset),
"MaxPool": MaxPool.get_converter(opset),
"MaxUnpool": MaxUnpool.get_converter(opset),
"Conv": Conv.get_converter(opset),
"ConvTranspose": ConvTranspose.get_converter(opset),
"GlobalAveragePool": Renamer("global_avg_pool2d"),
"GlobalMaxPool": Renamer("global_max_pool2d"),
"BatchNormalization": BatchNorm.get_converter(opset),
"InstanceNormalization": InstanceNorm.get_converter(opset),
# 'LpNormalization'
"Dropout": AttrCvt("dropout", {"ratio": "rate"}, ignores=["is_test"]),
"Flatten": Flatten.get_converter(opset),
"LRN": LRN.get_converter(opset),
# Recurrent Layers
"LSTM": LSTM.get_converter(opset),
"GRU": GRU.get_converter(opset),
# defs/vision
"MaxRoiPool": MaxRoiPool.get_converter(opset),
"RoiAlign": RoiAlign.get_converter(opset),
"NonMaxSuppression": NonMaxSuppression.get_converter(opset),
# defs/reduction
"ReduceMax": ReduceMax.get_converter(opset),
"ReduceMin": ReduceMin.get_converter(opset),
"ReduceSum": ReduceSum.get_converter(opset),
"ReduceMean": ReduceMean.get_converter(opset),
"ReduceProd": ReduceProd.get_converter(opset),
"ReduceLogSumExp": ReduceLogSumExp.get_converter(opset),
"ReduceLogSum": ReduceLogSum.get_converter(opset),
"ReduceSumSquare": ReduceSumSquare.get_converter(opset),
"ReduceL1": ReduceL1.get_converter(opset),
"ReduceL2": ReduceL2.get_converter(opset),
# defs/sorting
"ArgMax": ArgMax.get_converter(opset),
"ArgMin": ArgMin.get_converter(opset),
"TopK": TopK.get_converter(opset),
# defs/tensor
"Cast": Cast.get_converter(opset),
"Reshape": Reshape.get_converter(opset),
"Expand": Expand.get_converter(opset),
"Concat": Concat.get_converter(opset),
"Split": Split.get_converter(opset),
"Slice": Slice.get_converter(opset),
"Transpose": AttrCvt("transpose", {"perm": "axes"}),
"DepthToSpace": DepthToSpace.get_converter(opset),
"SpaceToDepth": SpaceToDepth.get_converter(opset),
"Gather": Gather.get_converter(opset),
"GatherElements": GatherElements.get_converter(opset),
"GatherND": GatherND.get_converter(opset),
"Size": AttrCvt("ndarray_size", extras={"dtype": "int64"}),
"Scatter": Scatter.get_converter(opset),
"ScatterElements": Scatter.get_converter(opset),
"Squeeze": AttrCvt("squeeze", {"axes": "axis"}),
"Unsqueeze": Unsqueeze.get_converter(opset),
"Pad": Pad.get_converter(opset),
"Shape": Shape.get_converter(opset),
"Sign": Sign.get_converter(opset),
"Equal": Equal.get_converter(opset),
"Not": Not.get_converter(opset),
"And": And.get_converter(opset),
"Tile": Tile.get_converter(opset),
"Erf": Erf.get_converter(opset),
"Where": Where.get_converter(opset),
"Or": Or.get_converter(opset),
"Resize": Resize.get_converter(opset),
"NonZero": NonZero.get_converter(opset),
"Range": Range.get_converter(opset),
"CumSum": CumSum.get_converter(opset),
# defs/control_flow
"Loop": Loop.get_converter(opset),
"If": If.get_converter(opset),
# Torch ATen Dispatcher.
"ATen": ATen.get_converter(opset),
# Quantization
"QuantizeLinear": QuantizeLinear.get_converter(opset),
"DequantizeLinear": DequantizeLinear.get_converter(opset),
"DynamicQuantizeLinear": DynamicQuantizeLinear.get_converter(opset),
}
我们以卷积层为例来看看ONNX的OP是如何被转换成Relay表达式的。卷积OP一般有输入,权重,偏置这三个项,对应了下面函数中的inputs[0],inputs[1],inputs[2]。而auto_pad这个属性是ONNX特有的属性,TVM的Relay 卷积OP不支持这种属性,所以需要将ONNX 卷积OP需要Pad的数值计算出来并分情况进行处理(这里有手动对输入进行Pad以及给Relay的卷积OP增加一个padding参数两种做法,具体问题具体分析)。然后需要注意的是在这个转换函数中inputs[0]是Relay IR,而不是真实的数据,我们可以通过打印下面代码中的inputs[0]看到。
class Conv(OnnxOpConverter):
"""Operator converter for Conv."""
@classmethod
def _impl_v1(cls, inputs, attr, params):
# Use shape of input to determine convolution type.
data = inputs[0]
input_shape = infer_shape(data)
ndim = len(input_shape)
if "auto_pad" in attr:
attr["auto_pad"] = attr["auto_pad"].decode("utf-8")
if attr["auto_pad"] in ("SAME_UPPER", "SAME_LOWER"):
# Warning: Convolution does not yet support dynamic shapes,
# one will need to run dynamic_to_static on this model after import
data = autopad(data, attr["strides"], attr["kernel_shape"], attr["dilations"], ndim)
elif attr["auto_pad"] == "VALID":
attr["pads"] = tuple([0 for i in range(ndim - 2)])
elif attr["auto_pad"] == "NOTSET":
pass
else:
msg = 'Value {} in attribute "auto_pad" of operator Conv is invalid.'
raise tvm.error.OpAttributeInvalid(msg.format(attr["auto_pad"]))
attr.pop("auto_pad")
out = AttrCvt(
op_name=dimension_picker("conv"),
transforms={
"kernel_shape": "kernel_size",
"dilations": ("dilation", 1),
"pads": ("padding", 0),
"group": ("groups", 1),
},
custom_check=dimension_constraint(),
)([data, inputs[1]], attr, params)
use_bias = len(inputs) == 3
if use_bias:
out = _op.nn.bias_add(out, inputs[2])
return out
然后这个函数里面还有一个AttrCvt类,是用来做属性转换的,即上面提到的将ONNX Graph中OP的属性对应转换到TVM Relay的OP属性。最后如果卷积层有Bias,则使用_op.nn.bias_add将Bias加上去,注意这个OP返回的仍然是一个Relay表达式。
其它的OP处理类似卷积OP,做完所有ONNX的OP 一对一转换之后我们就可以获得第二节中的Relay IR和权重参数了,即这行代码:mod, params = relay.frontend.from_onnx(onnx_model, shape_dict)。
0x3. 在TVM中新增OP
现在我们已经知道TVM是如何将ONNX转换成Realy IR的了,那么如果我们在适配自定义模型的时候某些OP TVM还不支持怎么办?这个时候就需要我们自定义OP了,自定义OP的方式可以是基于已有的OP进行拼接,也可以在TVM中独立实现这个OP,然后再在前端新增转换接口。这里以SeLU为例简单介绍新增OP需要做什么?
首先我们需要实现一个SeLU Class,这个类继承了OnnxOpConverter,然后实现_impl_v1方法,代码如下:
class Selu(OnnxOpConverter):
"""Operator converter for Selu."""
@classmethod
def _impl_v1(cls, inputs, attr, params):
alpha = float(attr.get("alpha", 1.6732))
gamma = float(attr.get("gamma", 1.0507))
return _expr.const(gamma) * (
_expr.const(-alpha) * _op.nn.relu(_expr.const(1.0) - _op.exp(inputs[0]))
+ _op.nn.relu(inputs[0])
)
可以看到这里是基于一些常用的算子按照SeLU的公式来拼出这个OP,在实现了这个转换逻辑之后,我们需要将这个OP注册到_convert_map中,即在_get_convert_map新增一行:"Selu": Selu.get_converter(opset),,然后保存源码重新编译TVM即可。这里新增SeLU类继承的OnnxOpConverter类实现如下:
class OnnxOpConverter(object):
"""A helper class for holding onnx op converters."""
@classmethod
def get_converter(cls, opset):
"""获取匹配给定的算子集合的转换器
Parameters
----------
opset: int
opset from model.
Returns
-------
converter, which should be `_impl_vx`. Number x is the biggest
number smaller than or equal to opset belongs to all support versions.
"""
# 这里的_impl_v_xxx方法是每个OP的具体实现方法,xxx代表版本,对应ONNX的Opset Version
versions = [int(d.replace("_impl_v", "")) for d in dir(cls) if "_impl_v" in d]
versions = sorted(versions + [opset])
version = versions[max([i for i, v in enumerate(versions) if v == opset]) - 1]
if hasattr(cls, "_impl_v{}".format(version)):
return getattr(cls, "_impl_v{}".format(version))
raise NotImplementedError(
"opset version {} of {} not implemented".format(version, cls.__name__)
)
重新编译完TVM之后就可以对我们的自定义模型完成部署了,从模型部署的角度来看,TVM还是挺易用的。
0x4. 总结
这篇文章主要是探索了TVM中是如何用Relay的前端接口将ONNX模型加载进行TVM并吐出Relay IR的,并且还给出了要支持ONNX自定义的OP应该怎么做。其实在TVM中支持编译很多的DL框架,在下图可以看到:
其实它们的前端交互过程和ONNX也大同小异,希望对TVM感兴趣的读者在阅读这篇文章之后对新增OP,甚至是在TVM中支持一种新的DL框架有一个整体把握。
0x5. 推荐阅读
ONNX初探 ONNX 再探 onnx2pytorch和onnx-simplifier新版介绍 onnx simplifier 和 optimizer 深度学习框架OneFlow是如何和ONNX交互的? 【从零开始学深度学习编译器】一,深度学习编译器及TVM 介绍 【从零开始学深度学习编译器】二,TVM中的scheduler
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信: