
【数据竞赛】Kaggle知识点:入门到进阶的10个问题
Kaggle知识点
答案是肯定有,大部分Kaggle赛题都是相通或者类似的,还有一些通用的问题。
首先参加Kaggle竞赛,你需要知道有哪些具体的比赛类型。具体分类如下图所示,当然有多种分类方法。
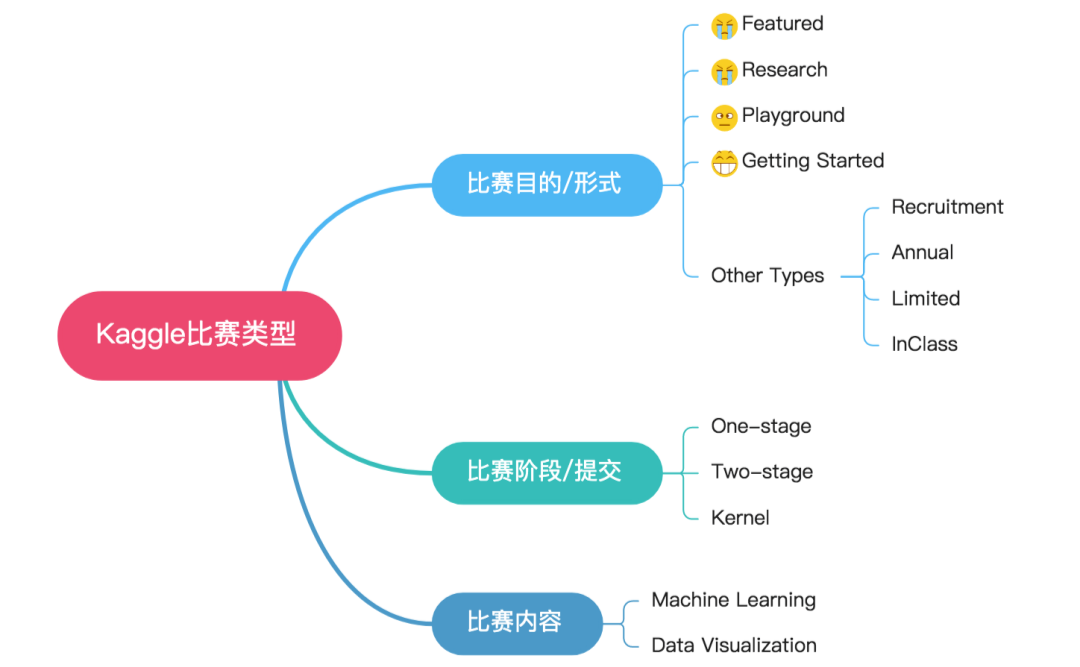
最为主要的类型区别有:
赛题的提交方式(提交结果、Kernel)
赛题问题类型(CV、NLP或结构化)
在确定好赛题类型后,你应该仔细阅读赛题的Overview界面弄清楚的赛题的具体问题。当然赛题描述不会很明确的说出赛题具体问题,需要选手自行进行分辨。
在回答问题2时,需要弄清楚:
赛题是CV、NLP还是结构化中的哪一种?
赛题对应于学术问题的中哪一种?
赛题我之前见过吗?有代码或知识的积累?
Kaggle有类似赛题任务吗,有选手分享吗?
问题有不同的建模方式,哪一种更加适合?
问题建模应该使用哪一个模型?
问题模型如何迭代,如何优化?
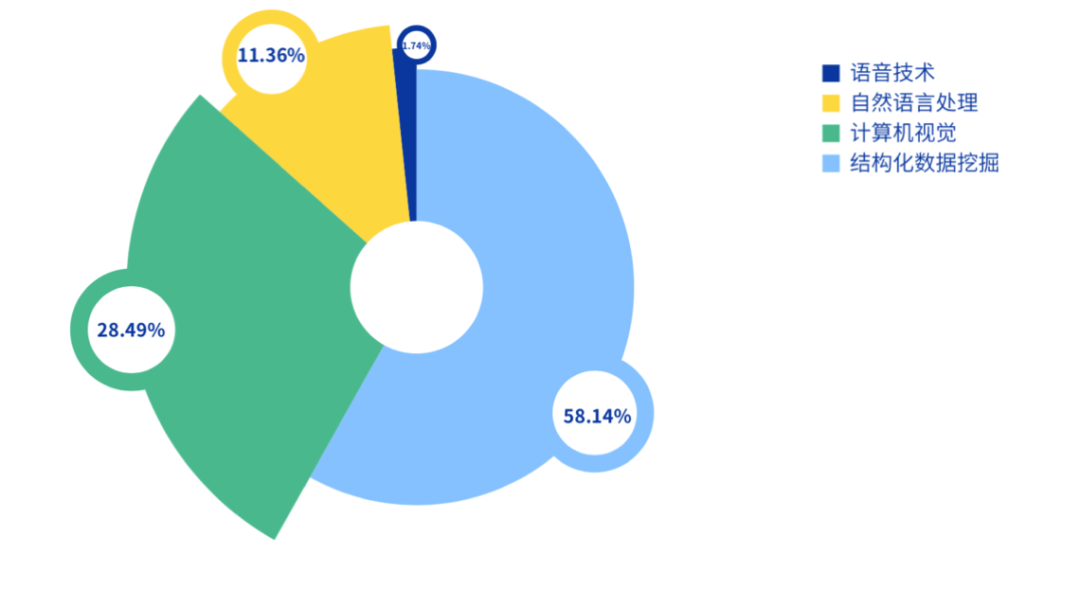
在了解了赛题的初步的任务和建模方法后,接下来就要深入到细节中了。你应该深入理解赛题数据的字段含义、字段产生方式和标签的产生方式。
字段的类型、含义是什么
字段与标签有什么关系?
在回答问题4时,可以从描述性数据分析和探索性数据分析两个角度来完成。赛题的理解决定了赛题的具体建模方式,是尤为关键的一点。
问题5与问题3有点类似,但在问题5你应该回答的更加具体,
赛题具体使用到的模型是什么?
模型有哪些超参数可供选择?
有类似模型可以对比参考吗?
在回答问题5时,需要根据问题4的答案来进行接解决。首先根据赛题具体的数据类型,可以将赛题分为结构化赛题和非机构化赛题。同时在回答问题5时,你应该跑通或者写完baseline了。
如果模型是欠拟合你应该做什么?
如果模型是过拟合你应该做什么?

当你回答完前面6个问题后,基本上你已经提交过一次答案,已经成功上榜了。但是这些还不够,与前排选手相比你的模型精度还有待优化。
前排选手与自己的精度差异在哪儿?
自己还能从哪些地方上分?
回答问题7最好的方法是阅读比赛论坛和相关论文,当然这些问题的具体答案只能自己回答自己了。从问题7开始,你开始真正的竞赛探索过程。
寻找更好的本地CV得分;
寻找更加问题的gap;
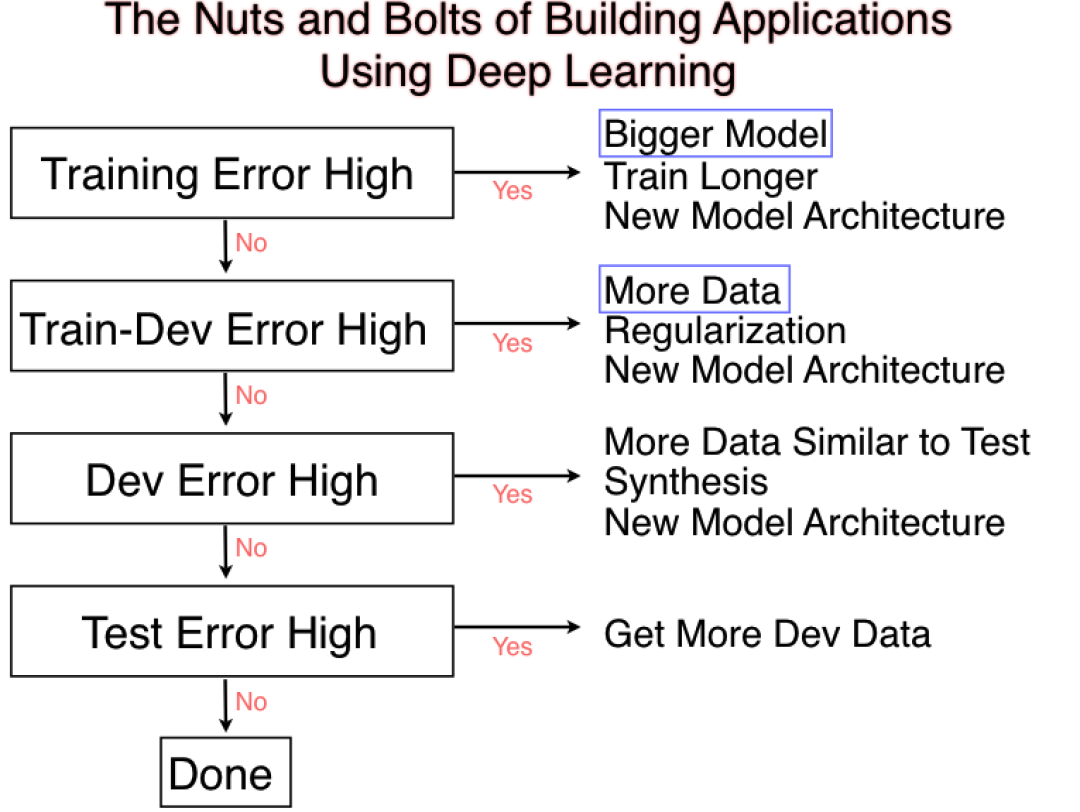
但是模型集成是需要得分差异性,需要训练多个模型的:
如何完成stacking和简单的KFlod平均?
深度学习模型如何完成模型集成?
通过本次比赛我学习到什么?
我与前排选手差异在哪儿?
遇到下次类似比赛,我将如何行动?

往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):