
HPC存储份额和全球超算进展(附报告)


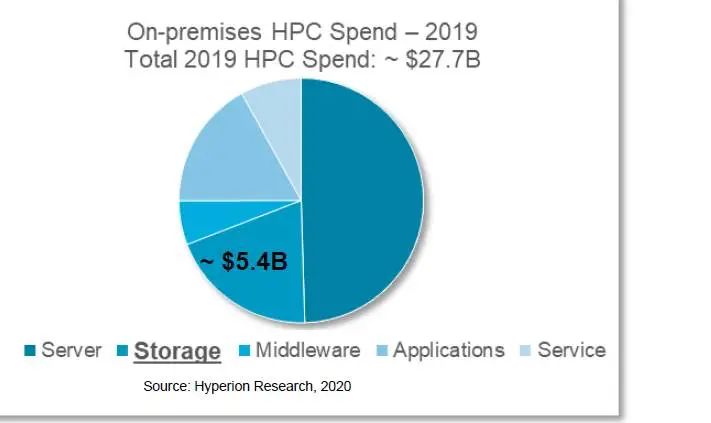
从存储和网络细分市场来看,存储是HPC最具吸引力,也是历史上增长最快的高性能计算系统部件(CAGR 8.4%),存储占HPC支出的20%左右;每花1美元在计算上,大约就要花0.4美元在存储上。
Hyperion Research发布更新HPC市场总结和未来预测报告,前期内容参考“2020年HPC市场总结和预测报告(附下载)”,报告下载链接:2020年HPC市场总结和预测报告
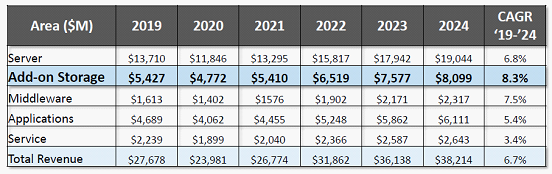
Dell EMC、IBM、HPE/Cray和DDN位列HPC存储市场前四,排名第一的Dell EMC份额占26.3%,同时也是学术科研和工业领域份额领先者;HPE/Cray排名第三,但在政府行业排名第一。
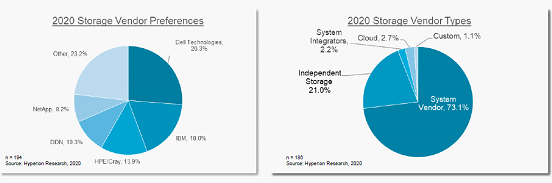
Hyperion Research把存储厂商系统集成商、系统提供商、独立存储提供商、云厂商和客户自己提供等类型,大部分存储厂商都是系统提供商(占73.1%),如Dell EMC,IBM和HPE等;前四名中只有DDN是独立存储提供商(存储份额占10.3%)。
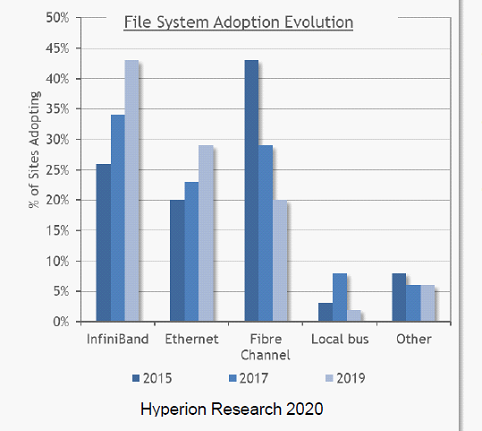
从HPC并行文件分析数据看(三年数据),NFS市场占有率最高,但在逐年迅速下滑,Lustre、Spectrum Scale/GPFS和HDFS迅速增长,Lustre市场占有率最高。GFS、Ceph和PanFS市场占有率比较低,Hyperion Research把他们放到Other中统计。
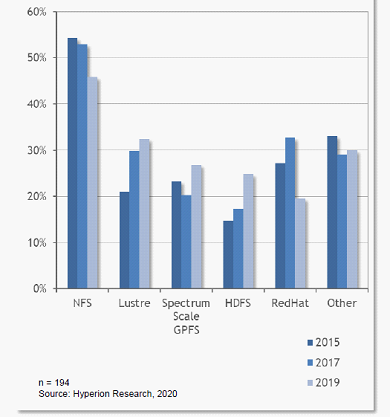
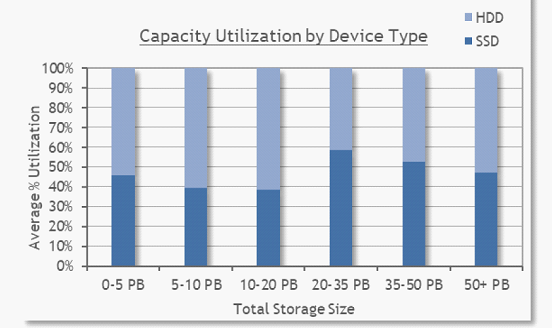
Lustre在学术研究和政府研究中应用最多,工业制造主要采用NFS。在存储介质方面,SSD将成为主流选择;2019年从调研的站点部署来看,45%的存储容量采用SSD介质;86%的站点部署了闪存存储,其中15%的站点部署全闪存,71%混合部署,14%全HDD部署。
在网络互连方面,Infiniband依然是主流选择,但以太网也在迅速增长;从数据看,Infiniband和以太网将是HPC网络未来2大选择;FC、Local Bus等互联技术不断萎缩。
未来HPC网络互连除了提供高带宽外,对基于GPU或其他硬件加速的AI等应用性能优化,数据线下云上流动和边缘计算需求提出更高要求和挑战。
超算系统的布局也是全球行为,美国在3大超算系统(Aurora、Frontier和EI Capitan)近两年投入预算均超过18亿美元。

Aurora:英特尔推迟推出7纳米的Ponte Vecchio GPU,计划在Aurora与英特尔Xeon CUP集成,算力>1EF。
Intel disclosed delay of 7nm Ponte Vecchio GPU, planned to be
integrated with Intel Xeon CPUs in Aurora
•>1 EF
•Compute Node (est. total 2,400 total Aurora nodes)
2 Intel Xeon scalable “Sapphire Rapids” processors; 10nm+, 8 channel
DDR5 memory, up to 48 cores (<200W)
6 Xe arch based GPUs; Unified Memory Architecture; 8 fabric endpoints
Xe arch based “Ponte Vecchio” GPU; Tile based chiplets , HBM stack,7nm production node
•CPU GPU Interconnect: CPU GPU: PCIe; GPU GPU: Xe Link
•System Interconnect: Cray Slingshot, Dragonfly topology with adaptive routing
•Network Switch: 25.6 Tb/s per switch, from 64 200 Gbs ports (25 GB/s per director)
Focus on Frontier (CORAL-2):美国第一个Exascale System (由于Aurora延期),第二代AI系统;
•>1.5 EF
•Compute node:
1 HPC and AI Optimized AMD EPYC CPU
4 Purpose Built AMD Radeon Instinct GPU
•CPU GPU Interconnect; AMD Infinity Fabric
Coherent memory across the node
•System Interconnect: Cray Slingshot, Multiple (Dragonfly) Slingshot NICs providing 100 GB/s network bandwidth
•Cray Shasta Architecture
•Liquid cooled with 300 kilowatts of power density per cabinet
•Total power = 40 MW (~125 racks)
El Capitan (CORAL-2):
•Compute Node:
One next generation AMD EPYC processor, codenamed Genoa featuring the Zen 4 processor core
Four next generation Radeon Instinct GPUs based on a new compute-optimized architecture for workloads including HPC and AI
•CPU-GPU Interconnect: 3rd Gen AMD Infinity Architecture, including the 3rd Gen AMD Infinity Architecture, unified memory across the CPU and GPU
•System Interconnect: Cray Slingshot, Multiple (Dragonfly) Slingshot NICs providing 100 GB/s network bandwidth
•Cray Shasta Architecture
•Liquid cooled and have an energy budget between 30-to-40 mega watts
日本Fugaku超算系统在2020年6月TOP500榜单中位居榜首。基于Fujitsu A64 ARMv8.2处理器,无GPU加速,Linpack (HPL) 测试基准达 415.5 petaflops。
•High Performance Linpack (HPL) result of 415.5 petaflops
•Uses Fujitsu A64 ARMv8.2-A processor
48/52 compute cores with GPU-like vector extensions
4x 8 GB HBM with 1024 GB/s, on-die Tofu-D network BW (~400 Gbps)
High SVE FLOP/s (3.072 TFLOP/s)
•No GPUs
•158,976 single socket nodes
•Tofu-D bandwidth 10X total global CSP traffic
•Peak DP > 400PFs, Peak SP> 800Pf, Peak HP > 1600 Flops
•Typically 37X faster that predecessor K system on target co-design applications
•Red Hat Enterprise Linux 8 (but Windows as well)
中国三个超算原型机(NUDT、Sugon和Sunway)在开发中,其中一个或多个原型可能被选择为充分生产。

欧洲EuroHPC项目于2018年启动,欧盟32个参与国开发欧盟范围内高性能计算系统,选择芬兰卡贾尼,西班牙巴塞罗那和意大利博洛尼亚,投资6.5亿欧元实施150,200Pflops系统,投资1.8亿欧元建设中规模HPC系统(~4Pflops)

此外,在2022-2023将从采购3个大型系统,至少有一个采用欧盟技术(特别是使用EPI处理器);大约在2027年部署首个混合高性能计算/量子基础设施(Post Exascale System)。
由于篇幅所限,本文分享至此(待分享内容如加黑粗体)。
推荐阅读
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师技术全联盟书店”相关电子书(35本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“架构师技术全店打包汇总(全)”,后续可享全店内容更新“免费”赠阅,价格仅收188元(原总价290元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
