
best,best,best ......何恺明开挂之路
别人的荣誉都是在某某大厂工作,拿过什么大奖,而何恺明的荣誉是best,best,best ......,裂开了

研究兴趣
据我观察,何恺明的研究兴趣大致分成这么几个阶段:
传统视觉时代:Haze Removal(3篇)、Image Completion(2篇)、Image Warping(3篇)、Binary Encoding(6篇)
深度学习时代:Neural Architecture(11篇)、Object Detection(7篇)、Semantic Segmentation(11篇)、Video Understanding(4篇)、Self-Supervised(8篇)
代表作
2009 CVPR best paper Single Image Haze Removal Using Dark Channel Prior
利用实验观察到的暗通道先验,巧妙的构造了图像去雾算法。现在主流的图像去雾算法还是在Dark Channel Prior的基础上做的改进。
2016 CVPR best paper Deep Residual Learning for Image Recognition
通过残差连接,可以训练非常深的卷积神经网络。不管是之前的CNN,还是最近的ViT、MLP-Mixer架构,仍然摆脱不了残差连接的影响。
2017 ICCV best paper Mask R-CNN
在Faster R-CNN的基础上,增加一个实例分割分支,并且将RoI Pooling替换成了RoI Align,使得实例分割精度大幅度提升。虽然最新的实例分割算法层出不穷,但是精度上依然难以超越Mask R-CNN。
2017 ICCV best student paper Focal Loss for Dense Object Detection
构建了一个One-Stage检测器RetinaNet,同时提出Focal Loss来处理One-Stage的类别不均衡问题,在目标检测任务上首次One-Stage检测器的速度和精度都优于Two-Stage检测器。近些年的One-Stage检测器(如FCOS、ATSS),仍然以RetinaNet为基础进行改进。
2020 CVPR Best Paper Nominee Momentum Contrast for Unsupervised Visual Representation Learning
19年末,NLP领域的Transformer进一步应用于Unsupervised representation learning,产生后来影响深远的BERT和GPT系列模型,反观CV领域,ImageNet刷到饱和,似乎遇到了怎么也跨不过的屏障。就在CV领域停滞不前的时候,Kaiming He带着MoCo横空出世,横扫了包括PASCAL VOC和COCO在内的7大数据集,至此,CV拉开了Self-Supervised研究新篇章。
近期工作
62-Exploring Simple Siamese Representation Learning
65-Masked Autoencoders Are Scalable Vision Learners
NLP和CV的双子星,注入Mask的预训练模型BERT和MAE
时间线
1-Single Image Haze Removal Using Dark Channel Prior

kaiming he通过大量无雾图片统计发现了dark channel prior—在无雾图的局部区域中,3个通道的最小亮度值非常小接近于0(不包括天空区域)。
dark channel prior通过暗通道先验对haze imaging model进行化简,近似计算得到粗糙的transmission,然后将haze imaging model和matting model联系起来,巧妙的将图像去雾问题转化为抠图问题,得到refined transmission,精彩!
何恺明经典之作—2009 CVPR Best Paper | Dark Channel Prior
3-Guided Image Filtering
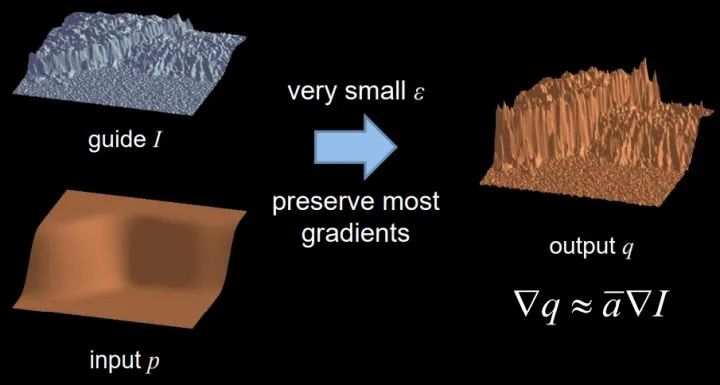
Guided image filtering是结合两幅图片信息的过程,一个filtering input image(表示为p)和一个guide image(表示为I)生成一个filtering output image(表示为q)。p决定了q的颜色,亮度,和色调,I决定了q的边缘。对于图像去雾来说,transmission就是p,雾图就是I,refined transmission就是q。
guided filter则通过公式转换,和滤波联系起来,提出新颖的guided filter,巧妙的避开了linear system的计算过程,极大加快了transmission优化的速度。
何恺明经典之作—2009 CVPR Best Paper | Dark Channel Prior
37-Focal Loss for Dense Object Detection
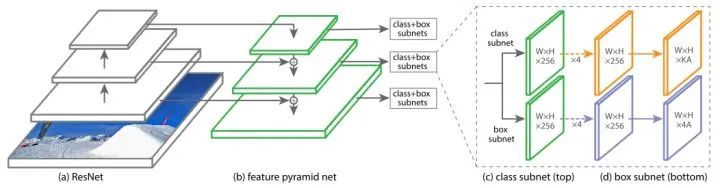
构建了一个One-Stage检测器RetinaNet,同时提出Focal Loss来处理One-Stage的类别不均衡问题,在目标检测任务上首次One-Stage检测器的速度和精度都优于Two-Stage检测器。近些年的One-Stage检测器(如FCOS、ATSS),仍然以RetinaNet为基础进行改进。
38-Mask R-CNN
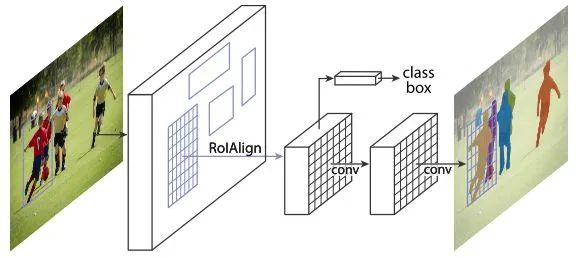
在Faster R-CNN的基础上,增加一个实例分割分支,并且将RoI Pooling替换成了RoI Align,使得实例分割精度大幅度提升。虽然最新的实例分割算法层出不穷,但是精度上依然难以超越Mask R-CNN。
62-Exploring Simple Siamese Representation Learning
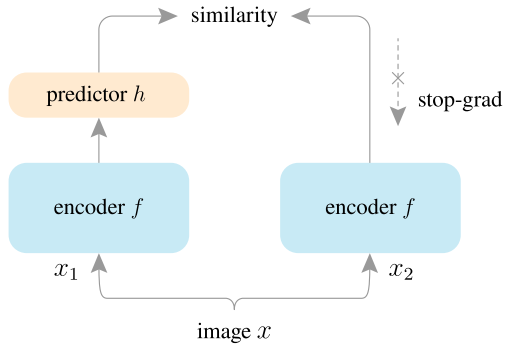
SimSiam的理论解释意味着带stop-gradient的孪生网络表征学习都可以用EM算法解释。stop-gradient起到至关重要的作用,并且需要一个预测期望E的方法进行辅助使用。但是SimSiam仍然无法解释模型坍塌现象,SimSiam以及它的变体不坍塌现象仍然是一个经验性的观察,模型坍塌仍然需要后续的工作进一步讨论。
63-A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
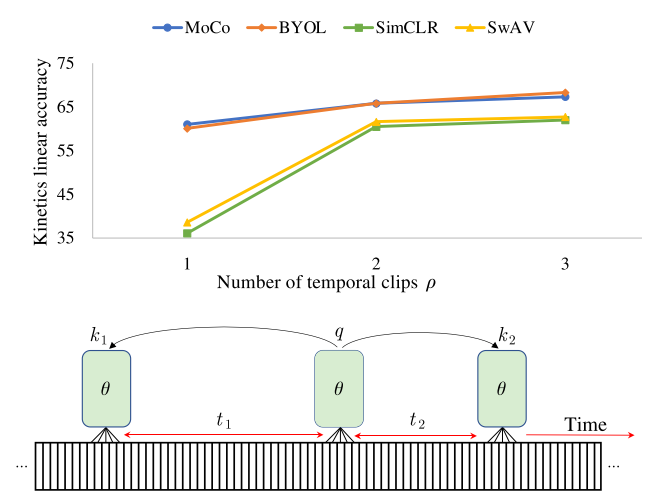
指出时空的Self-Supervised采样同一个视频的positive pair时间跨度越长效果越好,momentum encoder比优化目标重要,训练时间、backbone、数据增强和精选数据对于得到更好性能至关重要。
何恺明+Ross Girshick:深入探究无监督时空表征学习
64-An Empirical Study of Training Self-Supervised Vision Transformers
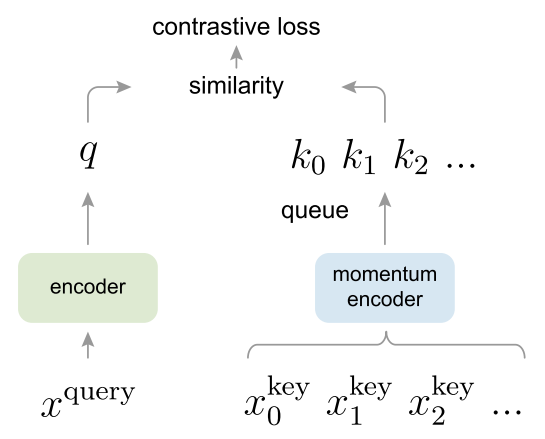
MoCov1通过dictionary as a queue和momentum encoder和shuffle BN三个巧妙设计,使得能够不断增加K的数量,将Self-Supervised的威力发挥的淋漓尽致。MoCov2在MoCov1的基础上,增加了SimCLR实验成功的tricks,然后反超SimCLR重新成为当时的SOTA,FAIR和Google Research争锋相对之作,颇有华山论剑的意思。MoCov3通过实验探究洞察到了Self-Supervised+Transformer存在的问题,并且使用简单的方法缓解了这个问题,这给以后的研究者探索Self-Supervised+Transformer提供了很好的启示。
65-Masked Autoencoders Are Scalable Vision Learners
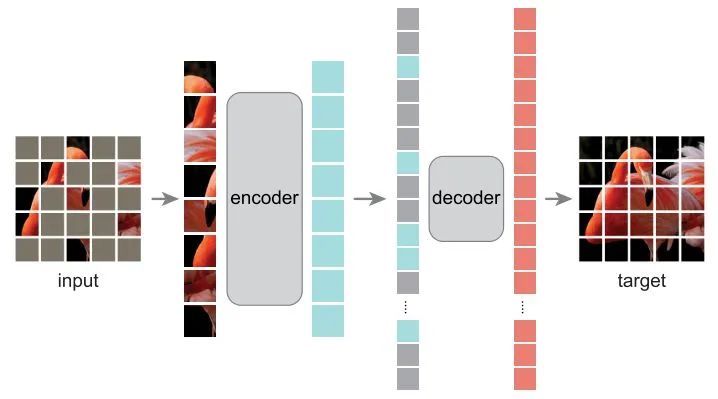
MAE设计了一个encoder-decoder预训练框架,encoder只送入image token,decoder同时送入image token和mask token,对patch序列进行重建,最后还原成图片。相比于BEiT,省去了繁琐的训练tokenizer的过程,同时对image token和mask token进行解耦,特征提取和图像重建进行解耦,encoder只负责image token的特征提取,decoder专注于图像重建,这种设计直接导致了训练速度大幅度提升,同时提升精度,真称得上MAE文章中所说的win-win scenario了。
NLP和CV的双子星,注入Mask的预训练模型BERT和MAE
kaiming科研嗅觉顶级,每次都能精准的踩在最关键的问题上,提出的方法简洁明了,同时又蕴含着深刻的思考,文章赏心悦目,实验详尽扎实,工作质量说明一切。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 机器学习在线手册 深度学习笔记专辑 《统计学习方法》的代码复现专辑 AI基础下载 本站qq群955171419,加入微信群请扫码: