
(附论文)斯坦福助理教授马腾宇:ML非凸优化很难,如何破?
点击左上方蓝字关注我们

第一章:非凸函数的基本内容;
第二章:分析技术,包括收敛至局部极小值、局部最优 VS 全局最优和流形约束优化;
第三章:广义线性模型,包括种群风险分析和经验风险集中;
第四章:矩阵分解问题,包括主成分分析和矩阵补全;
第五章:张量分解,包括正交张量分解的非凸优化和全局最优;
第六章:神经网络优化的综述与展望。

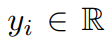 生成自
生成自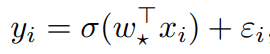 ,其中σ: R→R 是已知的单调激活函数,ε_i∈R 均为独立同分布(i.i.d.)的均值零噪声 (与 x_i 无关),
,其中σ: R→R 是已知的单调激活函数,ε_i∈R 均为独立同分布(i.i.d.)的均值零噪声 (与 x_i 无关),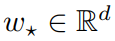 是一个固定的未知真值系数向量。
是一个固定的未知真值系数向量。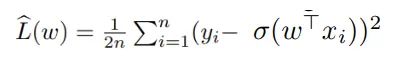 。
。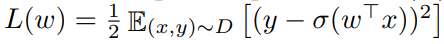 是相应的种群风险(population risk)。
是相应的种群风险(population risk)。 的优化,分析路径包括两个部分:a) 所有种群风险的局部极小值都是全局极小值;b) 经验风险具有同样的属性。不再是凸的。在本节其余部分中,研究者对这个问题进行了规律性假设。为了便于阐述,这些假设比必要的假设更为有力。
的优化,分析路径包括两个部分:a) 所有种群风险的局部极小值都是全局极小值;b) 经验风险具有同样的属性。不再是凸的。在本节其余部分中,研究者对这个问题进行了规律性假设。为了便于阐述,这些假设比必要的假设更为有力。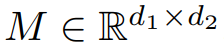 ,求其最佳秩 r 逼近(Frobenius 范数或谱范数)。为了便于说明,研究者取
,求其最佳秩 r 逼近(Frobenius 范数或谱范数)。为了便于说明,研究者取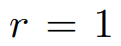 ,并假设 M 是维数为 d×d 的对称半正定。在这种情况下,最佳秩 1 近似的形式为
,并假设 M 是维数为 d×d 的对称半正定。在这种情况下,最佳秩 1 近似的形式为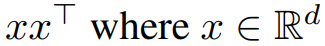 。
。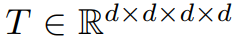 ,它具有低秩结构,即:
,它具有低秩结构,即:
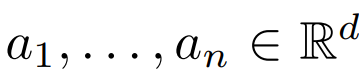 。研究者的目的是恢复底层组件 a_1, . . . , a_n。他假设 a_1, . . . , a_n 是单位范数 R^d 中的正交向量,则目标函数为:
。研究者的目的是恢复底层组件 a_1, . . . , a_n。他假设 a_1, . . . , a_n 是单位范数 R^d 中的正交向量,则目标函数为:

END
整理不易,点赞三连↓
评论