
Meta AI开启「解剖大脑」计划,深度学习瓶颈从自然语言突破
新智元报道
新智元报道
编辑:LRS
【新智元导读】深度学习十年来取得辉煌成就,但其计算、学习效率仍比人类的大脑弱很多。为了突破瓶颈,Meta AI宣布开启一项长期研究计划,以自然语言为切口,比较AI模型和大脑的异同。
近几年,随着大规模预训练语言模型的横空出世,让人类终于有了处理、生成、理解自然语言的能力。
虽然模型已经在部分NLP任务上超越了人类的性能,但要说AI在学习、理解语言的能力和效率已经超越了人类,还为时过早。
拿一个最简单的词「orange」来说,即便是小孩子也能通过几个简单的例子就能掌握这个词既表示「橘子」,也能表示「橙色」,但现代的AI模型往往需要大量的文本、上下文的学习才能达到相同的理解水平。

Yann LeCun曾表示,AI系统未来的发展是能够像动物和人类一样进行学习和推理。
所以除了开发更先进的模型和数据集,也有一大批研究人员在研究人类的大脑以开发一个更强大的AI模型。
MetaAI最近宣布了一项长期研究计划,与神经影像中心NeuroSpin (CEA)和INRIA合作,以更好地了解人类的大脑如何处理语言。

该项目的主要工作是比较AI语言模型和大脑如何响应相同的口语或书面句子,进而将得出的见解和结论用于指导AI模型的开发,使得新模型能够像人类一样高效地处理语音和文本。
早在2019年中,研究人员就已发表了一个多模态神经图像数据集,使用深度学习技术来分析人类在单词和句子处理过程中的脑部活动。

论文链接:https://www.nature.com/articles/s41597-019-0020-y
通过对比大脑和语言模型之间的差异可以发现,与大脑活动最相近的语言模型是那些能从上下文中最好地预测下一个词的模型(例如,once upon a ... ,模型会输出time),和现在的语言模型训练思路相同。基于部分可观察输入的预测是自监督学习(SSL)训练的核心,可能也是理解人类学习语言的关键。
研究人员还发现,大脑中的特定区域可以提前很长时间来预测单词和想法,而大多数现代语言模型通常的训练流程只是用来预测下一个单词。解开人类这种超远距离预测能力的秘密,有助于改善现代人工智能语言模型。
当然,现在的研究还过于表面,对于大脑的功能,我们还有很多不了解的地方,所以研究还需要继续。
这次Meta AI与NeuroSpin的合作正在考虑创建一个原始神经成像数据集来扩大这项研究。未来将开放数据集、深度学习模型、代码,以及由此产生的研究论文,以帮助促进人工智能和神经科学界的发现。
Meta表示,所有工作的终极目的是让AI在有限的甚至无监督的情况下学习世界,并达到人类的水平。
深度学习「解剖」大脑
深度学习「解剖」大脑
神经科学家在分析大脑信号时面临着诸多限制,如果不解决,将大脑与人工智能模型进行比较是根本无法实现的。
研究神经元活动和大脑成像是一个时间和资源密集型的过程,需要大量的机器来分析神经元活动,而这些活动往往是不透明和嘈杂的。
设计语言实验,以控制的方式测量大脑的反应,也需要大量的工作。例如,在经典的语言研究中,句子的复杂性必须匹配,单词的频率或字母数量必须匹配,以便对大脑反应进行有意义的比较。
深度学习的兴起,即多层神经网络一起训练和学习能够缓解这些问题。当志愿者阅读或聆听一个故事时,模型能够高亮大脑中在何处以及何时产生了对单词和句子的感知表征。

深度学习系统需要大量的数据来确保准确性,而功能性磁共振成像(fMRI)研究只能捕捉到一些大脑活动的快照,通常只是来自小规模的样本。
为了满足深度学习所需的大规模数据量,MetaAI的团队不仅使用fMRI对公共数据集记录的成千上万的大脑扫描进行建模,还同时使用脑磁图(MEG)进行建模,这种扫描仪每隔一毫秒就会拍摄大脑活动的快照,比一眨眼还快。
二者结合起来,这些神经成像设备提供了大量的神经成像数据,以检测大脑中激活发生的位置和顺序。这一点也是也是剖析人类认知的算法的关键 。
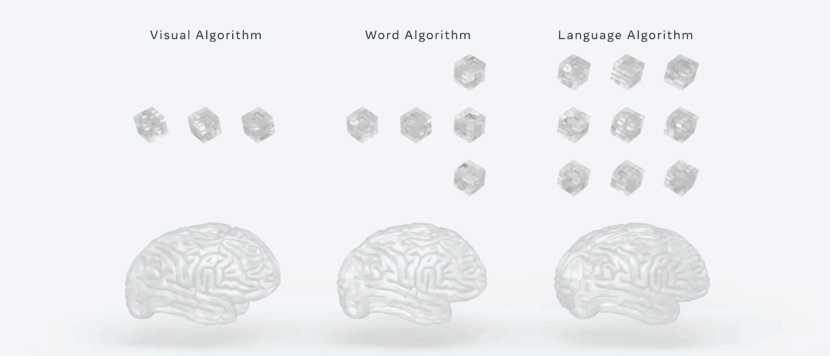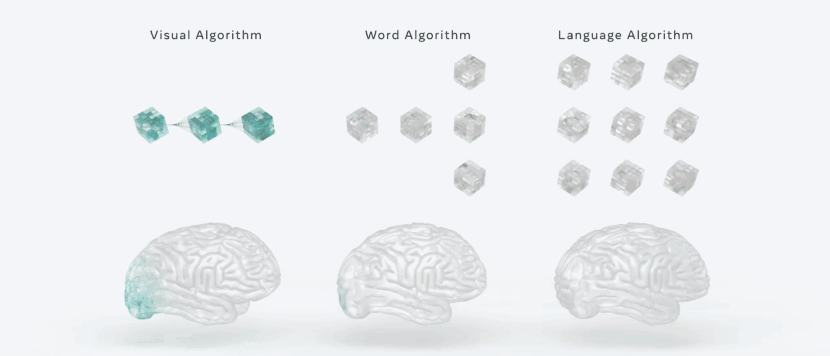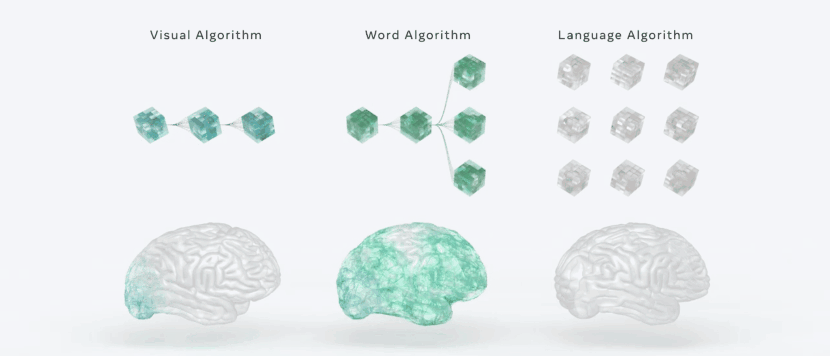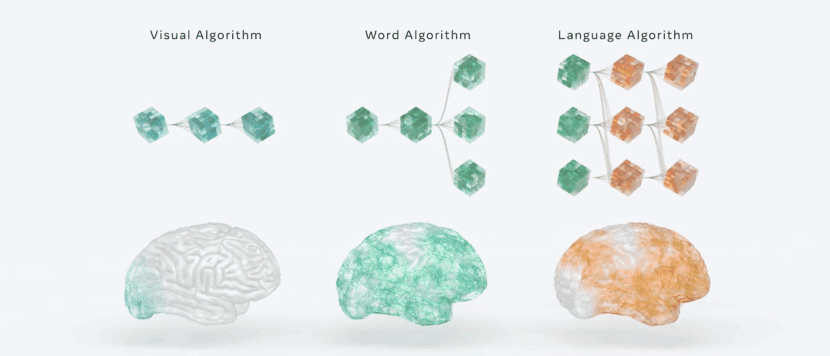
在一些研究结果中可以发现,大脑被系统地组织在一个层次结构中,与人工智能语言模型惊人地相似。例如,语言学家长期以来一直预测,语言处理的特点是,在词语能够被组合成有意义的句子之前,有一连串的感觉和词汇计算。

在深度语言模型和大脑之间的比较精确地验证了这种计算顺序。当阅读一个单词时,大脑首先产生的表征与早期视觉皮层中为识别字符而训练的深度卷积网络相似。
然后这些大脑的激活沿着视觉层次转化为类似于单词嵌入的词汇表征。
最后,分布式皮质网络产生的神经表征与深度语言模型的中间层和最后层相关。
深度学习工具使我们有可能以一种全新的方式解读大脑的层次结构。
「上下文预测」是关键
「上下文预测」是关键
在分析了200个志愿者在阅读文本时产生的大脑激活,并系统性地对比了十来个深度语言模型后,可以发现产生的单词表征和大脑最相关的是「从上下文中预测单词」。
MIT的一个团队后来也独立地发现这个结论,这些相似的研究也证明了使用自监督学习才是通往人类水平AI的正确道路。

但发现大脑和语言模型之间的相似性并不足以抓住语言理解的基本原理,生物神经网络和人工神经网络在计算上的区别也是提升现有模型,构建新的智能模型的关键。
最近Meta AI的研究有证据证明,大脑中的长范围预测(long-range prediction)对于今天的语言模型来说仍然是一个重大挑战。
比如给了一个短语Once upon a ...,大部分语言模型都能够预测出下一个词「time」,而大脑除了一个词之外,还会产生许许多多相关的概念联想,也就是在构建复杂想法、绘图和像人类一样陈述事实等方面仍然面临极大限制。

为了探索这个问题的解决方法,Meta AI与INRIA一起,将多个语言模型与345个志愿者的大脑反馈进行比较,志愿者通过听一些复杂的陈述,将大脑活动用fMRI记录下来。我们可以用长范围预测来增强现有的模型,并追踪大脑的预测。
结果显示,对于特定的大脑区域,比如前额叶(prefrontal)和顶叶(parietal cortices)都能够用来增强语言模型的深度表示来处理长范围预测问题。
总的来说,这些结果支撑了一个相当有前景的研究问题:在大脑和AI模型之间量化相似度。这些相似的研究可以帮助我们了解大脑的功能,提供新的见解,神经科学将指引更智能AI模型的研发。
参考资料:
https://ai.facebook.com/blog/studying-the-brain-to-build-ai-that-processes-language-as-people-do/
