
详解 seaborn,快速实现统计数据可视化
哈喽,大家好。
今天详解 Seaborn,它基于 Matplotlib,用来制作统计图形的 Python 库。
Seaborn 的优势:
图表丰富,比 matplotlib 易用 与 pandas 结合 支持数值类型多变量关系图 支持数值类型数据分布图 支持类别类型数据可视化 支持回归模型以及可视化 轻松构建结构化多图网格
我整理了一份 seaborn 核心知识点的思维导图
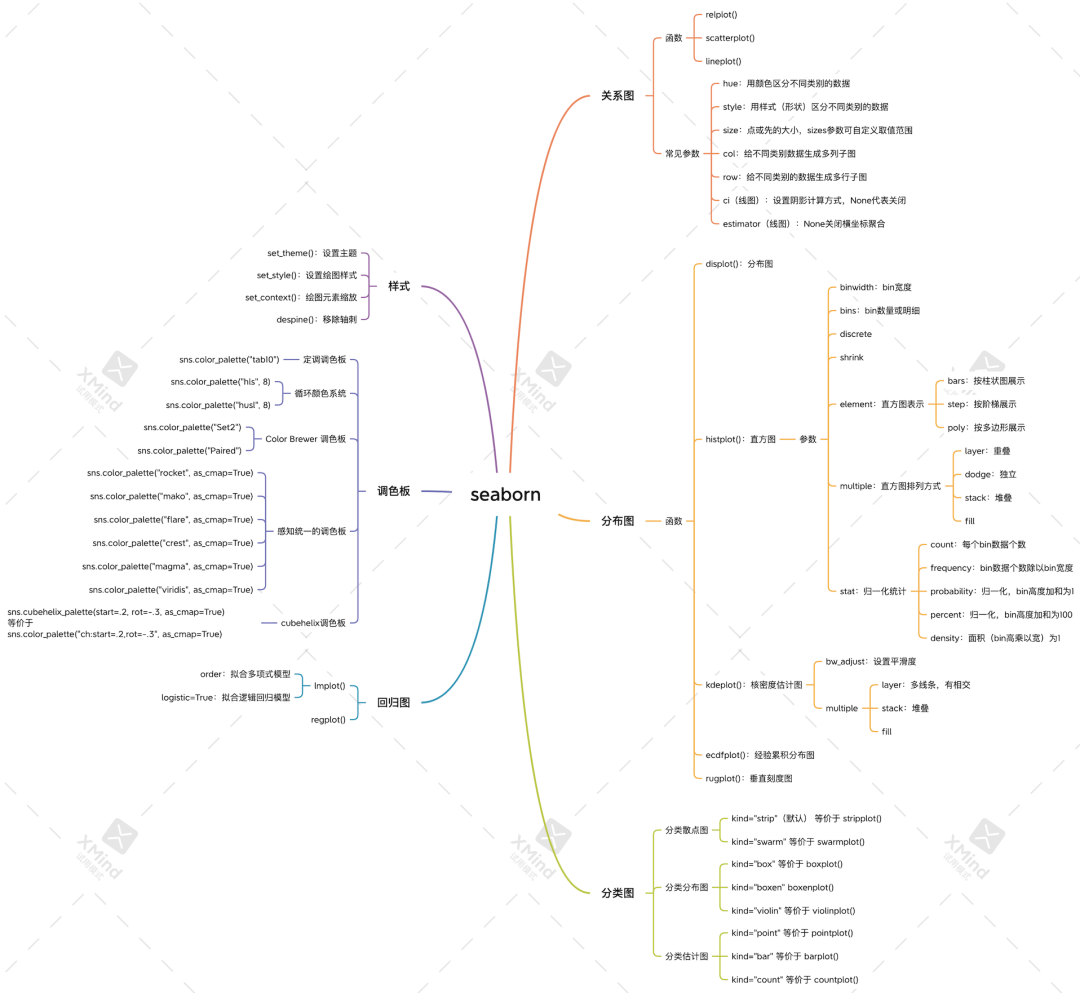
需要的朋友文末回复关键词获取。
下面我们就来学习一下这个强大的 Searborn 。
1. 多变量关系图
多变量关系图其实就是二维散点图和线图,可以通过这些函数来绘制:relplot()、scatterplot()和lineplot()。
scatterplot()只能绘制散点图,lineplot()只能绘制线图。
relplot()都可以绘制,通过kind参数来区分:
kind="scatter"(默认)等价于scatterplot()kind="line"等价于lineplot()
在 seaborn 中,定义一个通用函数并用kind参数指定需要绘制的图形,这种形式很常见。这样做法的好处在于,调用一个函数便可以绘制多种图形。
1.1 绘图
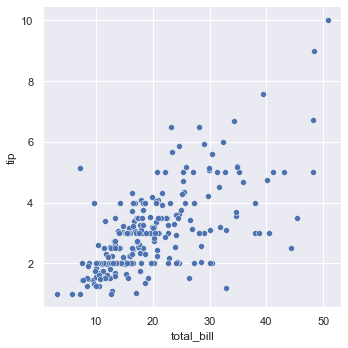
绘制散点图
import seaborn as sns
import pandas as pd
import numpy as np
sns.set_theme(style="darkgrid")
tips = sns.load_dataset("tips", data_home='seaborn-data', cache=True)
sns.relplot(x="total_bill", y="tip", data=tips);
绘制线图
df = pd.DataFrame({'a': range(10), 'b': np.random.randn(10)})
sns.relplot(x="a", y="b", kind="line", data=df)
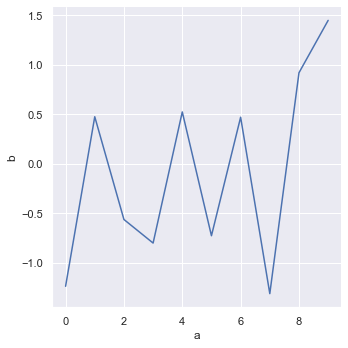
seaborn 可以直接读取 pandas DataFrame中的列作为x轴和y轴,一行代码即可完成绘图,使用比 matplotlib 更容易。
1.2 常用参数
relplot()函数中有一些常用的参数,可以帮助我们绘制更复杂的图形。
以上面散点图为例,设置hue参数,可以为不同类别的点绘制不同的颜色。
sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips);
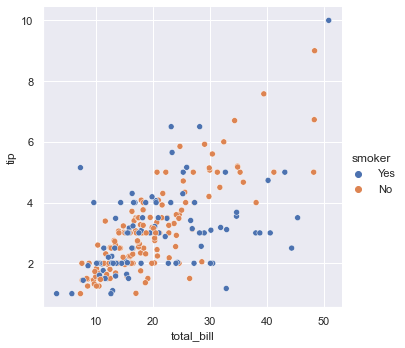
smoker是tips中的一列,取值为Yes和No,上面散点图中smoker=Yes时点是蓝色,smoker=No时,点是橙色。
设置col参数,可以将数据绘制不同的散点图中
sns.relplot(x="total_bill", y="tip", col="smoker", data=tips);
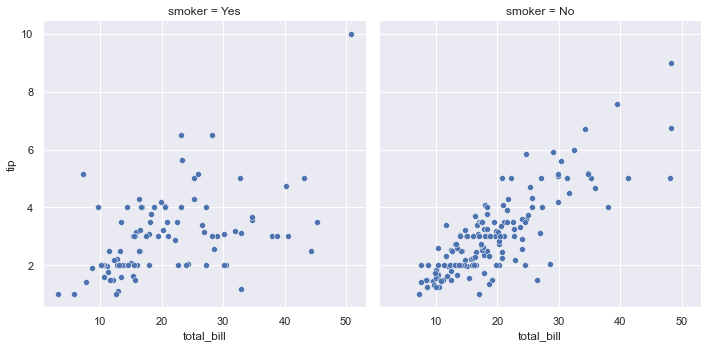
smoker=Yes的数据都绘制在第1行第1列的散点图中;smoker=No的数据都绘制在第1行第2列的散点图中。
设置style参数,可以为不同类别的点绘制不同的形状。
sns.relplot(x="total_bill", y="tip", style="smoker", data=tips);
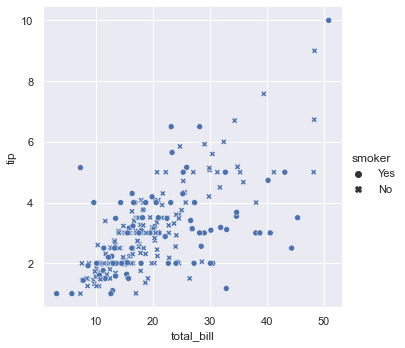
smoker=Yes的是圆点;smoker=No是星号。
下图列举了replot的其他的参数,使用方式与上面类似,这里就不再赘述了。
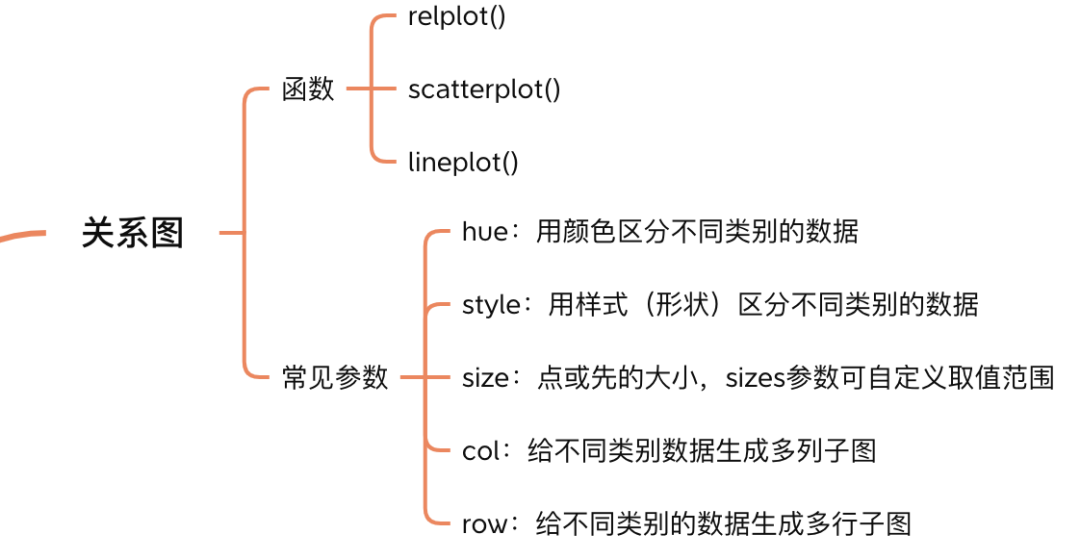
这些参数对线图也同样适用,并且参数之间可以任意组合。
1.3 特殊的线图
上面绘制的线图,横坐标x取值是唯一的,但实际中有些数据横坐标取值不唯一,用relplot()绘制出来是下面的效果。
fmri = sns.load_dataset("fmri", data_home='seaborn-data', cache=True)
sns.relplot(x="timepoint", y="signal", kind="line", data=fmri);
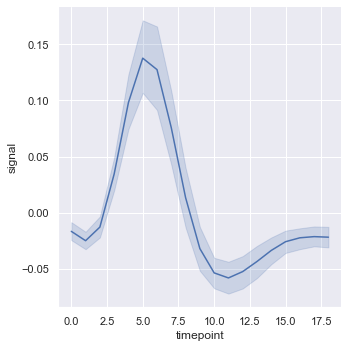
蓝色实线是x的平均值,周围的阴影是平均值的 95% 置信区间。
周围阴影可以通过ci参数设置,如:ci='sd'表示绘制标准差,而不是置信区间。
sns.relplot(x="timepoint", y="signal", kind="line", ci='sd', data=fmri);
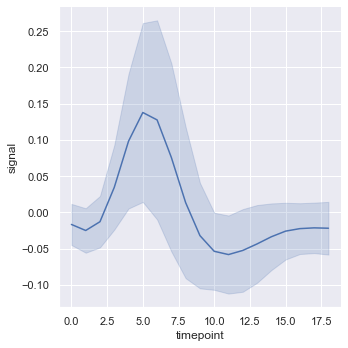
ci=None可以不显示阴影。
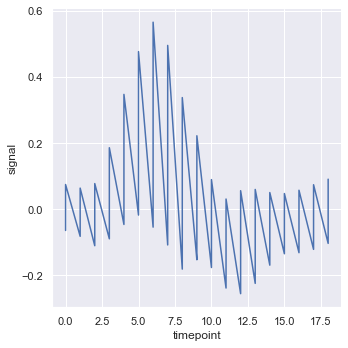
设置estimator=None参数可以关闭聚合
sns.relplot(x="timepoint", y="signal", estimator=None, kind="line", data=fmri);
2. 数据分布图
seaborn 提供 histplot(),kdeplot(),ecdfplot()和rugplot()函数,分别绘制直方图、核密度估计图、经验累积分布图和垂直刻度。
分布图的通用函数是displot(),通过指定kind来绘制不同的图:
kind="hist"(默认)等价于histplot()kind="kde"等价于kdeplot()kind="ecdf"等价于ecdfplot()
由于rugplot()只是用来标识刻度,它不需要kind指定,而是通过rug=True或rug=False(默认)来指定是否需要显示在图形中。
2.1 直方图
直方图是比较常见的数据分布图,它的绘制也很简单。
sns.displot(penguins, x="flipper_length_mm")
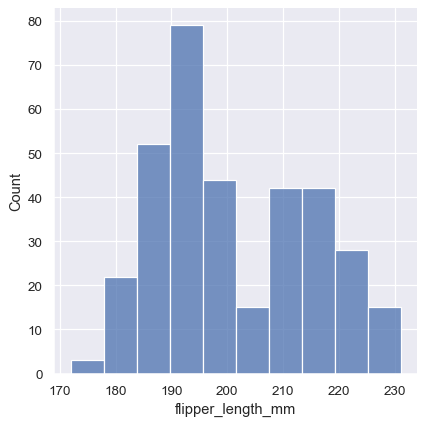
seaborn 提供了binwidth、bins等参数设置直方图 bin 的宽度和数量,从而绘制不同形状的直方图。
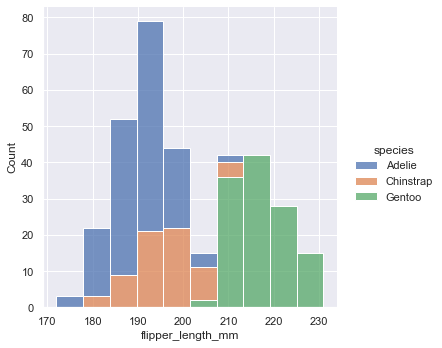
这里也可以设置hue参数,用不同颜色在一张图里绘制不同类别的直方图。当在一张图里绘制多个直方图时,需要设置element和multiple参数来指定多个直方图的组合方式。
如:multiple="stack"代表堆叠显示。
sns.displot(penguins, x="flipper_length_mm", hue="species", multiple="stack")
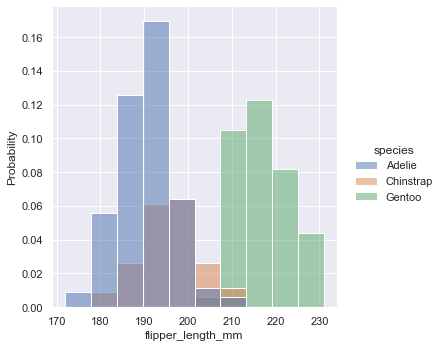
设置stat参数可以归一化直方图。如:设置stat="probability"可以使条形高度的和为1。
sns.displot(penguins, x="flipper_length_mm", hue="species", stat="probability")
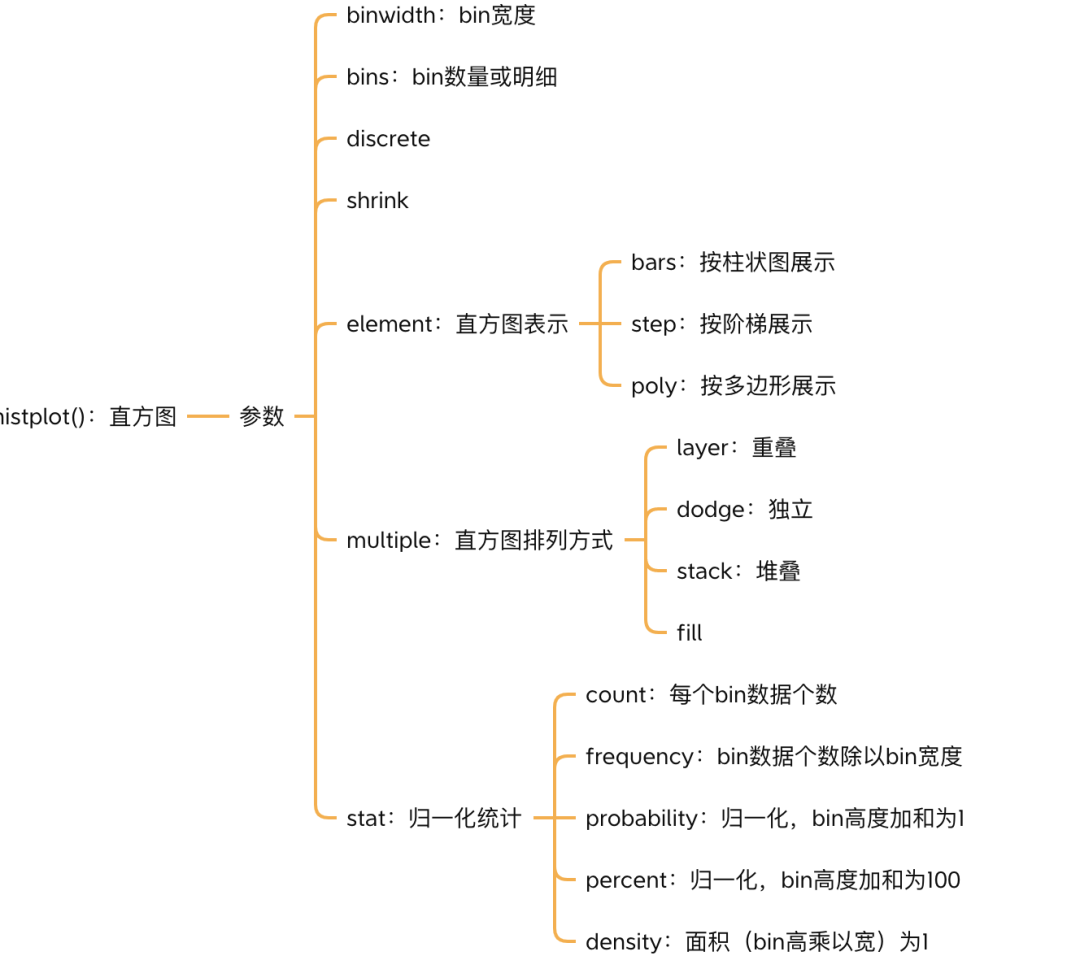
以下是直方图常见的参数及取值
2.2 核密度估计图
直方图的目的是通过分箱和计数观察来近似生成数据的潜在概率密度函数。核密度估计 (KDE) 是为这一问题提供了不同的解决方案。
sns.displot(penguins, x="flipper_length_mm", kind="kde")
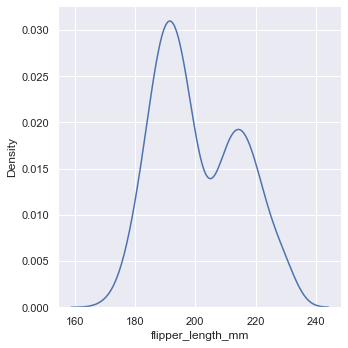
seaborn 从0.11.0版本开始只支持高斯核函数。
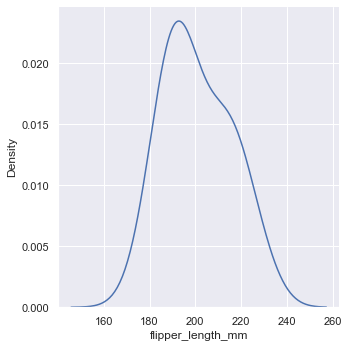
设置bw_adjust参数可以让 KDE 图更平滑。
sns.displot(penguins, x="flipper_length_mm", kind="kde", bw_adjust=2)
设置kde=True而不是kind="kde",可以同时绘制直方图和 KDE 图。
sns.displot(penguins, x="flipper_length_mm", kde=True)
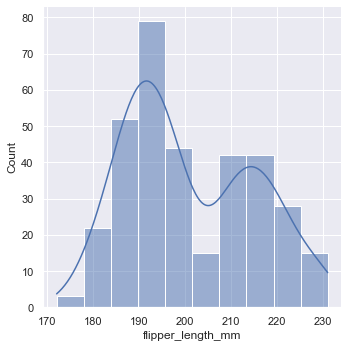
2.3 经验累积分布图
经验累积分布函数(ECDF) 通过每个数据点绘制了一条单调递增的曲线,使得曲线的高度反映了具有较小值的观测值的比例。
sns.displot(penguins, x="flipper_length_mm", hue="species", kind="ecdf")
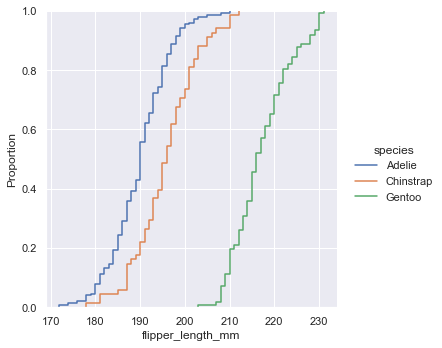
2.4 二元分布图
之前绘制的都是单变量分布图,seaborn 也可以绘制两个变量的分布图。
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm")
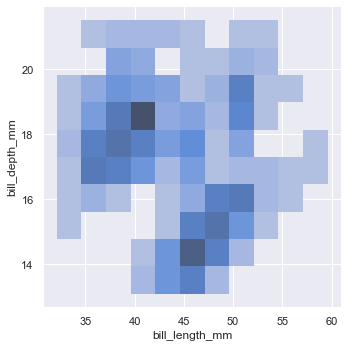
用平面图来展示二元直方图只能通过每个方块的颜色深浅定性观察数据的多少。
同样的,也可以绘制二元核密度估计图,画出来的图形是等高线。
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm", kind="kde")
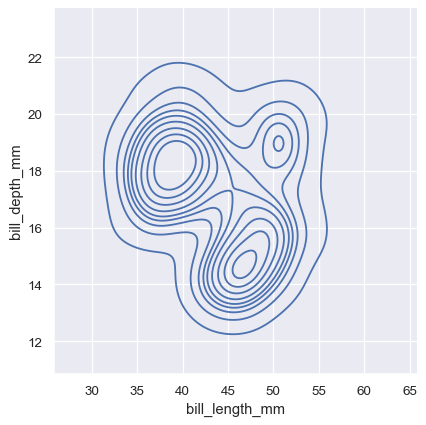
设置fill=True,可以通过颜色定性观察面的高度。
seaborn 还提供了 jointplot() 函数为二元变量同时绘制不同图形。
sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm")
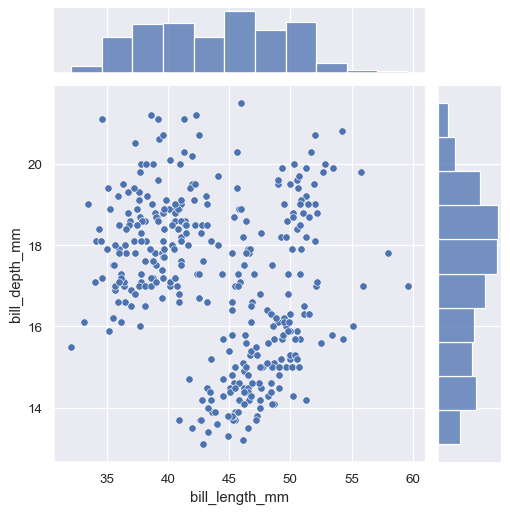
jointplot()默认绘制两变量散点图和单变量直方图。
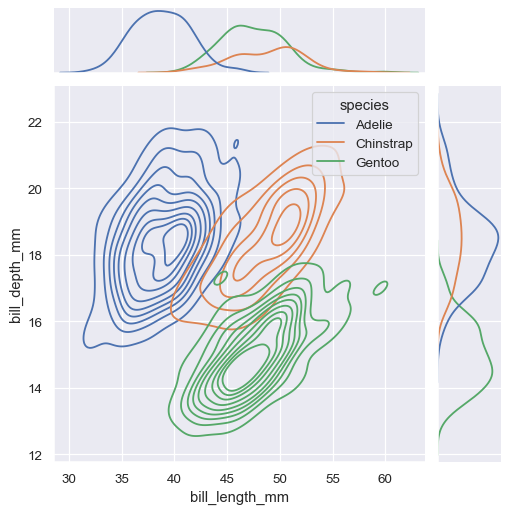
设置kind=kde来绘制 KDE 图。
sns.jointplot(
data=penguins,
x="bill_length_mm", y="bill_depth_mm", hue="species",
kind="kde"
)
seanborn 还提供了pairplot()函数,为更多变量绘图。
sns.pairplot(penguins)
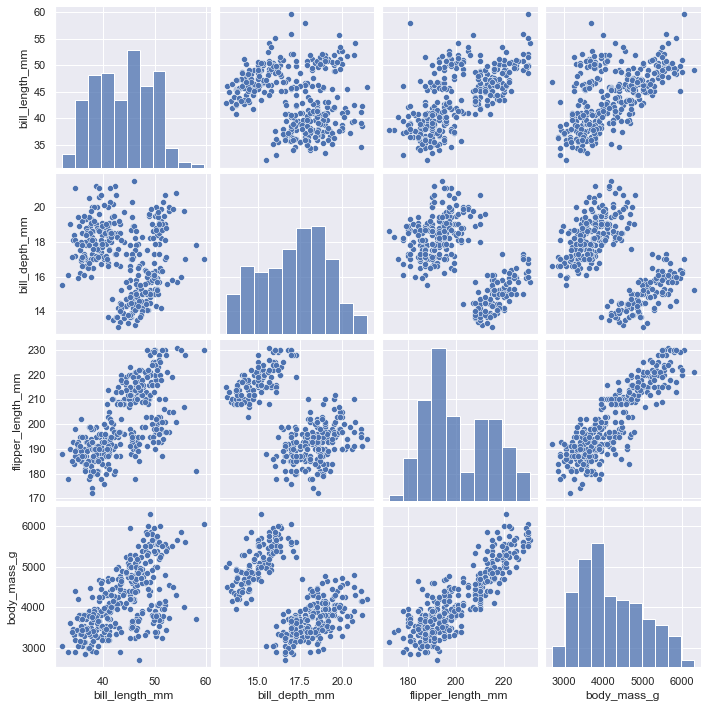
默认绘图仍然是直方图和散点图。同样可以设置kind=kde绘制多变量 KDE 图。
3. 分类图
之前我们绘制的关系图都是数值变量,当数据中有类别数据(离散值)时,就需要用分类图来绘制。
seaborn 提供 catplot() 函数来绘制分类图,有以下3种类别
分类散点图
kind="strip"(默认)等价于stripplot()kind="swarm"等价于swarmplot()分类分布图
kind="box"等价于boxplot()kind="violin"等价于violinplot()kind="boxen"等价于boxenplot()分类估计图
kind="point"等价于pointplot()kind="bar"等价于barplot()kind="count"等价于countplot()
3.1 分类散点图
catplot()默认使用stripplot()绘图,它会用少量随机"抖动"调整分类轴上的点位置,避免所有的点都重叠在一起。
tips = sns.load_dataset("tips", data_home='seaborn-data', cache=True)
sns.catplot(x="day", y="total_bill", data=tips)
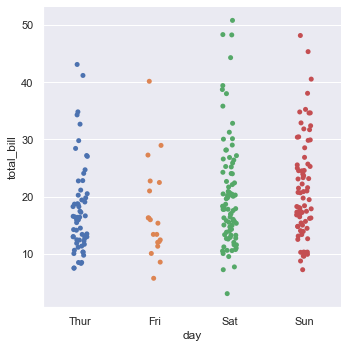
设置jitter参数可以控制抖动的幅度,当jitter=False时,代表不抖动,绘制出的图形跟使用关系散点图是一样的。
sns.catplot(x="day", y="total_bill", jitter=False, data=tips)
等价于
sns.relplot(x="day", y="total_bill", data=tips)
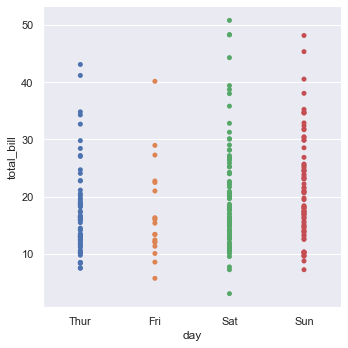
可以看到,图上的xy坐标相同的数据重合在一起,非常不方便观察。
虽然jitter可以设置“抖动”,但也有可能造成数据重叠。而kind="swarm"可以绘制非重叠的分类散点图。
sns.catplot(x="day", y="total_bill", kind="swarm", data=tips)
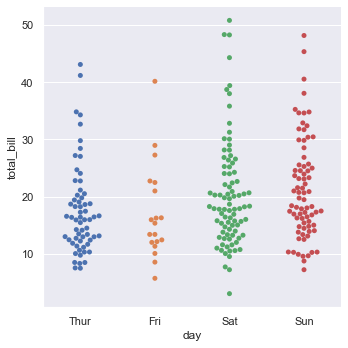
3.2 分类分布图
kind="box" 可以绘制箱线图。
sns.catplot(x="day", y="total_bill", kind="box", data=tips)
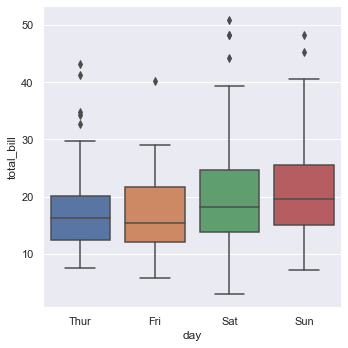
kind="boxen" 可以绘制增强箱线图。
diamonds = sns.load_dataset("diamonds", data_home='seaborn-data', cache=True)
sns.catplot(x="color", y="price", kind="boxen", data=diamonds.sort_values("color"))
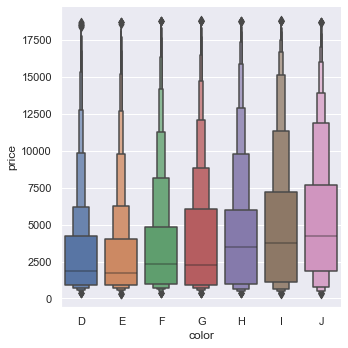
kind="violin" 可以绘制小提琴图。
sns.catplot(x="day", y="total_bill", hue="sex", kind="violin", split=True, data=tips)
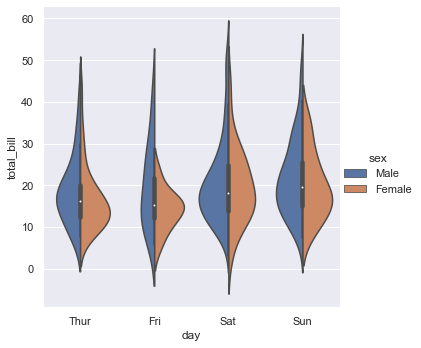
3.3 分类估计图
kind="bar" 以矩形条的方式展示数据点估值(默认取平均值)和置信区间,该置信区间使用误差线绘制。
titanic = sns.load_dataset("titanic", data_home='seaborn-data', cache=True)
sns.catplot(x="sex", y="survived", hue="class", kind="bar", data=titanic)
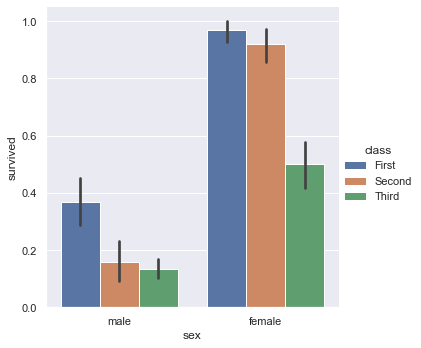
矩形条的高度是survived列均值,上面的那根天线就是误差线。
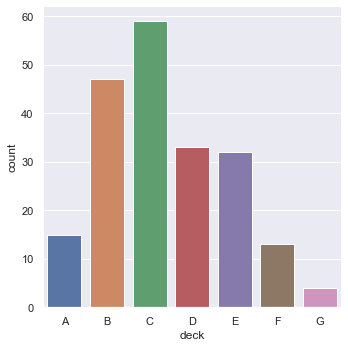
kind="count" 是常见的柱状图,统计x坐标对应的数据量。
sns.catplot(x="deck", kind="count", data=titanic)
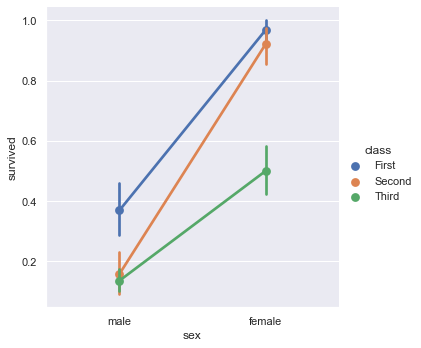
kind="point" 绘制点图,展示数据点的估计值(默认平均值)和置信区间,并连接来自同一hue类别的点。
sns.catplot(x="sex", y="survived", hue="class", kind="point", data=titanic)
4. 回归图
seaborn 提供线性回归函数对数据拟合,包括regplot()和lmplot(),它俩大部分功能是一样的,只是输入的数据和输出图形稍有不同。
用lmplot()函数可以绘制两个变量x、y的散点图,拟合回归模型并绘制回归线和该回归的 95% 置信区间。
tips = sns.load_dataset("tips")
sns.lmplot(x="total_bill", y="tip", data=tips);
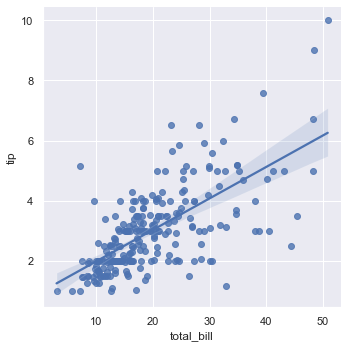
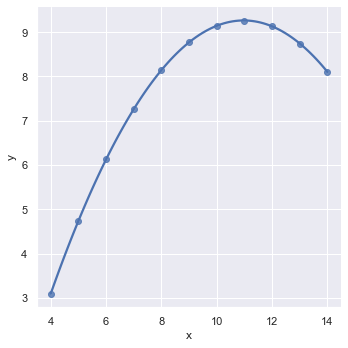
设置order参数可以拟合多项式回归模型
anscombe = sns.load_dataset("anscombe", data_home='seaborn-data', cache=True)
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"), order=2);
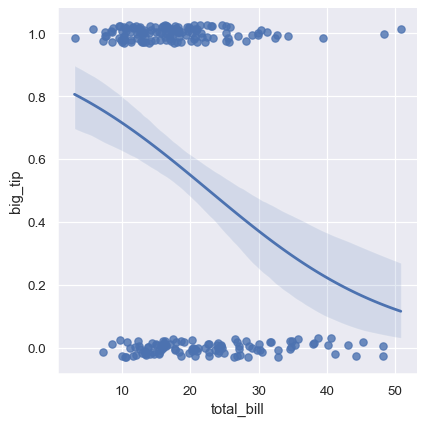
设置logistic=True参数可以拟合逻辑回归模型
sns.lmplot(x="total_bill", y="big_tip", data=tips, logistic=True, y_jitter=.03);
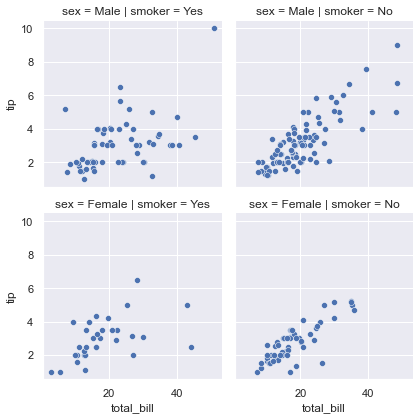
5. 多图网格
seaborn 提供了FacetGrid类可以同时绘制多图。
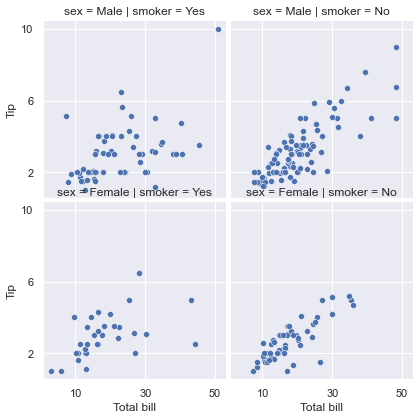
g = sns.FacetGrid(tips, row="sex", col="smoker")
g.map(sns.scatterplot, "total_bill", "tip")
实际上它等价于下面这段代码
sns.relplot(x='total_bill', y='tip', row="sex", col="smoker", data=tips)
当然用FaceGrid的好处是可以像 matplotlib 那样设置很多图形属性。
g = sns.FacetGrid(tips, row="sex", col="smoker")
g.map(sns.scatterplot, "total_bill", "tip")
g.set_axis_labels("Total bill", "Tip")
g.set(xticks=[10, 30, 50], yticks=[2, 6, 10])
g.figure.subplots_adjust(wspace=.02, hspace=.02)
另外,seaborn 还提供了PairGrid,可以为多变量同时绘图,且图形种类可以不同。
iris = sns.load_dataset("iris", data_home='seaborn-data', cache=True)
g = sns.PairGrid(iris)
g.map_upper(sns.scatterplot)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3, legend=False)
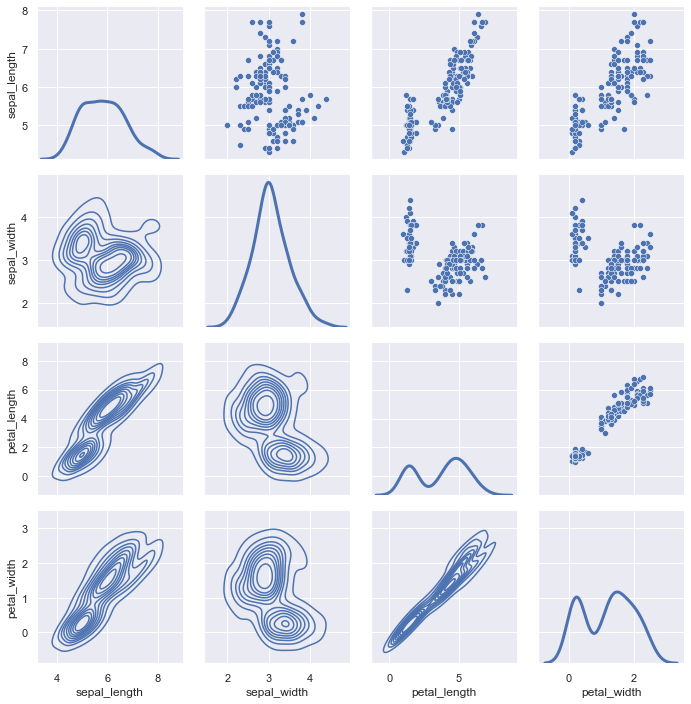
上图中,对角线以及对角线下方是 KDE 图,对角线上方是散点图。
6. 样式和调色板
这部分主要是对图表外观的设置,感兴趣的朋友可以自行尝试。
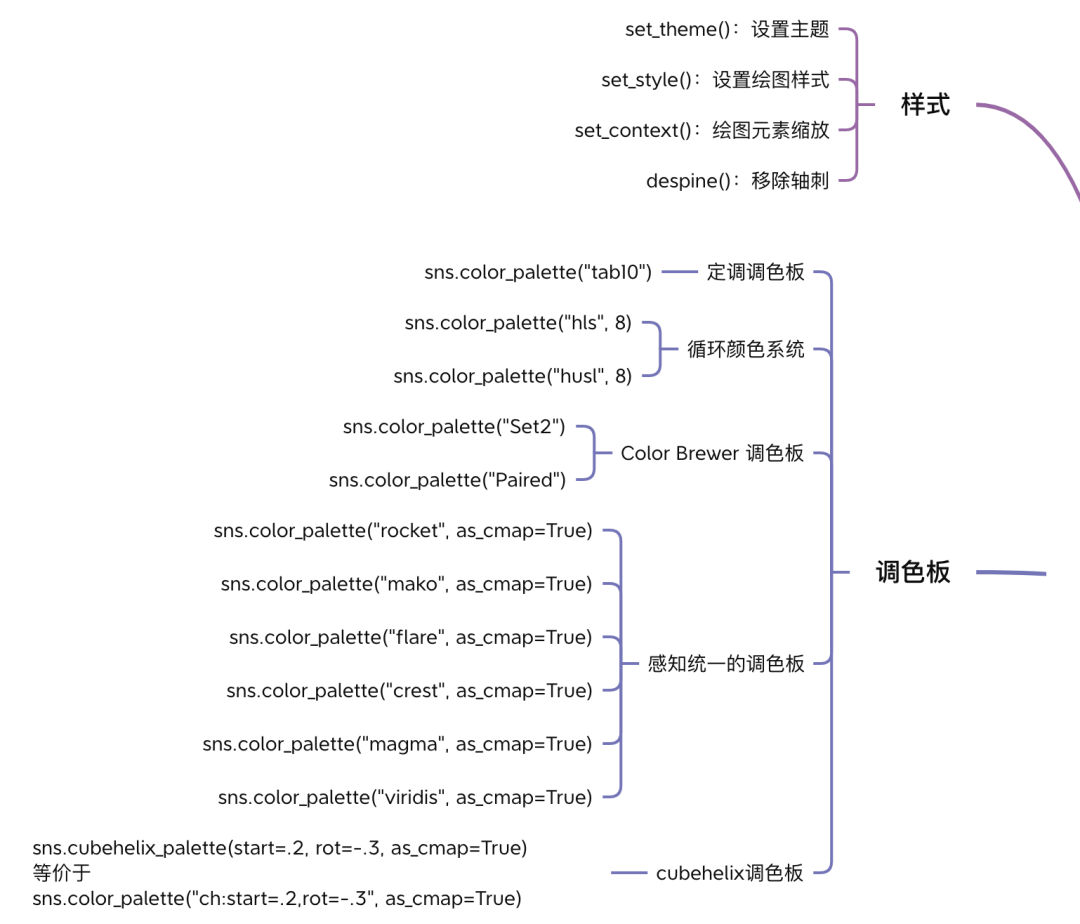
到这里,seaborn 的核心知识点就已经介绍完了,完整的思维导图在公众号回复seaborn全解获取。
如果本文对你有用就点个 在看 鼓励一下吧。
相关阅读: