
盘点一个Python处理的基础题目
大家好,我是皮皮。
一、前言
前几天在Python最强王者交流群【Chloe】问了一道Python处理的问题,如下图所示。

原始数据如下:
origin_lst = [0, 0, 1, 2, 3, 4, 4, 5, 6, 6, 6, 7, 8, 9, 4, 4]
期望得到的结果是:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 4]
二、实现过程
方法一
这里【老松鼠】给了一份代码,如下所示:
import itertools
origin_lst = [0, 0, 1, 2, 3, 4, 4, 5, 6, 6, 6, 7, 8, 9, 4, 4]
final_lst = [x[0] for x in itertools.groupby(origin_lst)]
# final_lst = [k for k, g in itertools.groupby(origin_lst)]
print(final_lst)
运行之后,得到的结果可以满足预期,如下图所示:

方法二
后来【瑜亮老师】也给了一份代码,使用列表推导式,如下所示:
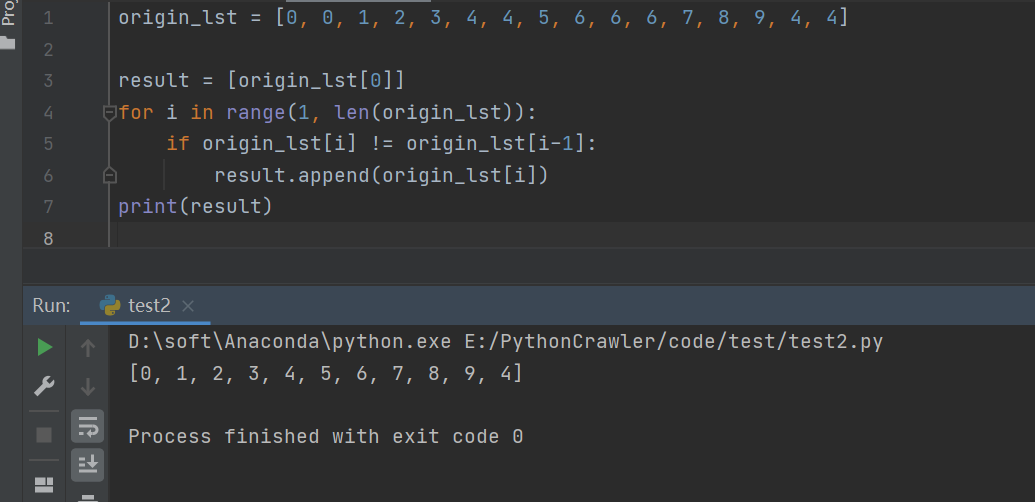
origin_lst = [0, 0, 1, 2, 3, 4, 4, 5, 6, 6, 6, 7, 8, 9, 4, 4]
res = [origin_lst[i] for i in range(len(origin_lst)) if i == 0 or origin_lst[i] != origin_lst[i - 1]]
print(res)
运行结果如下图所示:

顺利的帮助粉丝解决了问题。
方法三
后来在【Siris】给了一个基础的方法,如下所示:
origin_lst = [0, 0, 1, 2, 3, 4, 4, 5, 6, 6, 6, 7, 8, 9, 4, 4]
result = [origin_lst[0]]
for i in range(1, len(origin_lst)):
if origin_lst[i] != origin_lst[i-1]:
result.append(origin_lst[i])
print(result)
运行结果如下图所示:
方法四
后来在【Siris】还给了一个生成器的方法,如下所示:
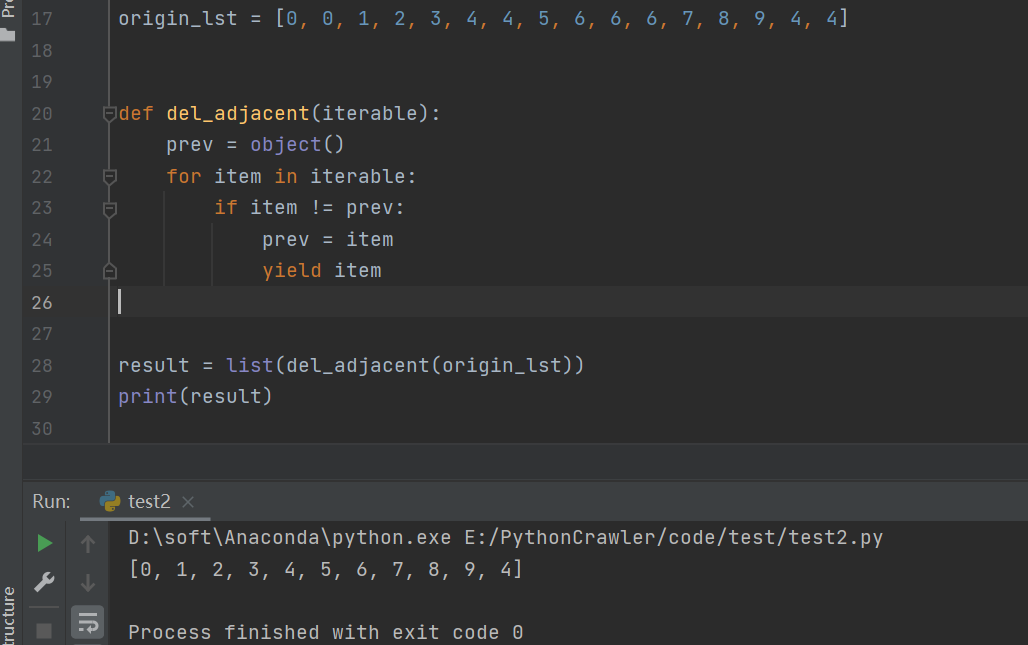
origin_lst = [0, 0, 1, 2, 3, 4, 4, 5, 6, 6, 6, 7, 8, 9, 4, 4]
def del_adjacent(iterable):
prev = object()
for item in iterable:
if item != prev:
prev = item
yield item
result = list(del_adjacent(origin_lst))
print(result)
运行结果如下所示:
方法五
后来【Chloe】自己也给了一个enumerate方法,代码如下所示:
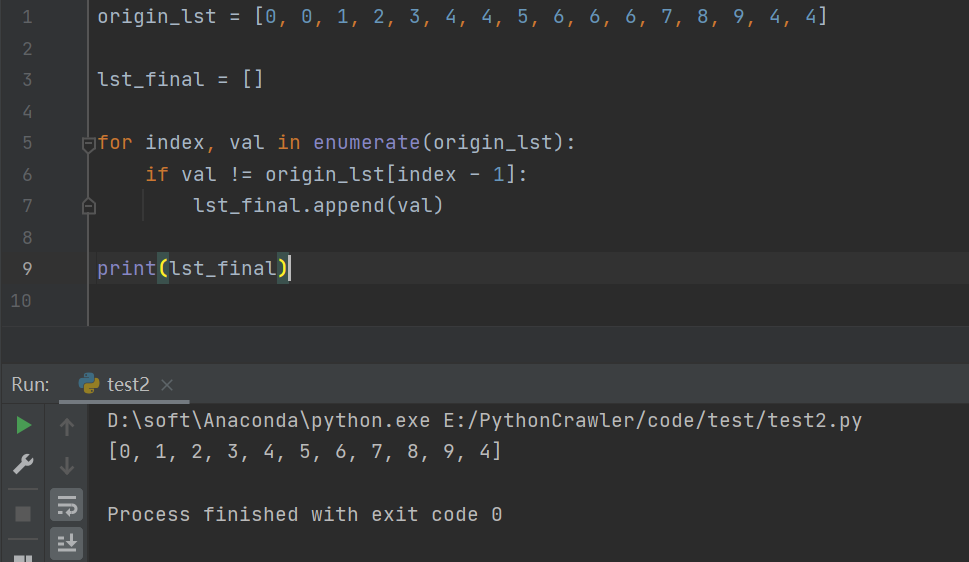
origin_lst = [0, 0, 1, 2, 3, 4, 4, 5, 6, 6, 6, 7, 8, 9, 4, 4]
lst_final = []
for index, val in enumerate(origin_lst):
if val != origin_lst[index - 1]:
lst_final.append(val)
print(lst_final)
运行结果如下图所示:
条条大路通罗马,方法还是很多的!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一道使用Python处理数据的问题,文中针对该问题给出了具体的解析和代码实现,一共两个方法,帮助粉丝顺利解决了问题。
最后感谢粉丝【Chloe】提问,感谢【月神】、【瑜亮老师】、【老松鼠】给出的思路和代码解析,感谢【dcpeng】、【冯诚】、【艾希·觉罗】等人参与学习交流。
评论