
盘点一个Pandas数据处理基础题目(文末有学习彩蛋)
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python最强王者交流群【Chloe】问了一道Pandas处理的问题,如下图所示。

原始数据如下:
df = pd.DataFrame( {'id' : ['A','A','A','A','A','A','B','B','B','B','B'],
'type' : [1,1,1,1,2,2,1,1,1,2,2],
'book' : ['Math','Math','English','Physics','Math','English','Physics','English','Physics','English','English']})
res = df.groupby(['id','type']).book.apply(list).reset_index()
res['book'] = res.apply(lambda x:(','.join([str(i) for i in x['book']])))
res
预期的结果如下图所示:

二、实现过程
方法一
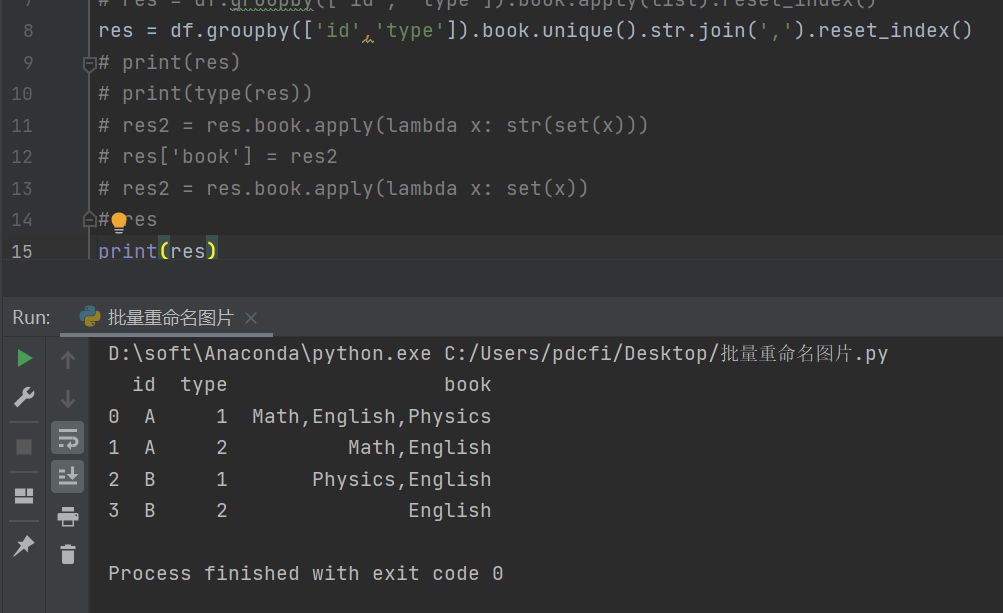
这里【月神】给出一个可行的代码,大家后面遇到了,可以对应的修改下,事半功倍,代码如下所示:
df.groupby(['id','type']).book.unique().str.join(',').reset_index()
运行之后,结果就是想要的了。
方法二
后来【瑜亮老师】也给了一份代码。
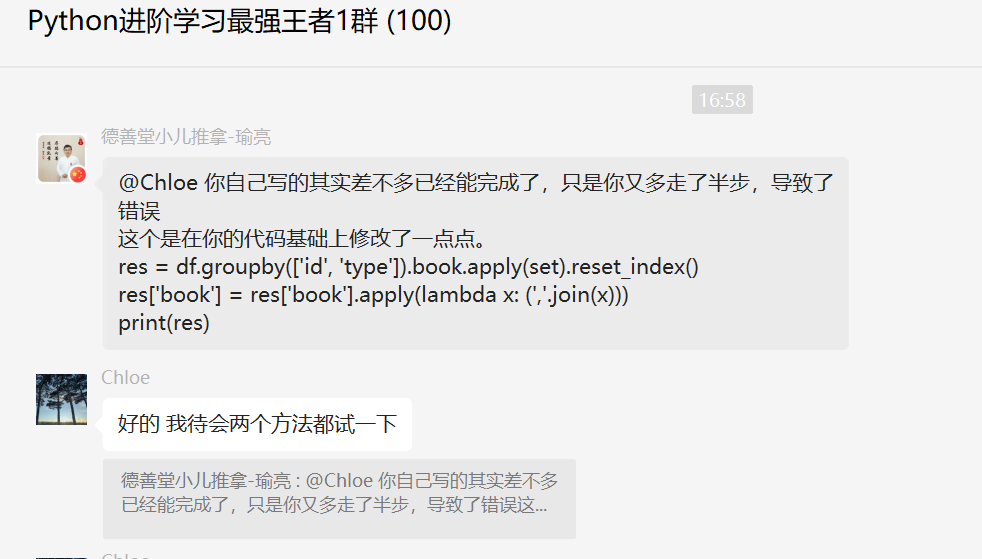
代码如下所示:
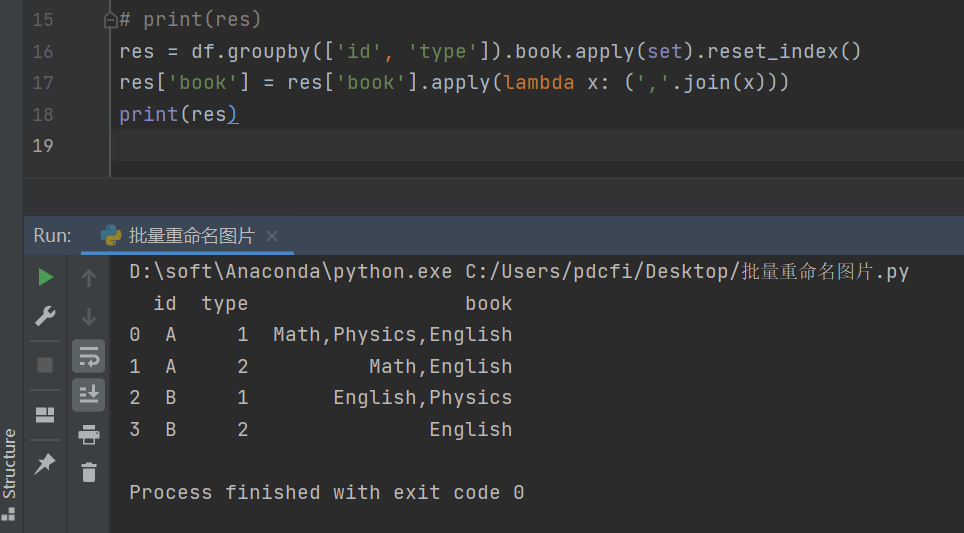
res = df.groupby(['id', 'type']).book.apply(set).reset_index()
res['book'] = res['book'].apply(lambda x: (','.join(x)))
print(res)
运行之后,结果就是想要的了。
完美地解决了粉丝的问题!
最后再给大家分享一个知识点,如下图所示。
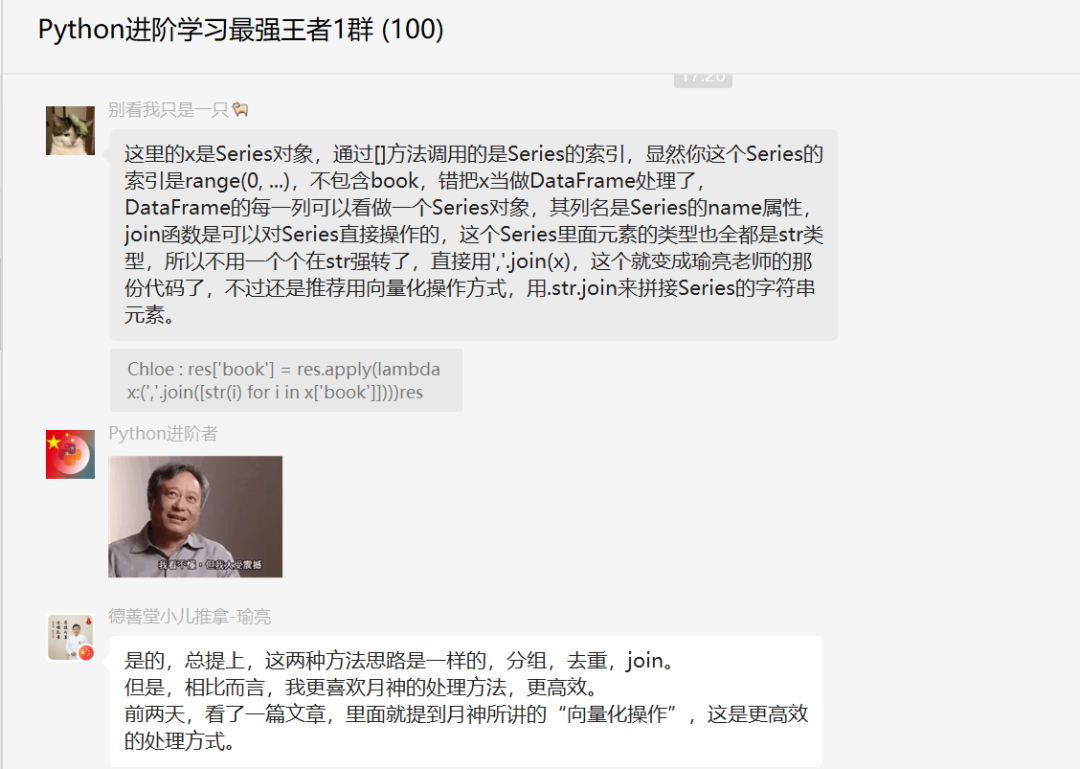
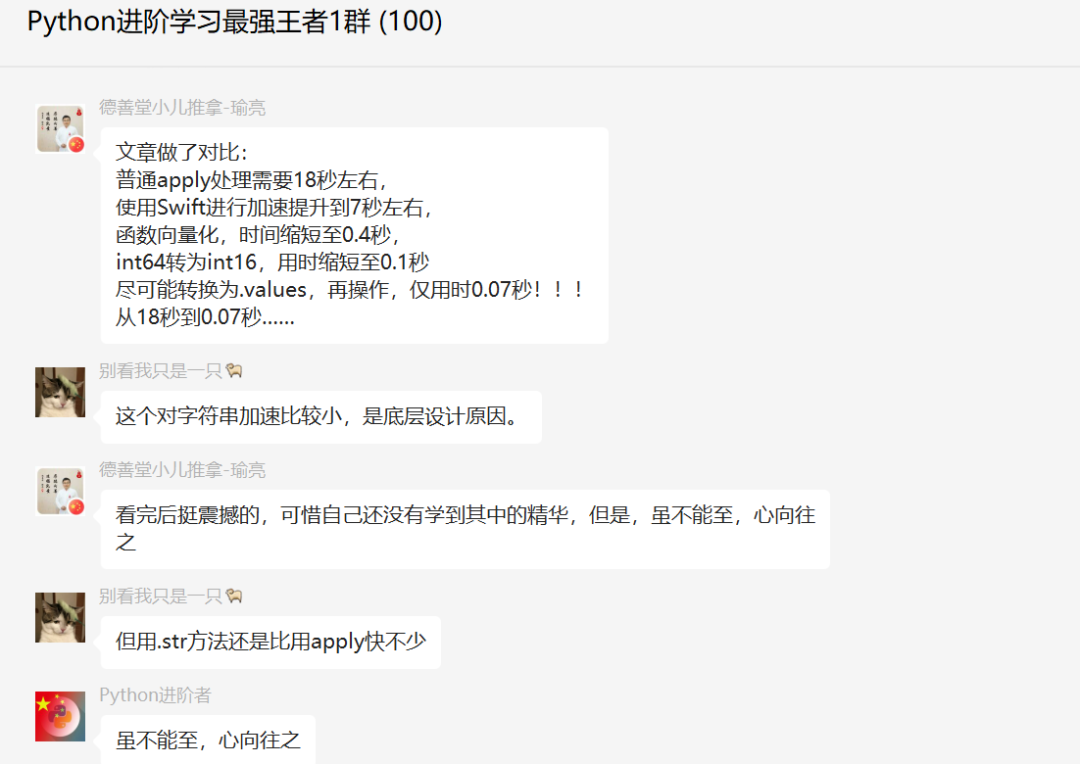
后来【瑜亮老师】还补充了一个结论,这里和大家一起分享下。
文章做了对比:
普通apply处理需要18秒左右,
使用Swift进行加速提升到7秒左右,
函数向量化,时间缩短至0.4秒,
int64转为int16,用时缩短至0.1秒
尽可能转换为.values,再操作,仅用时0.07秒!!!
从18秒到0.07秒……
三、总结
大家好,我是皮皮。这篇文章主要盘点了一道使用Pandas处理数据的问题,文中针对该问题给出了具体的解析和代码实现,一共两个方法,帮助粉丝顺利解决了问题。
最后感谢粉丝【Chloe】提问,感谢【月神】、【瑜亮老师】给出的思路和代码解析,感谢【dcpeng】、【冯诚】、【冷喵】、【D I Y】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论